
อธิบาย Dimensions ของ text-embedding-3-small: วิธีเลือกขนาดที่เหมาะสมเพื่อคุณภาพและต้นทุน
text-embedding-3-small Dimensions Explained: How to Pick the Right Size for Quality, Speed, and Cost#
At 1536 dimensions, one text-embedding-3-small vector stored as float32 uses 6,144 bytes, so 10 million vectors need about 61 GB before index overhead. That number catches teams off guard when retrieval seems cheap at small scale, then memory bills rise and query time grows after the corpus expands. The hard part is that higher dimensions can improve ranking on one dataset, yet the same setting can waste storage and add latency on another.
That is the core of text-embedding-3-small Dimensions Explained: there is no universal setting that wins on every workload. You need to pick dimension size by testing your own relevance target, p95 latency limit, and vector storage budget together, not one by one. If you only tune for quality, cost climbs fast. If you only cut size, search quality can slip in ways users notice.
You will see a practical selection method: build a small eval set, compare relevance at two or three dimension sizes, measure end-to-end response time, and convert dimension count into real storage cost per million vectors. From there, the right size becomes a measurable engineering choice, not guesswork.
What "Dimensions" Means in text-embedding-3-small (and Why It Changes Outcomes)#
In plain terms, text-embedding-3-small Dimensions Explained means one thing: how much meaning you keep in each vector. Dimension count is a compression knob, not a quality switch. text-embedding-3-small has a max size of 1536 dimensions (from the model spec in the knowledge base). Lower sizes compress harder.
text-embedding-3-small dimensions explained: semantic meaning to numeric vectors#
An embedding turns text into numbers so similar phrases sit near each other in vector space. "Reset my password" and "I cannot sign in" should land close. Each extra dimension gives the model more room to store nuance like intent, tone, or domain terms. If you shrink the vector, you keep core meaning but drop finer detail.
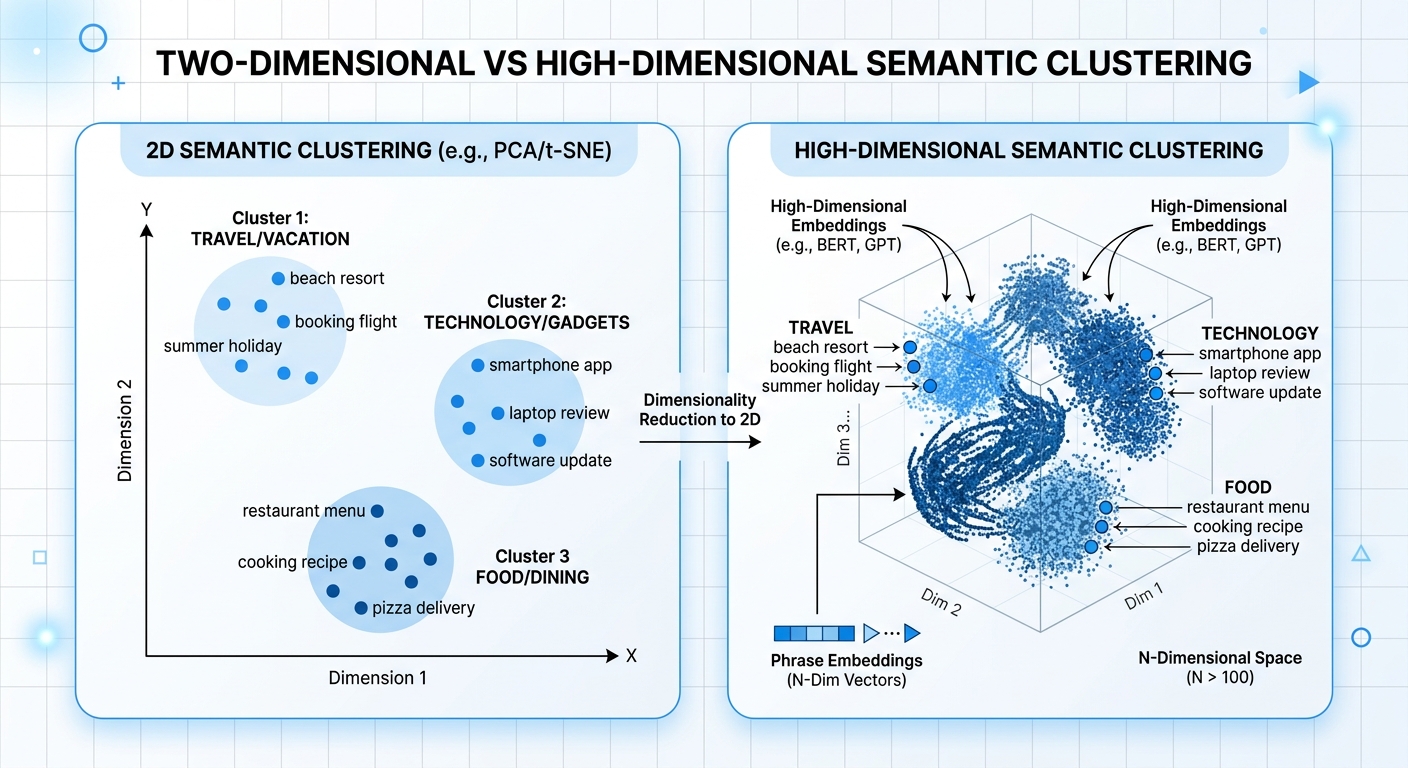
text-embedding-3-small dimension size and ranking quality changes#
Lower dimensions can speed search and cut storage, but nearest-neighbor ranking can shift. That shift shows up when two intents look similar on the surface but differ in action, like "cancel plan" vs "pause plan."
| Vector size choice | Semantic fidelity | Runtime speed | Storage per 1M vectors (float32) |
|---|---|---|---|
| 1536 (full text-embedding-3-small) | Highest detail retention | Slower than smaller vectors | ~6.1 GB |
| 768 (compressed) | Some detail loss | Faster | ~3.1 GB |
| 512 (compressed) | More loss risk on close intents | Faster still | ~2.0 GB |
Source: text-embedding-3-small max dimension from provided knowledge base; storage math from dimensions × 4 bytes.
That is the practical core of text-embedding-3-small Dimensions Explained: tune dimensions with relevance tests, p95 latency, and vector storage together.
text-embedding-3-small Dimension Options: Practical Ranges and Tradeoffs#
For text-embedding-3-small, the native vector size is 1536 dimensions. In real systems, teams often shorten vectors to cut RAM, disk, and ANN index load. Storage grows linearly with dimension count, so each size choice is a direct cost and latency choice. This is the practical core of text-embedding-3-small Dimensions Explained.
text-embedding-3-small Dimensions Explained: common settings and best-fit use cases#
If you need rough defaults, this table is a good starting map for A/B tests.
| Dimension | Raw storage per 1M vectors (float32) | Best fit | Typical risk |
|---|---|---|---|
| 256 | ~0.95 GB | Tight latency or budget limits, simple intent matching | More misses on nuanced queries |
| 384 | ~1.43 GB | Cost-focused semantic search with short texts | Lower recall on edge cases |
| 512 | ~1.91 GB | Balanced search for support docs, product help, FAQ | Some long-tail meaning loss |
| 768 | ~2.86 GB | Balanced-plus retrieval, mixed query styles | Moderate infra cost growth |
| 1024 | ~3.81 GB | High-recall RAG over dense docs | Higher index memory and query time |
| 1536 | ~5.72 GB | Full-fidelity retrieval, nuanced similarity | Highest storage and latency pressure |
Source: dimension ranges from the provided outline and model info (text-embedding-3-small = 1536). Storage is calculated as dimensions × 4 bytes × 1,000,000 vectors.
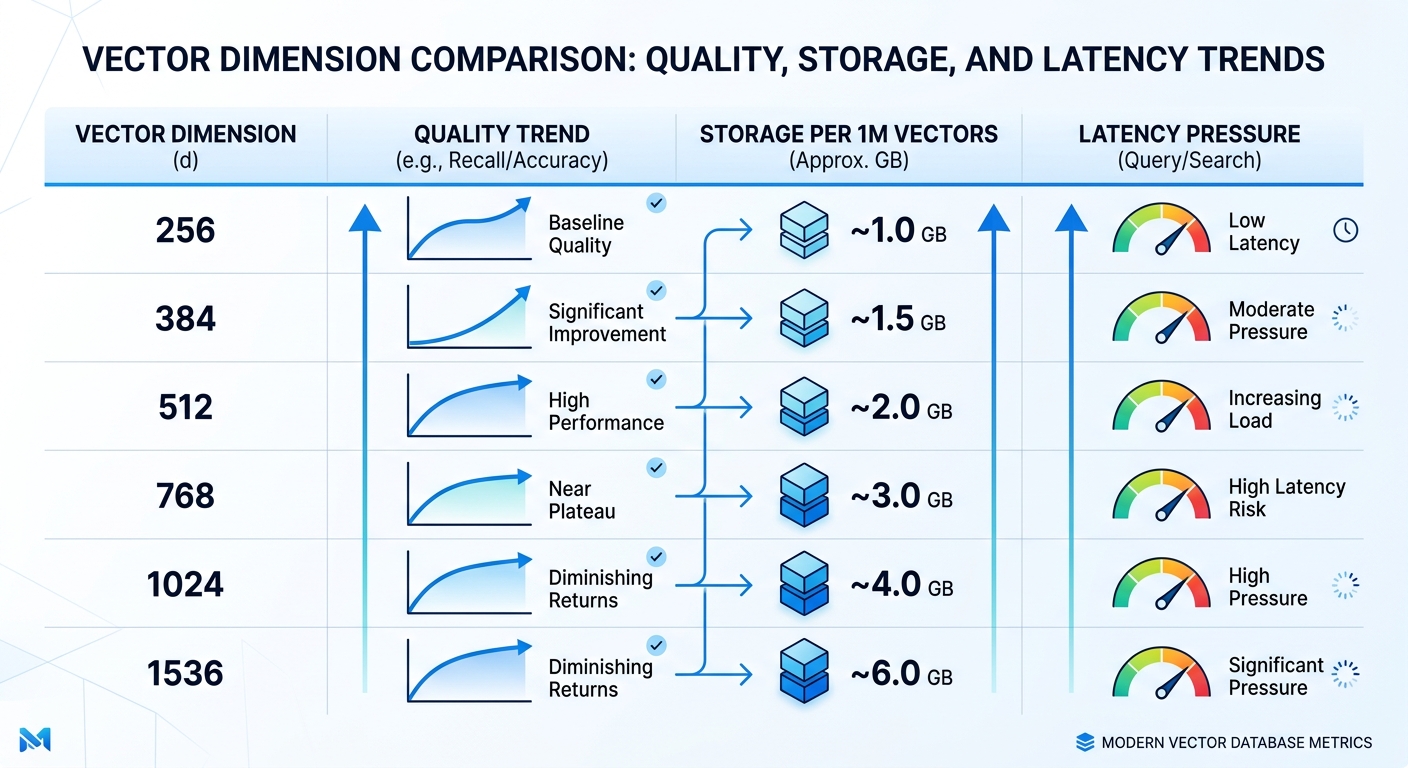
text-embedding-3-small quality tradeoffs: where degradation starts#
Quality loss usually appears earlier on precision-heavy tasks. FAQ retrieval can stay usable at 384 or 512, while legal or medical search often needs 1024 or 1536 to keep fine meaning differences.
Language mix also changes the safe floor. Monolingual English workloads can hold up at lower sizes. Multilingual traffic, code-switching, and mixed scripts tend to degrade sooner when vectors get short.
You can run this test fast through Crazyrouter with one API key and compare retrieval quality at 512, 768, and 1536 on the same eval set. That gives a measurable cutoff point instead of guesswork.
Quality, Latency, and Cost: The Three-Way Benchmark You Actually Need#
You already saw why one metric can mislead. For text-embedding-3-small Dimensions Explained, the practical move is to test one relevance target, one latency budget, and one storage budget at the same time. Pick the smallest dimension that still clears your quality bar under your p95 latency limit.
text-embedding-3-small dimension test set: build offline relevance you trust#
Use real search logs, support tickets, and chat prompts. Build 200–500 query examples if you can. That size is enough to expose weak spots without slowing your team.
Label what "good" means for each query. Keep labels simple: relevant, partially relevant, not relevant. Add hard cases on purpose: short queries, typo queries, domain terms, and multilingual queries. If your app serves mixed languages, include mixed-language queries in the same set.
Do not let only one person label results. Two reviewers reduce bias fast.
text-embedding-3-small dimensions benchmark metrics: quality and latency together#
Track ranking quality and speed in one run. Recall@k tells you if the right item appears in top-k. MRR and nDCG tell you if it appears near the top, where users click.
For latency, split the path: embedding time and retrieval time. Watch p95 and p99, not just average latency. Slow tail requests shape user experience.
| Dimension candidate | Known size per vector (float32) | Relative index memory | Quality metrics to track | Latency metrics to track |
|---|---|---|---|---|
| 1536 (text-embedding-3-small) | 6,144 bytes | 1x baseline | Recall@k, MRR, nDCG | Embedding latency, retrieval p95/p99 |
| 3072 (text-embedding-3-large) | 12,288 bytes | ~2x vs 1536 | Recall@k, MRR, nDCG | Embedding latency, retrieval p95/p99 |
| Lower-dimension candidate in your stack | dims × 4 bytes | dims / 1536 | Recall@k, MRR, nDCG | Embedding latency, retrieval p95/p99 |
แหล่งที่มา: ขนาดโมเดลจาก Crazyrouter model list (text-embedding-3-small: 1536, text-embedding-3-large: 3072) ใช้เวกเตอร์ float32 สำหรับการคำนวณ Byte
text-embedding-3-small รูปแบบต้นทุนมิติ: จากการจัดเก็บไปสู่ผลกระทบต่อธุรกิจ#
แปลงมิติเป็นเงินก่อนการใช้งาน
พื้นที่จัดเก็บต่อเวกเตอร์หนึ่งล้าน = dimension × 4 bytes × 1,000,000 จากนั้นคูณด้วยจำนวนสำเนา เพิ่มค่าใช้จ่ายดัชนีจากฐานข้อมูลเวกเตอร์ของคุณ
<.-- IMAGE: สูตรสไตล์อินโฟกราฟิกสำหรับการประมาณการจัดเก็บเวกเตอร์และต้นทุนรายปีตามมิติและขนาดคลังข้อมูล -->
ตอนนี้เชื่อมโยงคุณภาพที่ยกขึ้นกับสัญญาณธุรกิจที่คุณติดตามอยู่แล้ว เช่น CTR, ticket deflection หรือการแปลงอัตรา หากมิติที่ใหญ่ขึ้นยกระดับ nDCG เล็กน้อย แต่เพิ่มหน่วยความจำเป็นสองเท่าและพลาด p95 ให้เก็บการตั้งค่าที่เล็กกว่า หากระดับความเกี่ยวข้องของการจัดอันดับเพิ่มขึ้นเพียงพอที่จะเปลี่ยนการแปลงอัตรา คุณจะมีกรณีธุรกิจที่ชัดเจน
วิธีเลือกมิติที่เหมาะสมตามกรณีการใช้งาน#
หากคุณยังคงเดาขนาดมิติ ส่วนนี้ของ text-embedding-3-small Dimensions Explained คือทางลัด: จับคู่มิติกับเวิร์กโหลด จากนั้นตรวจสอบด้วยชุดประเมินขนาดเล็กก่อนการใช้งาน
text-embedding-3-small มิติอธิบายสำหรับ RAG และการค้นหาองค์กร#
RAG และการค้นหาภายในล้มเหลวอย่างรวดเร็วเมื่อการเรียกคืนลดลง ผู้ใช้ถามคำถามหนึ่งข้อ จากนั้นก็ออกไปหากผลลัพธ์ด้านบนขาดข้อเท็จจริงหลัก ดังนั้นจุดเริ่มต้นของคุณควรเป็นคุณภาพ ไม่ใช่การจัดเก็บ
ใช้ 1536 เป็นพื้นฐานสำหรับ text-embedding-3-small จากนั้นทดสอบขนาดที่ต่ำกว่าเพียงหนึ่งขนาดหลังจากที่คุณยืนยันการเรียกคืนในการสืบค้นที่ยาก การสืบค้นที่ยากหมายถึงคำถามที่ยาว คำที่หายาก และความตั้งใจแบบผสม
การแบ่งส่วนเปลี่ยนผลลัพธ์มากกว่าที่ผู้คนคาดหวัง ส่วนเล็กๆ บวกกับมิติต่ำสามารถสูญเสียบริบทสองครั้ง: ครั้งหนึ่งในการแบ่ง ครั้งหนึ่งในการฝัง หากส่วนของคุณสั้น ให้เก็บมิติที่สูงกว่า หากส่วนของคุณยาวและสะอาด คุณสามารถทดสอบขนาดที่ต่ำกว่าโดยไม่มีความเสี่ยง
text-embedding-3-small มิติสำหรับการแนะนำ การจัดกลุ่ม และการกำหนดเส้นทางเชิงความหมาย#
ระบบเหล่านี้มักสนใจเรื่องความเร็วและการจัดกลุ่มที่เสถียร ไม่ใช่การเรียกคืนด้านบน-1 ที่สมบูรณ์แบบ การตั้งค่ากลางมักจะให้ความสมดุลที่ดีที่สุด
สำหรับการกำหนดเส้นทาง ความคล้ายคลึงโดยประมาณมักจะเพียงพอเพราะแบบจำลองขั้นตอนที่สองสามารถจัดลำดับใหม่หรือตรวจสอบ ซึ่งหมายความว่าคุณสามารถทดสอบมิติที่ต่ำกว่าได้เร็วกว่าที่คุณจะทำใน RAG สำหรับการจัดกลุ่ม ให้ตัดสินความบริสุทธิ์ของกลุ่มและการเปลี่ยนแปลงข้อมูลรายสัปดาห์ ไม่ใช่เพียงการรันแบบออฟไลน์เดียว
เลือกมิติที่เล็กที่สุดซึ่งยังคงเก็บเมตริกดาวน์สตรีมของคุณให้คงที่ตลอดสองรอบการเข้าชมแบบเต็ม
text-embedding-3-small มิติอธิบายสำหรับเวิร์กโหลดหลายภาษาและเฉพาะโดเมน#
ภาษาโดเมนเปลี่ยนเกม คำศัพท์ทางกฎหมาย การแพทย์ หรือฮาร์ดแวร์สามารถอยู่ใกล้ในภาษาธรรมชาติ แต่ไกลในความหมาย มิติต่ำอาจทำให้ขอบเขตเหล่านี้เบลอ
การเข้าชมแบบหลายภาษาต้องการการตรวจสอบต่อภาษา อย่าเฉลี่ยทุกอย่างลงในคะแนนเดียว เรียกใช้ชุดความตั้งใจเดียวกันในแต่ละส่วนภาษาหลัก จากนั้นเปรียบเทียบรูปแบบการพลาด ขนาดที่ใช้งานได้ในภาษาอังกฤษสามารถล้มเหลวในการสืบค้นแบบผสมภาษาหรือคำที่ปลายนิ้ว
| กรณีการใช้งาน | มิติเริ่มต้นที่แนะนำ | สิ่งที่ต้องวัดก่อนลดลง | สัญญาณความล้มเหลวทั่วไป |
|---|---|---|---|
| RAG / การค้นหาองค์กร | 1536 | การเรียกคืนในการสืบค้นที่ยาก การยึดติดคำตอบ | เอกสารที่ถูกต้องไม่อยู่ในผลลัพธ์ด้านบน |
| คำแนะนำ | กลาง (ทดสอบต่ำกว่า 1536) | ความเสถียรของ CTR หรืออัตราการแปลง | รายการที่คล้ายกันแต่ไม่เกี่ยวข้องเพิ่มขึ้น |
| การกำหนดเส้นทางเชิงความหมาย | กลางถึงต่ำกว่า | ความแม่นยำของเส้นทาง + อัตราการสำรอง | เส้นทางผิด อัตราการสำรองที่สูงขึ้น |
| หลายภาษา / โดเมนหนัก | 1536 | การเรียกคืนต่อภาษา ข้อผิดพลาดระดับคำศัพท์ | คำที่หายากแมปกับความหมายทั่วไป |
แหล่งที่มา: ข้อมูลมิติโมเดลจาก Crazyrouter model list (text-embedding-3-small: 1536, text-embedding-3-large: 3072) <.-- IMAGE: เมทริกซ์การตัดสินใจตามกรณีการใช้งาน (RAG, recsys, routing, multilingual) พร้อมมิติเริ่มต้นที่แนะนำ -->
คำแนะนำการใช้งาน: API, Schema เวกเตอร์ และขั้นตอนการโยกย้าย#
text-embedding-3-small มิติอธิบายในคำขอ API#
พื้นฐานที่ปลอดภัยสำหรับ text-embedding-3-small คือมิติ 1536 คุณสามารถขอขนาดที่เล็กกว่าด้วยฟิลด์ dimensions แต่ให้เก็บขนาดนั้นไว้คงที่ต่อดัชนี หากเวกเตอร์เอกสารใช้ 1024 และเวกเตอร์สอบถามใช้ 1536 คุณภาพการเรียกค้นจะลอยตัวแม้ว่าการโทรทั้งสองจะสำเร็จ
ใช้ค่าการกำหนดค่าเดียวสำหรับเส้นทางการเขียนและอ่าน จากนั้นตรวจสอบในทุกคำขอ: ข้อความอินพุตไม่ว่าง ความยาวเวกเตอร์เท่ากับมิติที่กำหนดค่า และทุกค่าเป็นตัวเลขจริง (ไม่มี NaN ไม่มี Inf) หากการตรวจสอบล้มเหลว ให้กำหนดเส้นทางรายการไปยังคิวการลองใหม่และปฝังใหม่ด้วยขนาดเริ่มต้นของคุณ
คุณสามารถใช้ OpenAI SDK กับจุดสิ้นสุดที่เข้ากันได้เช่น https://crazyrouter.com/v1 จากนั้นปักหมุดโมเดลและมิติในไฟล์การกำหนดค่าที่ใช้ร่วมกันหนึ่งไฟล์ที่ใช้โดยบริการทั้งหมด
text-embedding-3-small การควบคุมมิติในสคีมาเวกเตอร์และการออกแบบดัชนี#
ให้เก็บมิติเดียวต่อดัชนี และให้เก็บเวกเตอร์การสืบค้นและเอกสารไว้ในขนาดเดียวกัน
ใช้ชื่อคอลเลกชันที่ล็อกมิติ เช่น kb_d1536_v1 และ kb_d1024_v1 การตั้งชื่อนี้ทำให้การโยกย้ายสามารถอ่านได้และป้องกันการผสมแบบเงียบ ๆ
<.-- IMAGE: แผนภาพสถาปัตยกรรมแสดงการการจำหน่ายสินค้า บริการฝัง ดัชนีเวกเตอร์คู่ และเราเตอร์สอบถาม -->
เมื่อมิติความเป็นมิติเปลี่ยนแปลง ให้สร้างการตั้งค่าดัชนีใหม่ด้วยเวกเตอร์ใหม่ สำหรับ HNSW ให้ปรับแต่งกราฟและการตั้งค่าการค้นหาหลังจากการสร้างใหม่ สำหรับ IVF ให้ฝึกเซนทรอยด์ใหม่บนเวกเตอร์จากขนาดมิติใหม่ การใช้ข้อมูลการฝึกดัชนีเก่าได้สามารถทำร้ายการเรียกคืน
text-embedding-3-small มิติอธิบายสำหรับการโยกย้ายจากโมเดลที่เก่ากว่า#
เรียกใช้การโยกย้ายในเฟส:
| เฟส | เส้นทางการเขียน | เส้นทางการอ่าน | สิ่งที่ต้องตรวจสอบ |
|---|---|---|---|
| การเขียนแบบคู่ | การฝังแบบเก่า + ใหม่ | ดัชนีเก่า | อัตราความสำเร็จของการเขียนและข้อผิดพลาดในการตรวจสอบเวกเตอร์ |
| เงาอ่าน | การฝังแบบเก่า + ใหม่ | ผู้ใช้เห็นเก่า บันทึกใหม่ | การทับซ้อนของ top-k เวลาแฝง กรณีการสืบค้นที่ไม่ดี |
| ตัดจำหน่าย | การฝังแบบเก่า + ใหม่ | ดัชนีใหม่ | อัตราผ่านความเกี่ยวข้องและเป้าหมาย p95 latency |
| การสำรอง | ให้การเขียนแบบคู่ใช้งานต่อไป | สลับกลับไปที่เก่า | เรียกใช้ในการเพิ่มข้อผิดพลาดหรือการลดความเกี่ยวข้อง |
แหล่งที่มา: ฐานความรู้ Crazyrouter (text-embedding-3-small ที่มิติ 1536; OpenAI-compatible API; 300+ โมเดลที่รองรับ)
นี่คือแก่นกลางการปฏิบัติของ text-embedding-3-small Dimensions Explained: ล็อกมิติ ทดสอบด้วยการเข้าชมเงา และตัดจำหน่ายเพียงหลังจากความเท่าเทียมกันที่วัด
การดำเนินงานการผลิต: การตรวจสอบการเลื่อน การถดถอยคุณภาพ และเวิร์กโฟลว์ทีม#
คุณเลือกขนาดมิติด้วยการทดสอบแบบออฟไลน์ จุดเริ่มต้นที่ดี ความเสี่ยงที่แท้จริงปรากฏขึ้นในภายหลัง หลังจากเนื้อหาใหม่ การผสมสอบถามใหม่ และการเปลี่ยนแปลงการจัดอันดับมีผลต่อการผลิต ใน text-embedding-3-small Dimensions Explained คุณภาพระยะยาวมาจากลูปแบบแน่น: ข้อมูลการประเมินแบบคงที่ การตรวจสอบพฤติกรรมแบบสด และขั้นตอนการใช้งานที่มีการควบคุม
ตั้งค่า text-embedding-3-small การตรวจสอบการเลื่อนมิติ#
ล็อกชุดประเมินและเมตริกของคุณก่อนการเปลี่ยนแปลงมิติแต่ละครั้ง เก็บชุดการสืบค้นสีทองที่ตรงกับความตั้งใจของผู้ใช้ที่แท้จริง จากนั้นให้คะแนนทุกสัปดาห์ด้วยหลักเกณฑ์เดียวกัน จับคู่กับสัญญาณที่สดใหม่เพื่อให้คุณจับการเลื่อนเร็ว ไม่ใช่หลังจากตั๋วสนับสนุนสะสม
| สัญญาณ | สิ่งที่การเลื่อนมีลักษณะเช่นไร | ความถี่การทบทวน | ทริกเกอร์การดำเนิน |
|---|---|---|---|
| คะแนนความเกี่ยวข้องของชุดสีทอง | ผลลัพธ์ด้านบนหยุดตรงกับคำตอบที่ทราบว่าดี | สัปดาห์ละหนึ่งครั้ง | ลดลงเทียบกับการรันที่เสถียรล่าสุด |
| CTR ในบล็อกการเรียกค้น | ผู้ใช้คลิกเอกสารที่แนะนำน้อยลง | ทุกวัน | การลดลงที่ยั่งยืน |
| อัตราความสำเร็จของงาน | เซสชันมากขึ้นล้มเหลวในการสิ้นสุดงานเป้าหมาย | ทุกวัน | ลดลงตามส่วน |
| อัตรา-ผลลัพธ์ | การตอบสนองการเรียกค้นว่างเปล่าเพิ่มขึ้น | ทุกวัน | เพิ่มขึ้นหลังจากการนำไปใช้ |
แหล่งที่มาของตาราง: รูปแบบ operational runbook ที่ใช้ในส่วนนี้ (golden set + online metrics จากโครงร่างที่ให้มา)
<.-- IMAGE: dashboard mock showing weekly golden-set score, CTR trend, no-result rate, and alert thresholds -->
เรียกใช้การทดลอง text-embedding-3-small dimension อย่างปลอดภัยในสภาพแวดล้อม staging และ production#
เริ่มต้นใน staging ด้วยการเล่นซ้ำคำค้นหาจากช่วง 7 ถึง 14 วันที่ผ่านมา ย้ายไปยัง production ด้วย canary slice จากนั้นขยายตามส่วนผู้ใช้และภูมิภาค เตรียมการ rollback ให้พร้อม หากคุณภาพลดลง ให้หยุดการเพิ่มขึ้นของการรับส่งข้อมูล เปลี่ยนไปใช้ dimension ที่เสถียรครั้งสุดท้าย และบันทึกประเภทคำค้นหาที่ล้มเหลว วิธีนี้ช่วยให้เหตุการณ์ที่ไม่คาดคิดสั้นลง และให้ข้อมูลที่สะอาดสำหรับการทดสอบครั้งต่อไป
ขั้นตอนการทำงานของทีมสำหรับการอธิบาย text-embedding-3-small Dimensions#
การประเมินผลข้ามทีมมักจะล้มเหลวเนื่องจากผู้คนทดสอบในเซสชันเบราว์เซอร์แบบผสม SEO ผลิตภัณฑ์ และ ML สามารถเขียนทับสถานะของกันและกันได้ จากนั้นไม่มีใครเชื่อผลลัพธ์ คุณสามารถใช้ DICloak โปรไฟล์ที่แยกออกมาเพื่อให้แต่ละบทบาททดสอบบิลด์เดียวกันโดยไม่มีความขัดแย้งของเซสชันหรือการข้ามบัญชี
เครื่องมือเช่น DICloak ให้คุณตั้งค่ากฎ proxy และเซสชันคงที่ต่อโปรไฟล์ นั่นหมายความว่าการทดสอบ "US-English account" และ "EU account" ของคุณทำงานในสภาพแวดล้อมเครือข่ายที่เสถียรทุกครั้ง การตั้งค่าที่สามารถทำซ้ำได้ทำให้การตรวจสอบการจัดอันดับตามมิติข้อมูลง่ายขึ้นในการเปรียบเทียบระหว่างเพื่อนร่วมทีม และให้คุณเส้นทางที่สามารถทำซ้ำได้และปลอดภัยสำหรับงาน text-embedding-3-small Dimensions Explained ที่อยู่ในการดำเนินการ
ข้อผิดพลาดทั่วไปและรายการตรวจสอบการเลือก Dimension ขั้นสุดท้าย#
หากคุณอ่านมาถึงตรงนี้ text-embedding-3-small Dimensions Explained ควรจบลงด้วยการตัดสินใจเปิดตัว ไม่ใช่การเดา
ข้อผิดพลาด text-embedding-3-small dimension ที่ทำให้ production พัง#
| ข้อผิดพลาด | เกิดอะไรขึ้น | ต้องทำอะไร |
|---|---|---|
| คุณเชื่อคะแนนเกณฑ์มาตรฐานของผู้ขายเท่านั้น | การค้นหาดูเหมือนจะดีในการทดสอบ แต่คำค้นหาจริงของคุณพลาดจุดประสงค์ | สร้างชุดการประเมินผลภายในจากคำค้นหาผู้ใช้จริง จากนั้นให้คะแนนการตั้งค่า dimension แต่ละรายการในชุดนั้น |
| คุณลดต้นทุนการจัดเก็บข้อมูลและข้ามการตรวจสอบคุณภาพ | ขนาดเวกเตอร์ที่ต่ำกว่าช่วยประหยัดเงิน แต่คุณภาพการคลิกลดลงและตั๋วการสนับสนุนเพิ่มขึ้น | ติดตามคุณภาพการดึงข้อมูลและพฤติกรรมผู้ใช้ร่วมกันก่อนการเปิดตัว |
| คุณทดสอบความเกี่ยวข้องเท่านั้น | การตั้งค่าดัชนีที่รวดเร็วยังคงสามารถล้มเหลวเป้าหมาย p95 ของคุณได้ | วัดความล่าช้าแบบ end-to-end: embed + index search + rerank |
รายการตรวจสอบ 10 จุดขั้นสุดท้ายสำหรับการเปิดตัว text-embedding-3-small Dimensions Explained#
- ล้างข้อมูลที่ซ้ำกันและข้อความที่เสียหายในข้อมูลต้นทาง
- ครอบคลุมคำค้นหา head, mid และ tail ในเกณฑ์มาตรฐานของคุณ
- เปรียบเทียบอย่างน้อยสองขนาด: 1536 (text-embedding-3-small) และ 3072 (text-embedding-3-large)
- บันทึก top-k relevance สำหรับแต่ละขนาดในชุดคำค้นหาเดียวกัน
- บันทึก p95 latency จากการเรียก API ไปยังผลลัพธ์ที่จัดอันดับขั้นสุดท้าย
- แปลงจำนวน dimension เป็นต้นทุนการจัดเก็บข้อมูลต่อเวกเตอร์หนึ่งล้านตัว
- เรียกใช้ canary ด้วยการรับส่งข้อมูลจริงและเมตริกความสำเร็จ
- เตรียมขั้นตอนการ rollback ก่อนการเปิดตัวแบบเต็ม
- กำหนดเจ้าของคนหนึ่งคนสำหรับการตรวจสอบและการตอบสนองต่อการแจ้งเตือน
- ตั้งค่าความถี่ในการฝึกอบรมใหม่หรือการตรวจสอบการฝังใหม่
เปิดตัวเฉพาะเมื่อความเกี่ยวข้อง p95 latency และต้นทุนการจัดเก็บข้อมูลผ่านร่วมกัน
<.-- IMAGE: One-page launch checklist graphic for embedding dimension decisions. -->
คำถามที่พบบ่อย#
ใน text-embedding-3-small Dimensions Explained มิติข้อมูลเริ่มต้นที่ดีที่สุดคืออะไร#
จุดเริ่มต้นที่ใช้ได้จริงคือ 512 สำหรับทีมส่วนใหญ่ หรือ 1024 หากเนื้อหาของคุณซับซ้อน (เอกสารทางกฎหมาย เทคนิค หรือแบบยาว) ใน text-embedding-3-small Dimensions Explained สิ่งนี้ให้ความสมดุลที่แข็งแกร่งของคุณภาพ ความเร็ว และต้นทุนโดยไม่ต้องมีความผูกพันมากเกินไปในช่วงแรก จากนั้นเรียกใช้เกณฑ์มาตรฐานขนาดเล็กโดยใช้คำค้นหาผู้ใช้จริงและตัวกรองที่คาดไว้ เลือกมิติข้อมูลที่เล็กที่สุดที่ยังคงตรงตามเป้าหมายความเกี่ยวข้องของคุณ ไม่ใช่เพียงอันที่ดูดีที่สุดในการทดสอบของเล่น
การลดมิติข้อมูลใน text-embedding-3-small Dimensions Explained ลดคุณภาพการดึงข้อมูลเสมอหรือไม่#
มิติข้อมูลที่ต่ำกว่าไม่ได้ทำให้ผลลัพธ์เสียหายในลักษณะที่มีความหมายเสมอไป สำหรับการค้นหา FAQ แบบสั้นหรือโดเมนแคบ การลดลงสามารถเล็กน้อย สำหรับแคตตาล็อกที่กว้างขวาง เนื้อหาหลายภาษา หรือการจับคู่ความหมายที่ละเอียดอ่อน คุณภาพสามารถลดลงได้เร็วขึ้น ใน text-embedding-3-small Dimensions Explained ให้ถือว่ามิติข้อมูลเป็นปุ่มปรับแต่ง: เปรียบเทียบ 256, 512 และ 1024 ในชุดคำค้นหาเดียวกัน เก็บขนาดที่เล็กที่สุดที่รักษา Recall@k ที่ยอมรับได้และคุณภาพการจัดอันดับสำหรับผู้ใช้จริงของคุณ
มิติข้อมูล text-embedding-3-small ส่งผลต่อต้นทุนฐานข้อมูลเวกเตอร์อย่างไร#
ต้นทุนปรับขนาดตามจำนวนมิติข้อมูลโดยประมาณเป็นเส้นตรง หากคุณลดเวกเตอร์จาก 1024 เป็น 512 การจัดเก็บข้อมูลเวกเตอร์ดิบจะประมาณครึ่งหนึ่ง แนวโน้มเดียวกันนี้ใช้กับการใช้ RAM และมักจะคำนวณการค้นหา แต่รวมค่าใช้จ่ายของดัชนี: โครงสร้าง ANN เพิ่มหน่วยความจำสำหรับลิงก์กราฟ ข้อมูลเมตา และการบัญชีภายใน ดังนั้นการประหยัดทั้งหมดจึงแข็งแกร่ง แต่ไม่ใช่เพียงไบต์เวกเตอร์เท่านั้น ในทางปฏิบัติ ให้ประมาณขนาดดัชนีแบบเต็ม ไม่ใช่เพียงขนาดการฝัง ก่อนที่คุณจะตั้งค่ามิติข้อมูลขั้นสุดท้าย
ฉันต้องฝังเอกสารทั้งหมดใหม่เมื่อเปลี่ยนมิติข้อมูลหรือไม่#
ใช่ เวกเตอร์ที่สร้างขึ้นในมิติข้อมูลหนึ่งไม่สามารถผสมกับเวกเตอร์จากมิติข้อมูลอื่นในดัชนีที่สอดคล้องกันหนึ่งได้ เมื่อคุณเปลี่ยนมิติข้อมูล ให้ฝังเอกสารทั้งหมดใหม่และสร้างดัชนีใหม่ สำหรับระบบการผลิต ให้ใช้การโยกย้ายที่ปลอดภัยกว่า: สร้างดัชนีใหม่แบบขนาน ส่งการรับส่งข้อมูลส่วนหนึ่งไปยังดัชนีใหม่ เปรียบเทียบคุณภาพและความล่าช้า จากนั้นสลับไปใช้เต็มที่ วิธีนี้หลีกเลี่ยงเวลาหยุดทำงานและรักษาพฤติกรรมการค้นหาให้เสถียรระหว่างการเปลี่ยนแปลง
ฉันควรติดตามเมตริกใดเมื่อเปรียบเทียบมิติข้อมูล#
ติดตามสามกลุ่ม: ความเกี่ยวข้อง ความเร็ว และต้นทุน สำหรับความเกี่ยวข้อง ให้ใช้ Recall@k, nDCG และ MRR ในชุดคำค้นหาที่มีป้ายกำกับ สำหรับความเร็ว ให้ดูความล่าช้า p50/p95/p99 เนื่องจากความล่าช้าของหางส่งผลต่อประสบการณ์ผู้ใช้ สำหรับต้นทุน ให้วัดการจัดเก็บข้อมูลต่อเอกสารหนึ่งล้านตัว ฟุตพ্রินต์ RAM และต้นทุนต่อการค้นหา 1,000 ครั้ง ใน text-embedding-3-small Dimensions Explained การให้คะแนนนี้ช่วยให้คุณหลีกเลี่ยงตัวเลือกด้านเดียวที่คุณประหยัดการจัดเก็บข้อมูล แต่ทำให้คุณภาพการจัดอันดับเสียหายมากเกินไป
text-embedding-3-small เหมาะสำหรับการค้นหาหลายภาษาในมิติข้อมูลที่ต่ำกว่าหรือไม่#
มันสามารถทำได้ แต่การค้นหาหลายภาษาต้องการการทดสอบที่เข้มงวดกว่าการค้นหาภาษาเดียว มิติข้อมูลที่ต่ำกว่าอาจรวมความหมายที่ละเอียดอ่อนข้ามภาษา โดยเฉพาะอย่างยิ่งสำหรับคำค้นหาสั้นและสคริปต์แบบผสม เริ่มต้นที่ 512 หรือ 1024 จากนั้นทดสอบตามคู่ภาษา ความยาวของคำค้นหา และเงื่อนไขโดเมน ใน text-embedding-3-small Dimensions Explained การตั้งค่าหลายภาษามักจะได้รับประโยชน์จากมิติข้อมูลที่ใหญ่ขึ้นเมื่อความแม่นยำมีความสำคัญ เลือกการตั้งค่าที่เล็กที่สุดที่ยังคงตรงตามเป้าหมายความเกี่ยวข้องสำหรับแต่ละส่วนภาษาหลัก
ข้อสรุปหลักคือมิติข้อมูล text-embedding-3-small เป็นปุ่มปรับแต่งที่ใช้ได้จริง: มิติข้อมูลที่สูงกว่าสามารถปรับปรุงความเที่ยงตรงของความหมาย ในขณะที่มิติข้อมูลที่ต่ำกว่าลดการจัดเก็บข้อมูล ความล่าช้า และต้นทุน ดังนั้นตัวเลือกที่ถูกต้องจึงขึ้นอยู่กับเป้าหมายคุณภาพการดึงข้อมูลและข้อจำกัดของระบบของคุณ ให้ถือว่าขนาดมิติข้อมูลเป็นการตัดสินใจเชิงประจักษ์โดยการเปรียบเทียบ recall, ranking quality และประสิทธิภาพแบบ end-to-end ในข้อมูลของคุณเองแทนที่จะพึ่งพาค่าเริ่มต้น ทดสอบมิติข้อมูลหลายรายการในไปป์ไลน์ของคุณเองในสัปดาห์นี้ จากนั้นล็อกการตั้งค่า production ของคุณด้วยหลักฐาน ไม่ใช่การเดา


