
AI API 中转全指南:选型标准、架构设计与安全合规落地
AI API 中转全指南:选型标准、架构设计与安全合规落地#
Your app can run fine in staging and still break in production: one upstream timeout plus a 600 requests/min ceiling can turn normal traffic into 429 and 500 errors fast. Teams hit this wall after wiring OpenAI, Anthropic, and Google APIs one by one, then discovering that model switching, key rotation, logging, and billing checks now live in three separate places.
That is where AI API 中转 changes the design goal. Treat it as a traffic and governance layer, not a simple proxy. You route requests across 300+ models through one OpenAI-compatible endpoint, apply retry and failover rules, and keep one policy surface for auth, rate limits, and audit logs. Cost is part of architecture too: some gateways publish prices 30-50% below official APIs, so routing policy can reduce unit cost without changing app logic. Reliability also has a hard target, like a 99.9% SLA, so your fallback plan is tied to uptime, not guesswork.
You will get a practical path to choose providers, design weighted routing and fault handling, and ship security controls that stand up in real audits. Start with the selection standard, because a weak provider fit will break every later decision.
What AI API Relay Means: From “Call Forwarding” to a Governance Hub#
AI API relay definition and boundary#
People often treat an API relay as a simple pass-through. That view is too narrow. An AI API relay is a control layer: one entry point, policy-based routing, and unified governance across providers.
A reverse proxy mainly forwards traffic. An AI API relay also decides where requests go, how retries work, which model is allowed, and how usage is recorded. A model platform builds and serves models. The relay sits above it and manages access to multiple model platforms.
| Layer | Main job | Typical scope |
|---|---|---|
| Reverse proxy | Forward requests | Basic network routing |
| AI API relay | Route + govern + observe | Auth, rate limits, failover, logs, billing rules |
| Model platform | Train/host models | Inference capacity and model lifecycle |
Source: Crazyrouter product/API docs (OpenAI-compatible endpoint, multi-provider support).
Why AI API relay matters more in 2026#
Model choices keep expanding, and versions change fast. If your app connects to each provider directly, every model switch can force code changes, key rotation, and policy drift.
With a relay, you keep one OpenAI-compatible endpoint (https://crazyrouter.com/v1) and one SDK pattern. You can route across OpenAI, Anthropic, Google, and other providers from one surface, including 300+ models in one catalog. This also supports risk hedging: if one upstream fails, traffic can move by retry/failover rules tied to uptime targets like 99.9% SLA.
What an AI API relay can and cannot solve#
A relay can cut integration drag, centralize observability, enforce limits, and support controlled switching. Real examples include free-tier rate limits at 60 requests/minute and paid-tier limits at 600 requests/minute under one policy model.
It cannot fix weak prompts, poor product UX, or unclear business logic. If your prompt design is unstable, routing alone will not save output quality.
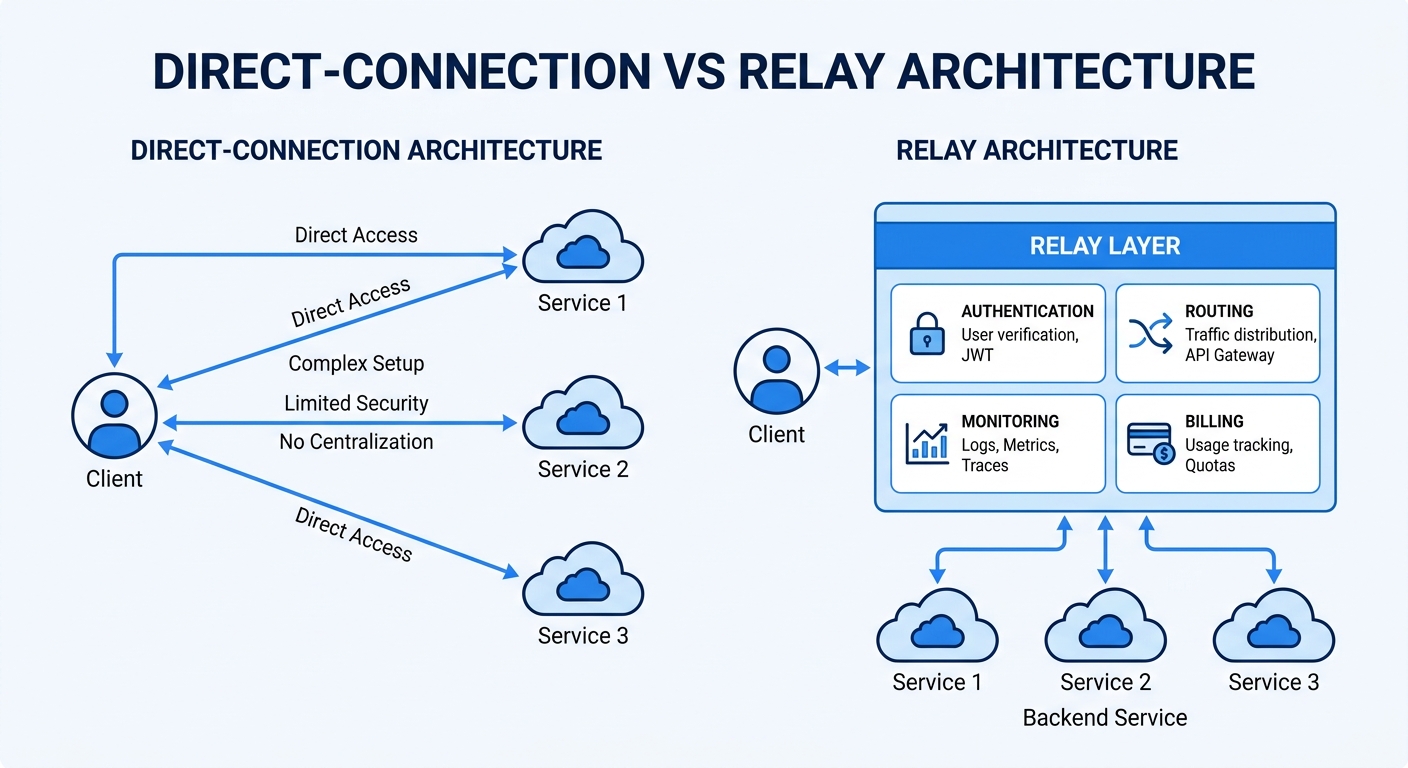
You can use Crazyrouter as this relay layer: keep app code close to OpenAI SDK usage, then move control to routing and governance instead of hard-coded provider logic.
哪些团队最需要AI API 中转:四类高频业务场景#
This section covers: 读者将识别自身是否处在中转价值高区间,并据此判断投入优先级。
产品快速迭代团队:先跑通再优化#
最小可用接入与统一调用封装. 用中转层降低试错成本与迁移成本
中大型企业:多部门共享模型能力#
按部门分账与配额管理. 权限分级与审计追踪
出海与跨区域业务:高可用与低延迟并重#
地域路由与多上游容灾. 网络波动下的降级策略
AI API 中转技术架构:统一入口、智能路由与可观测性#
Treat AI API 中转 as a control layer, not a forwarding script. You want one entry, one policy surface, and clear runtime signals before traffic grows. If you skip observability at design time, you will debug blind in production.
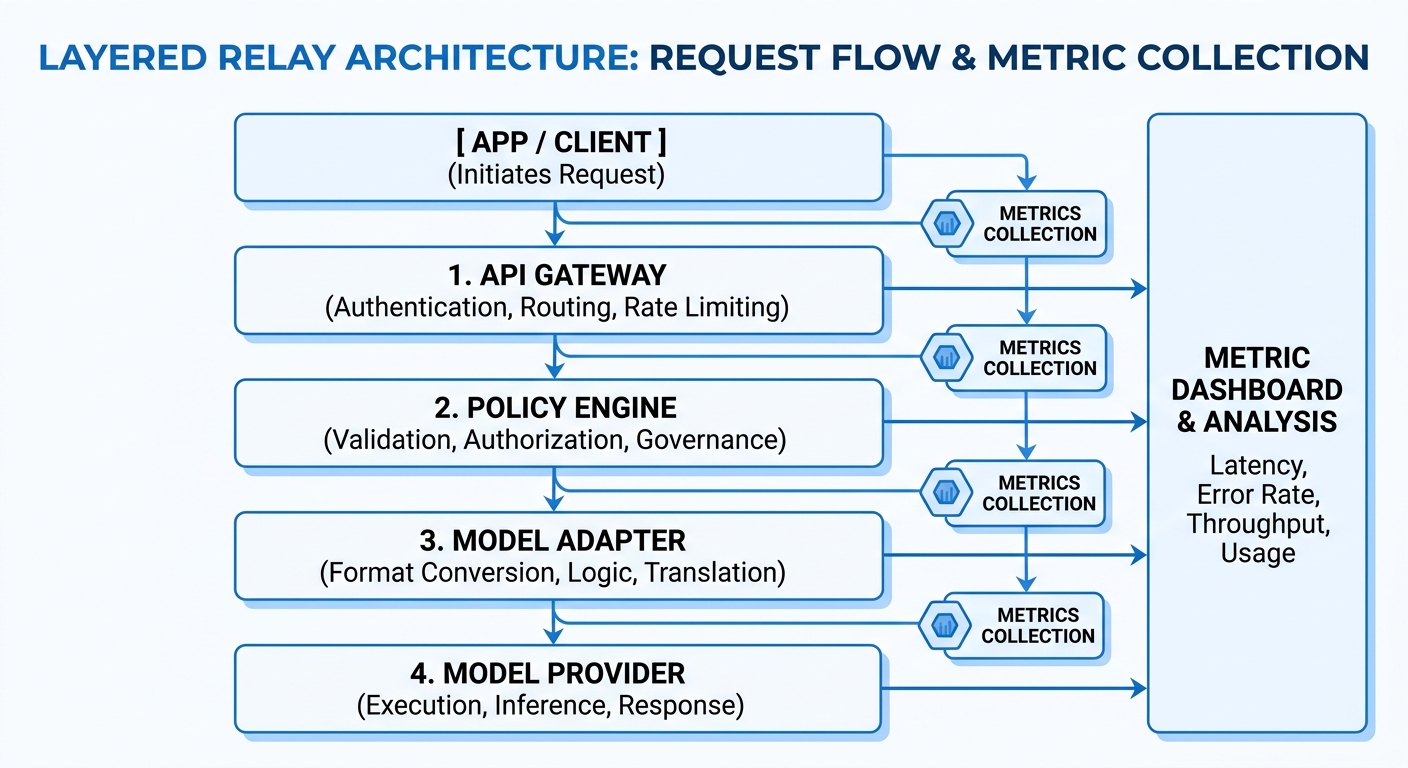
AI API relay architecture breakdown: how five layers work together#
Use a five-layer path:
- Entry gateway: receive all app calls at one OpenAI-compatible endpoint (
https://crazyrouter.com/v1), check auth header, and enforce rate limits. - Policy engine: apply model allowlists, user-level limits, retry rules, and cost routing rules.
- Model adapters: map one request format to upstream providers like OpenAI, Anthropic, and Google models.
- Log and metrics layer: record request ID, model, token usage, status code, and latency.
- Audit and alert layer: keep immutable action logs for key changes and trigger alerts on error spikes.
You can use Crazyrouter with existing OpenAI SDK code by changing base_url and API key only. That cuts migration work and lowers rollout risk.
AI API 中转 integration flow: dev to production#
Start in a sandbox project with one low-risk model route. Verify auth errors (401), rate-limit errors (429), and server errors (500) with forced test cases. Move to load testing next. Push request rate near your planned peak and watch queue time and timeout rate. Then run a small canary release. Shift a small traffic slice to the relay path and compare it with the old path on success rate and latency. Run failure drills before full launch: disable one upstream, verify automatic failover, and confirm rollback switches traffic back fast.
| Tier | API rate limit | What to validate before go-live |
|---|---|---|
| Free | 60 requests/minute | Retry behavior and backoff logic |
| Paid | 600 requests/minute | Burst handling and queue stability |
| Enterprise | Custom | Contracted SLO and alert routing |
Source: Crazyrouter API docs (/v1 reference and rate limits).
AI API 中转 monitoring metrics and alert thresholds#
Track three core signals in one dashboard: success rate, time to first token, and cost per 1,000 calls. For cost, compute from token usage and model price; routing can reduce unit cost when a gateway offers 30-50% lower pricing than official APIs. Set dynamic thresholds from your own baseline, then alert on sudden deviation, not raw noise. Add automatic throttling on abnormal traffic peaks to protect upstream quotas and keep service stable.
Cost and Stability Dual Optimization: Avoid “Lower Unit Price, Higher System Loss”#
Treat an AI API relay as a cost-and-risk system, not a cheaper endpoint. You can cut request price, then lose more money in downtime, pager fatigue, and slow responses. The right decision metric is total cost of ownership (TCO), not token price alone.
AI API relay TCO model: count visible and hidden costs together#
Visible cost is easy: token billing and monthly spend. Hidden cost is where teams get burned: on-call hours, failed retries, and user-facing latency during upstream issues.
| Cost item | What to measure | Example data you can verify |
|---|---|---|
| API unit price | Input/output token spend | Some gateways list prices 30-50% below official APIs |
| Traffic limits | Requests per minute by tier | 60 RPM free, 600 RPM paid |
| Reliability target | Contracted uptime | 99.9% SLA |
| Engineering overhead | Time spent on failover, routing, SDK migration | OpenAI SDK migration can be just base URL + API key change |
| Failure loss | Revenue or task loss during outage/slowdown | Track by incident minutes and affected requests |
Source: Crazyrouter Core/Product.md and Domain/API.md.
If you only compare token price, you miss the true bill. A provider with lower price but weak failover can cost more by week two.
AI API relay stability policy: rate limit, circuit break, retry, degrade#
Set controls by business priority. Payment, chat support, and internal summarization should not share one retry policy.
Use this pattern:
- Rate limit per app and per token key to stop burst damage.
- Circuit break after repeated upstream errors.
- Retry with exponential backoff on 429 and transient 5xx.
- Degrade to a cheaper or smaller model for non-core tasks.
- Auto-switch upstream when health checks fail.
<.-- IMAGE: Stability flow from normal -> alert -> degrade -> recover -->
You can use one OpenAI-compatible endpoint and route across 300+ models, while keeping one policy surface for auth, logs, and limits.
AI API relay billing transparency and budget governance#
Split spend by app, team, and model. This makes blame and planning clear. Set budget thresholds with two actions:
- Alert at soft limit.
- Block or force fallback model at hard limit.
This keeps finance and engineering aligned. You stop surprise invoices and avoid emergency rewrites at month end.
安全与合规:AI API 中转上线前必须完成的风控清单#
This section covers: 读者将获得一套可执行的安全治理框架,覆盖密钥、权限、审计与数据合规。
密钥与权限治理:最小权限原则落地#
分环境密钥隔离与周期轮换. 按人、按应用、按场景授权
审计与异常检测:把风险前置到日常运营#
访问日志留存、异常调用识别. 高风险操作双重确认与告警闭环
团队协作中的账号安全实践#
多账号隔离、设备环境隔离与权限分层. 离职交接与外包协作的访问回收机制
选型实操:30天落地路线图与供应商评估表#
This section covers: 读者将拿到可直接执行的选型与上线步骤,减少试错周期。
供应商评估八项指标与权重建议#
可用性、性能、计费透明度、生态支持. 安全能力、合规支持、服务响应、扩展性
30天落地计划:调研、试点、灰度、复盘#
第1周需求与基线,第2周接入与压测. 第3周灰度与告警优化,第4周全量与复盘
Frequently Asked Questions#
AI API 中转和直接调用模型接口相比,最大的差异是什么?#
最大差异不是“少写几行代码”,而是统一治理能力。AI API 中转把多模型调用放到同一控制面:按成本和质量做路由,按团队和应用做权限,按项目做分账,按接口做监控与告警。你还能配置熔断、限流和故障切换。直接调用时,这些能力常常分散在各服务里,维护难、排障慢、责任边界不清。
中小团队是否有必要尽早部署 AI API 中转?#
可以用四个阈值判断是否该上:接入模型达到 3 个以上;日调用量到万级;协作成员超过 5 人;出现合规或审计要求。满足其中两到三项,就值得尽早部署 AI API 中转。越早统一网关,越容易建立标准日志、鉴权和计费规则,避免后期“边跑边补”造成重复改造和线上风险。
如何评估 AI API 中转平台的稳定性是否真实可靠?#
先看可用性承诺是否写进 SLA,并明确赔付规则。再看历史故障披露:是否公开故障时间线、根因和修复动作。第三看压测报告:峰值并发、限流策略、降级路径是否清楚。第四看切换时延:主备切换和模型路由切换是否在秒级完成。看告警机制:是否支持多通道告警、值班升级和自动化处置闭环。
AI API 中转会不会增加数据泄露风险?#
会有新增链路,但风险可控,关键在落地安全基线。你需要做到:上游与下游密钥隔离,传输全程 TLS,加密存储敏感配置,日志默认脱敏,权限按最小授权发放,并保留完整审计追踪。AI API 中转平台还应支持 IP 白名单、签名校验和过期令牌。这样即使单点暴露,也能快速定位、封禁和回滚。
迁移到 AI API 中转时,如何避免业务中断?#
采用“先并行、再切流”的节奏最稳妥。第一步做双路并行:旧链路继续服务,新链路镜像流量验证结果。第二步灰度发布:按用户组或地域逐步放量。第三步设置自动回滚:当错误率、时延或成本指标越线时立即切回旧链路。分阶段切流:先低风险接口,再核心接口,并在每阶段做对账和回归测试。
The real value of an AI API relay is not just unified access, but measurable gains in reliability, routing flexibility, cost governance, and compliant operations under production traffic. Use a scoring framework and side-by-side pressure tests to validate latency, stability, and failover behavior before committing to one stack: 下载选型评分表与30天落地清单,先完成三家平台对比压测,再决定你的AI API 中转方案。


