
"토큰 vs 바이트: AI가 실제로 텍스트를 처리하는 방식 완벽 해설"
토큰 vs 바이트: AI가 실제로 텍스트를 처리하는 방식 완벽 해설#
GPT-5에 "안녕하세요 Hello"라고 입력한다고 생각해 보세요. 눈에 보이는 글자는 10자인데, 모델은 이것을 2개의 토큰으로 처리합니다. 그리고 과금 기준은 글자 수가 아니라 바로 이 토큰 수입니다.
한편, 컴퓨터는 같은 텍스트를 20바이트로 저장합니다.
그렇다면 바이트, 문자, 토큰의 차이는 정확히 무엇일까요? AI는 왜 원시 바이트 대신 토큰을 사용할까요? 같은 내용인데 왜 한국어가 영어보다 더 비쌀까요?
이 글에서는 하드디스크에 저장되는 바이트부터, AI가 실제로 읽는 토큰까지 전체 파이프라인을 설명합니다.
가장 기본부터: 바이트(Byte)란 무엇인가?#
**바이트(byte)**는 컴퓨터가 데이터를 저장하는 가장 작은 단위입니다. 1바이트 = 8비트 = 0에서 255까지의 숫자 하나입니다.
텍스트를 파일로 저장할 때, 컴퓨터는 UTF-8이라는 인코딩 표준을 사용해 각 문자를 바이트로 변환합니다:
| Character | UTF-8 Bytes | Byte Count | Hex |
|---|---|---|---|
H | 72 | 1 | 48 |
e | 101 | 1 | 65 |
你 | 228, 189, 160 | 3 | e4 bd a0 |
好 | 229, 165, 189 | 3 | e5 a5 bd |
🚀 | 240, 159, 154, 128 | 4 | f0 9f 9a 80 |
핵심 패턴:
- 영어 알파벳: 문자당 1바이트
- 한중일(CJK) 문자: 문자당 3바이트
- 이모지: 문자당 4바이트
예를 들어 "你好 Hello"는 12바이트로 저장됩니다:
你 好 [space] H e l l o
e4 bd a0 e5 a5 bd 20 48 65 6c 6c 6f
(3 bytes) (3 bytes) (1) (1) (1) (1) (1) (1) = 12 bytes
바이트는 컴퓨터가 텍스트를 저장하는 방식입니다. 하지만 AI 모델은 바이트를 직접 읽지 않습니다.
네 가지 레벨: 바이트 → 문자 → 단어 → 토큰#
텍스트를 분해하는 방법에는 네 가지가 있습니다. 각 레벨은 데이터를 서로 다른 방식으로 그룹화합니다:
| Level | "Hello, World" | Count | Description |
|---|---|---|---|
| Bytes | 48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 | 12 | 원시 저장 단위 |
| Characters | H e l l o , ␣ W o r l d | 12 | 사람이 읽을 수 있는 글자 |
| Words | Hello, World | 2 | 공백으로 구분된 단위 |
| Tokens | Hello , World | 3 | AI가 실제로 처리하는 단위 |
같은 비교를 중국어로 해보겠습니다:
| Level | "你好世界" | Count | Description |
|---|---|---|---|
| Bytes | e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c | 12 | 문자당 3바이트 |
| Characters | 你 好 世 界 | 4 | 각 문자 = 하나의 한자 |
| Words | 你好 世界 | 2 | 의미 기반 분절 |
| Tokens | 你好 世界 | 2 | 토크나이저에 따라 다름 |
핵심 포인트: 토큰은 바이트도, 문자도, 단어도 아닙니다. 토큰은 어휘 크기와 시퀀스 길이의 균형을 맞추는 서브워드(sub-word) 단위입니다.
왜 바이트나 단어를 그대로 쓰지 않을까?#
바이트와 단어가 더 직관적인데, AI는 왜 굳이 토큰이라는 개념을 만들었을까요? 양 극단 모두 심각한 문제가 있기 때문입니다:
바이트의 문제: 시퀀스가 너무 길어진다#
"Hello"는 5바이트입니다. 1,000단어짜리 블로그 글은 ~5,000바이트, 소설 한 권은 ~500,000바이트가 됩니다.
AI 모델은 시퀀스 내 모든 위치 간의 관계를 처리해야 합니다. Attention 메커니즘의 연산 비용은 시퀀스 길이에 대해 이차적(O(n²))으로 증가합니다. 시퀀스 길이가 2배가 되면 → 연산 비용은 4배가 됩니다.
원시 바이트를 사용하면 시퀀스가 3~4배 불필요하게 길어져서, AI 모델이 감당할 수 없을 만큼 느려집니다.
단어의 문제: 어휘 크기가 폭발한다#
영어만 해도 일상적으로 사용되는 단어가 170,000개가 넘습니다. 여기에 전문 용어, 고유명사, URL, 코드, 다른 언어까지 포함하면 수백만 개의 어휘가 필요합니다.
거대한 어휘는 다음 문제를 만듭니다:
- 임베딩 테이블이 지나치게 커져 메모리를 많이 소비합니다
- 대부분의 단어가 희귀해서 모델이 제대로 학습하지 못합니다
- 어휘에 없는 단어는 아예 처리가 불가능합니다 (OOV, Out-of-Vocabulary 문제)
토큰: 최적의 균형점#
토큰은 텍스트를 서브워드 단위로 분할합니다. 바이트보다 크고 단어보다 작은 조각입니다:
"unbelievable" → ["un", "bel", "ievable"] (3 tokens)
"tokenization" → ["Token", "ization"] (2 tokens)
"Hello" → ["Hello"] (1 token — 자주 쓰이므로 통째로 유지)
이 방식의 장점:
- 짧은 시퀀스 (효율적인 처리)
- 작은 어휘 (
10만20만 엔트리, 수백만이 아닌) - 미지의 단어 없음 (어떤 텍스트든 알려진 서브워드로 분해 가능)
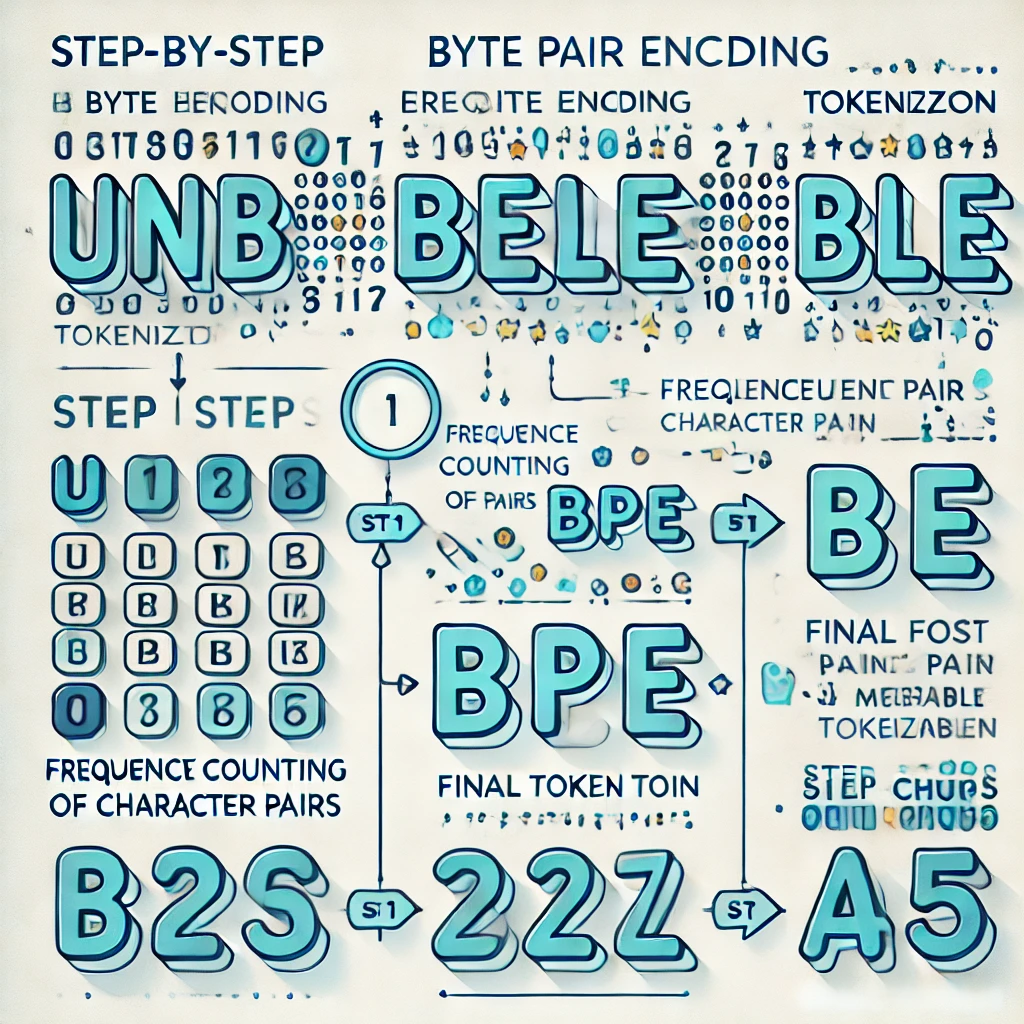
BPE 토크나이제이션의 실제 작동 원리#
대부분의 최신 LLM은 **Byte Pair Encoding (BPE)**의 변형을 사용해 토크나이저를 구축합니다. 구체적인 동작 방식은 다음과 같습니다:
1단계: 개별 문자로 시작#
학습 텍스트를 가져와서 모두 단일 문자로 분리합니다:
"low" → ["l", "o", "w"]
"lower" → ["l", "o", "w", "e", "r"]
"newest" → ["n", "e", "w", "e", "s", "t"]
2단계: 가장 빈번한 쌍 찾기#
모든 인접 문자 쌍을 조사하고 가장 많이 나타나는 쌍을 찾습니다:
("l", "o") appears 2 times ← 가장 빈번
("o", "w") appears 2 times
("e", "w") appears 1 time
...
3단계: 가장 빈번한 쌍 병합#
("l", "o")의 모든 등장을 새로운 토큰 "lo"로 치환합니다:
"low" → ["lo", "w"]
"lower" → ["lo", "w", "e", "r"]
4단계: 수천 번 반복#
목표 어휘 크기(보통 50K~200K 토큰)에 도달할 때까지 빈도 카운팅과 병합을 계속 반복합니다.
많은 병합을 거치면, "the", "Hello", "you" 같은 흔한 단어는 단일 토큰이 되고, 드문 단어는 서브워드 조각으로 분할됩니다.
tiktoken으로 직접 확인하기#
OpenAI의 tiktoken 라이브러리를 사용하면 GPT-5가 텍스트를 어떻게 토큰화하는지 정확히 확인할 수 있습니다:
import tiktoken
# o200k_base is used by GPT-4o and GPT-5
enc = tiktoken.get_encoding("o200k_base")
text = "你好 Hello"
tokens = enc.encode(text)
token_strings = [enc.decode([t]) for t in tokens]
print(f"Text: {text}")
print(f"UTF-8 bytes: {len(text.encode('utf-8'))}")
print(f"Tokens ({len(tokens)}): {token_strings}")
print(f"Token IDs: {tokens}")
실행 결과:#
Text: 你好 Hello
UTF-8 bytes: 12
Tokens (2): ['你好', ' Hello']
Token IDs: [177519, 32949]
12바이트가 단 2개의 토큰으로 압축되었습니다. 이것이 BPE의 위력입니다. 자주 사용되는 표현은 하나의 토큰으로 합쳐져, 시퀀스 길이를 극적으로 줄여줍니다.
모델마다 토크나이저가 다르다#
각 AI 모델 패밀리는 서로 다른 어휘를 가진 고유한 토크나이저를 사용합니다. 같은 텍스트라도 모델에 따라 토큰 수가 달라집니다:
| Text | cl100k_base (GPT-4) | o200k_base (GPT-4o/5) | UTF-8 Bytes |
|---|---|---|---|
| Hello, how are you today? | 7 | 7 | 25 |
| Explain quantum computing in simple terms | 7 | 6 | 41 |
| 你好,请用中文解释一下什么是token | 15 | 9 | 47 |
| こんにちは、トークンとは何ですか? | 12 | 10 | 51 |
| Python fibonacci function (5 lines) | 28 | 28 | 92 |
핵심 포인트: GPT-5의 토크나이저(o200k_base)는 중국어와 일본어에서 현저히 효율적입니다. 같은 중국어 문장이 GPT-4에서는 15토큰이지만 GPT-5에서는 9토큰밖에 되지 않습니다. 토크나이저만 바뀌어도 40%의 비용 절감이 가능한 것입니다.
Claude는 자체 토크나이저를 사용하고, Gemini는 SentencePiece를 사용합니다. 토큰 수는 프로바이더마다 다르므로, 같은 프롬프트라도 어떤 모델을 쓰느냐에 따라 비용이 달라집니다.
토큰 수가 요금에 미치는 영향#
AI API는 바이트나 단어가 아닌 토큰 단위로 과금됩니다. 그리고 언어에 따라 토큰 효율성이 크게 다릅니다:
언어별 토큰 효율성 (o200k_base)#
| Language | Text | Tokens | Bytes | Bytes/Token |
|---|---|---|---|---|
| English | "Hello, how are you today?" | 7 | 25 | 3.6 |
| Chinese | "你好,今天怎么样?" | 5 | 27 | 5.4 |
| Japanese | "こんにちは" | 1 | 15 | 15.0 |
| Korean | "안녕하세요" | 2 | 15 | 7.5 |
| Code | def fibonacci(n): (5 lines) | 28 | 92 | 3.3 |
GPT-5의 토크나이저 기준으로, 일본어가 실제로 토큰 효율이 가장 높습니다. こんにちは는 15바이트를 단 1개의 토큰으로 압축합니다.
실제 비용 비교#
100만 자의 텍스트를 GPT-5($1.25/M 입력 토큰)로 처리한다고 가정해 보겠습니다:
| Language | ~Tokens per 1M chars | Cost |
|---|---|---|
| English | ~330K | $0.41 |
| Chinese | ~500K | $0.63 |
| Mixed (EN+CN) | ~400K | $0.50 |
중국어 텍스트는 같은 글자 수 기준으로 영어보다 약 50% 더 비쌉니다. 한국어도 마찬가지로 영어보다 토큰을 더 많이 소비합니다. 각 CJK 문자가 평균적으로 더 많은 토큰을 사용하기 때문입니다.
최적화 팁: 결정하기 전에 모델을 비교하세요#
모델마다 토크나이저, 가격, 기능이 모두 다릅니다. 여러분의 유스케이스에 가장 저렴한 옵션은 예상과 다를 수 있습니다.
통합 API 게이트웨이를 사용하면, 동일한 프롬프트를 여러 모델에 보내 품질과 비용을 한 번에 비교할 수 있습니다:
from openai import OpenAI
client = OpenAI(
api_key="your-crazyrouter-key",
base_url="https://crazyrouter.com/v1"
)
# Test the same prompt across models
for model in ["gpt-5", "gpt-5-mini", "deepseek-v3.2", "claude-sonnet-4"]:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Explain tokenization in 2 sentences"}],
max_tokens=100
)
usage = response.usage
print(f"{model}: {usage.prompt_tokens} in / {usage.completion_tokens} out")
Crazyrouter를 사용하면, 하나의 API 키로 627개 이상의 모델에 접근할 수 있어 특정 언어와 워크로드에 가장 비용 효율적인 모델을 쉽게 찾을 수 있습니다.
미래: 바이트 수준 모델이 토큰을 대체할까?#
2024년 말, Meta는 Byte Latent Transformer (BLT) 연구를 발표했습니다. 토크나이저를 완전히 없애고 원시 바이트를 직접 처리하는 모델 아키텍처입니다.
바이트 수준 모델이 주목받는 이유:#
- 진정한 언어 불가지론(language-agnostic) — 영어 편향이 있는 토크나이저가 없음
- OOV 문제 완전 해결 — 어떤 바이트 시퀀스도 유효한 입력
- 토크나이저-모델 불일치 없음 — 모델이 사용자가 입력한 그대로를 봄
2026년 현재, 토큰이 여전히 지배적인 이유:#
- 바이트 시퀀스는 3~4배 더 길어 — 처리 비용이 훨씬 높음
- 모든 프로덕션 모델 (GPT-5, Claude, Gemini)이 여전히 토큰 기반 아키텍처를 사용
- BLT는 연구 단계 — 아직 상용 API로 제공되지 않음
현실적으로: 토큰은 최소 향후 3~5년 동안 표준으로 남을 것입니다. 토큰의 작동 원리를 이해하는 것은 AI API를 사용하는 모든 개발자에게 필수적인 지식입니다.
한눈에 보기: 토큰 vs 바이트 vs 문자 vs 단어#
| Property | Bytes | Characters | Words | Tokens |
|---|---|---|---|---|
| 정의 | 원시 저장 단위 | 사람이 읽을 수 있는 기호 | 공백으로 구분된 텍스트 | AI용 서브워드 단위 |
| 크기 | 항상 1바이트 | 1-4바이트 (UTF-8) | 가변 | 가변 |
| "Hello" | 5 | 5 | 1 | 1 |
| "你好" | 6 | 2 | 1 | 1 |
| "unbelievable" | 12 | 12 | 1 | 3 |
| 사용 주체 | 컴퓨터 (저장) | 사람 (읽기) | 검색엔진 | AI 모델 |
| AI 과금 기준? | 아니오 | 아니오 | 아니오 | 예 |
핵심 관계:#
- 영어 1토큰 ≈ 4문자 ≈ 4바이트 ≈ 0.75단어
- 중국어 1토큰 ≈ 1
3문자 ≈ 39바이트 ≈ 1~2단어 - 1,000토큰 ≈ 영어 750단어 ≈ 4,000자
유용한 토크나이저 도구:#
- OpenAI Tokenizer — GPT 모델의 토큰 수 확인
- tiktoken (Python) — 프로그래밍 방식의 토큰 카운팅
- Anthropic Token Counter — Claude 모델용
FAQ#
토큰과 바이트는 같은 건가요?#
아닙니다. 바이트는 컴퓨터의 원시 저장 단위(1바이트 = 8비트)이고, 토큰은 AI 모델이 읽는 처리 단위입니다. "Hello"는 5바이트이지만 1토큰입니다. "你好"는 6바이트이지만 역시 1토큰입니다. 바이트와 토큰의 관계는 언어와 토크나이저에 따라 달라집니다.
AI 모델은 왜 원시 바이트를 직접 처리하지 않나요?#
효율성 때문입니다. "Hello"를 바이트로 처리하면 길이 5의 시퀀스이지만, 토큰으로는 길이 1입니다. 1,000단어짜리 글에서 바이트 수준 처리는 시퀀스를 3~4배 더 길게 만듭니다. 트랜스포머 어텐션의 연산 비용이 O(n²)이므로, 이는 AI 모델을 극적으로 느리고 비싸게 만듭니다.
같은 텍스트는 모든 모델에서 같은 토큰 수를 사용하나요?#
아닙니다. GPT-5는 o200k_base 토크나이저를, GPT-4는 cl100k_base를, Claude는 자체 토크나이저를 사용합니다. 중국어 문장 하나가 GPT-4에서는 15토큰이지만 GPT-5에서는 9토큰에 불과할 수 있습니다. 즉, 같은 프롬프트라도 모델에 따라 비용이 달라질 수 있습니다.
한국어/중국어 텍스트가 영어보다 AI API에서 더 비싼 이유는?#
두 가지 이유가 있습니다. 첫째, CJK 문자는 UTF-8에서 문자당 3바이트를 차지합니다 (영문은 1바이트). 둘째, 최신 토크나이저를 사용하더라도 CJK 문자는 토큰으로의 압축 효율이 영어보다 낮습니다. 일반적으로 한국어나 중국어 문장은 같은 의미를 전달하는 영어 문장보다 약 50% 더 많은 토큰을 사용합니다.
토큰 비용을 줄이려면 어떻게 해야 하나요?#
다섯 가지 실용적인 방법이 있습니다: (1) 프롬프트를 간결하게 작성하세요 — 불필요한 단어 하나하나가 토큰 비용입니다. (2) max_tokens로 출력 길이를 제한하세요. (3) 품질 기준을 충족하는 가장 저렴한 모델을 선택하세요. (4) 반복되는 쿼리를 캐싱하세요. (5) Crazyrouter 같은 API 게이트웨이를 활용해 627개 이상의 모델을 하나의 API 키로 비교하세요.
더 읽어보기#
- What Are Tokens in AI? A Beginner's Guide to AI API Pricing
- AI API Pricing Guide 2026: Complete Cost Breakdown
- How to Cut Your AI API Costs by 50%
- Context Window & Token Limits Explained
바이트와 토큰의 차이를 이해하는 것은 AI 비용을 제어하는 첫 번째 단계입니다. 더 많은 개발자 가이드와 최신 모델 가격 데이터는 Crazyrouter 블로그에서 확인하세요.


