Yapay Zekada Token ve Byte Farkı: LLM'ler Yazdıklarınızı Nasıl Görüyor?
"Byte, karakter, kelime ve token arasındaki gerçek farkı anlayın. BPE tokenizasyonunun nasıl çalıştığını, Çincenin neden İngilizceden daha pahalıya mal olduğunu ve token kullanımınızı nasıl optimize edeceğinizi öğrenin."

Yapay Zekada Token ve Byte Farkı: LLM'ler Yazdıklarınızı Nasıl Görüyor?#
GPT-5'e "你好 Hello" yazıyorsunuz. Bu 7 karakter. Ancak model bunu 2 token olarak işliyor — ve faturanız karakterlere değil, bu tokenlara göre kesiliyor.
Aynı metni bilgisayarınız ise 12 byte olarak depoluyor.
Peki byte, karakter ve token arasındaki fark tam olarak nedir? Yapay zeka neden ham byte yerine token kullanıyor? Ve aynı cümle Çince yazıldığında neden İngilizceden daha pahalıya mal oluyor?
Bu rehberde, sabit diskinizdeki byte'lardan yapay zekanın okuduğu tokenlara kadar tüm işlem hattını adım adım açıklıyoruz.
Temelden Başlayalım: Byte Nedir?#
Byte, bilgisayarınızın depoladığı en küçük veri birimidir. 1 byte = 8 bit = 0 ile 255 arasında bir sayı.
Bir metni dosyaya kaydettiğinizde, bilgisayarınız her karakteri UTF-8 adlı standart kullanarak byte'lara dönüştürür:
| Karakter | UTF-8 Byte'ları | Byte Sayısı | Hex |
|---|---|---|---|
H | 72 | 1 | 48 |
e | 101 | 1 | 65 |
你 | 228, 189, 160 | 3 | e4 bd a0 |
好 | 229, 165, 189 | 3 | e5 a5 bd |
🚀 | 240, 159, 154, 128 | 4 | f0 9f 9a 80 |
Temel kural:
- İngilizce harfler: her biri 1 byte
- Çince/Japonca/Korece karakterler: her biri 3 byte
- Emojiler: her biri 4 byte
Dolayısıyla "你好 Hello" metni 12 byte olarak depolanır:
你 好 [space] H e l l o
e4 bd a0 e5 a5 bd 20 48 65 6c 6c 6f
(3 byte) (3 byte) (1) (1) (1) (1) (1) (1) = 12 byte
Byte'lar bilgisayarların metni depolama biçimidir. Ancak yapay zeka modelleri byte'ları doğrudan okumaz.
Dört Katman: Byte → Karakter → Kelime → Token#
Bir metin parçasını dört farklı şekilde parçalayabilirsiniz. Her katman veriyi farklı biçimde gruplar:
| Katman | "Hello, World" | Sayı | Açıklama |
|---|---|---|---|
| Byte | 48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 | 12 | Ham depolama birimleri |
| Karakter | H e l l o , ␣ W o r l d | 12 | İnsanın okuyabildiği harfler |
| Kelime | Hello, World | 2 | Boşlukla ayrılan birimler |
| Token | Hello , World | 3 | Yapay zekanın gerçekten işlediği birimler |
Aynı karşılaştırmayı Çince ile yapalım:
| Katman | "你好世界" | Sayı | Açıklama |
|---|---|---|---|
| Byte | e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c | 12 | Karakter başına 3 byte |
| Karakter | 你 好 世 界 | 4 | Her karakter = 1 Çince kelime |
| Kelime | 你好 世界 | 2 | Anlam temelli bölümleme |
| Token | 你好 世界 | 2 | Tokenizer'a bağlı |
Kritik nokta şu: Tokenlar ne byte'tır, ne karakterdir, ne de kelimedir. Bunlar, sözlük boyutu ile dizi uzunluğu arasında denge kuran alt-kelime (sub-word) birimleridir.
Neden Doğrudan Byte veya Kelime Kullanılmıyor?#
Byte ve kelimeler daha basitse, yapay zeka neden tokeni icat etti? Çünkü her iki ucun da ciddi sorunları var:
Byte'ların sorunu: diziler çok uzun oluyor#
"Hello" 5 byte'tır. 1.000 kelimelik bir blog yazısı yaklaşık 5.000 byte eder. Bir roman ise 500.000 byte civarındadır.
Bir yapay zeka modelinin dizideki tüm konumlar arasındaki ilişkileri işlemesi gerekir. Hesaplama maliyeti dizi uzunluğunun karesiyle orantılı büyür (attention mekanizması için O(n²)). Dizi uzunluğunu ikiye katlayın — hesaplama maliyeti 4 katına çıkar.
Ham byte'lar kullanmak dizileri gereğinden 3-4 kat uzun yapar ve yapay zeka modellerini karşılanamayacak kadar yavaşlatır.
Kelimelerin sorunu: sözlük patlaması#
İngilizcede yaygın kullanımda 170.000'den fazla kelime bulunur. Teknik terimler, isimler, URL'ler, kod ve diğer dilleri ekleyin — milyonlarca girdili bir sözlüğe ihtiyaç duyarsınız.
Devasa bir sözlük şu anlama gelir:
- Çok büyük bir gömme (embedding) tablosu (bellek açısından çok pahalı)
- Çoğu kelime nadir olduğundan model bunları yeterince öğrenemez
- Sözlükte olmayan herhangi bir kelime tamamen bilinmezdir ("OOV" — Out of Vocabulary problemi)
Tokenlar: altın orta yol#
Tokenlar metni alt-kelime birimlerine böler — byte'lardan büyük ama kelimelerden küçük parçalar:
"unbelievable" → ["un", "bel", "ievable"] (3 token)
"tokenization" → ["Token", "ization"] (2 token)
"Hello" → ["Hello"] (1 token — yeterince yaygın, bölünmeden kalır)
Bu sayede:
- Kısa diziler (verimli işleme)
- Küçük sözlük (~100K-200K girdi, milyonlar değil)
- Bilinmeyen kelime yok (herhangi bir metin bilinen alt-kelimelere bölünebilir)
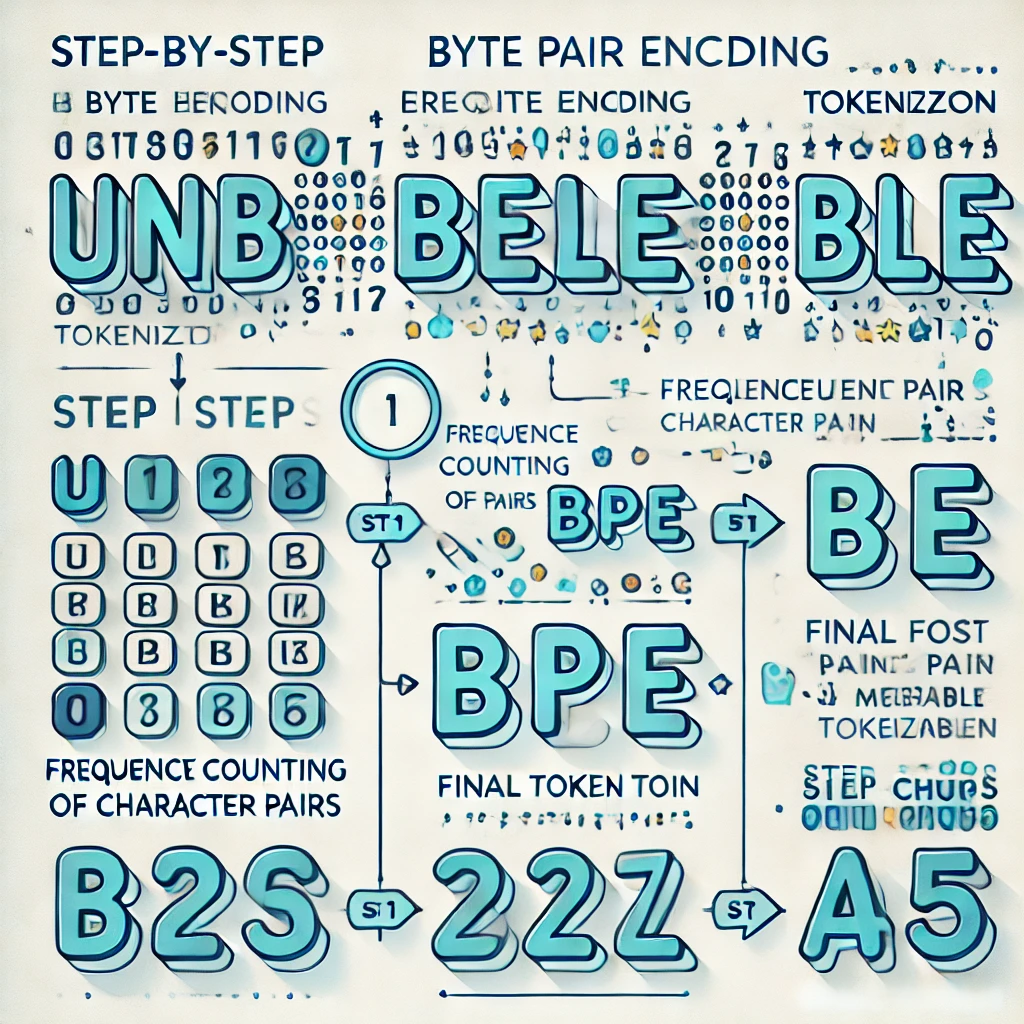
BPE Tokenizasyonu Gerçekte Nasıl Çalışır?#
Günümüzün büyük dil modellerinin çoğu, tokenizer'larını oluşturmak için Byte Pair Encoding (BPE) yönteminin bir varyantını kullanır. İşte adım adım nasıl çalışır:
Adım 1: Tek tek karakterlerle başlayın#
Eğitim metninizi alın ve her şeyi tek karakterlere bölün:
"low" → ["l", "o", "w"]
"lower" → ["l", "o", "w", "e", "r"]
"newest" → ["n", "e", "w", "e", "s", "t"]
Adım 2: En sık geçen çifti sayın#
Tüm yan yana karakter çiftlerine bakın ve en yaygın olanı bulun:
("l", "o") 2 kez geçiyor ← en sık
("o", "w") 2 kez geçiyor
("e", "w") 1 kez geçiyor
...
Adım 3: En sık çifti birleştirin#
Tüm ("l", "o") geçişlerini yeni "lo" tokeni ile değiştirin:
"low" → ["lo", "w"]
"lower" → ["lo", "w", "e", "r"]
Adım 4: Binlerce kez tekrarlayın#
Hedef sözlük boyutuna (genellikle 50K-200K token) ulaşılana kadar sayma ve birleştirme işlemini sürdürün.
Birçok birleştirmeden sonra "the", "Hello" ve "you" gibi yaygın kelimeler tek token haline gelirken, nadir kelimeler alt-kelime parçalarına bölünür.
tiktoken ile kendiniz deneyin#
GPT-5'in herhangi bir metni nasıl tokenize ettiğini, OpenAI'ın tiktoken kütüphanesi ile inceleyebilirsiniz:
import tiktoken
# o200k_base, GPT-4o ve GPT-5 tarafından kullanılır
enc = tiktoken.get_encoding("o200k_base")
text = "你好 Hello"
tokens = enc.encode(text)
token_strings = [enc.decode([t]) for t in tokens]
print(f"Text: {text}")
print(f"UTF-8 bytes: {len(text.encode('utf-8'))}")
print(f"Tokens ({len(tokens)}): {token_strings}")
print(f"Token IDs: {tokens}")
Test çıktısı:#
Text: 你好 Hello
UTF-8 bytes: 12
Tokens (2): ['你好', ' Hello']
Token IDs: [177519, 32949]
12 byte, sadece 2 tokene sıkıştırıldı. BPE'nin gücü işte budur — yaygın ifadeler kendi tokenlarını alarak diziyi dramatik biçimde kısaltır.
Farklı Modeller, Farklı Tokenizer'lar#
Her yapay zeka model ailesi, farklı sözlüğe sahip kendi tokenizer'ını kullanır. Aynı metin farklı token sayıları üretebilir:
| Metin | cl100k_base (GPT-4) | o200k_base (GPT-4o/5) | UTF-8 Byte |
|---|---|---|---|
| Hello, how are you today? | 7 | 7 | 25 |
| Explain quantum computing in simple terms | 7 | 6 | 41 |
| 你好,请用中文解释一下什么是token | 15 | 9 | 47 |
| こんにちは、トークンとは何ですか? | 12 | 10 | 51 |
| Python fibonacci function (5 satır) | 28 | 28 | 92 |
Temel çıkarım: GPT-5'in tokenizer'ı (o200k_base), Çince ve Japonca için çok daha verimlidir — aynı Çince cümle GPT-4'te 15 token iken GPT-5'te sadece 9 token tutar. Sadece daha iyi bir tokenizer sayesinde %40 maliyet düşüşü demek.
Claude kendi tokenizer'ını, Gemini ise SentencePiece kullanır. Token sayıları sağlayıcıdan sağlayıcıya değişir — yani aynı prompt, hangi modeli kullandığınıza bağlı olarak farklı tutarlara mal olabilir.
Token Sayısı Faturanızı Nasıl Etkiler?#
Yapay zeka API'leri byte veya kelime başına değil, token başına ücretlendirir. Ve farklı diller çok farklı token verimliliğine sahiptir:
Dile göre token verimliliği (o200k_base)#
| Dil | Metin | Token | Byte | Byte/Token |
|---|---|---|---|---|
| İngilizce | "Hello, how are you today?" | 7 | 25 | 3.6 |
| Çince | "你好,今天怎么样?" | 5 | 27 | 5.4 |
| Japonca | "こんにちは" | 1 | 15 | 15.0 |
| Korece | "안녕하세요" | 2 | 15 | 7.5 |
| Kod | def fibonacci(n): (5 satır) | 28 | 92 | 3.3 |
GPT-5'in tokenizer'ında Japonca aslında en verimli token dilidir — こんにちは 15 byte'ı tek bir tokene sığdırır.
Gerçek maliyet karşılaştırması#
GPT-5 ($1.25/M giriş tokeni) üzerinden 1 milyon karakter metin işlediğinizi varsayalım:
| Dil | ~1M karakter başına token | Maliyet |
|---|---|---|
| İngilizce | ~330K | $0,41 |
| Çince | ~500K | $0,63 |
| Karışık (EN+CN) | ~400K | $0,50 |
Aynı karakter sayısında Çince metin, İngilizceden yaklaşık %50 daha pahalıya mal olur — çünkü her Çince karakter ortalamada daha fazla token tüketir.
Optimizasyon ipucu: karar vermeden önce modelleri karşılaştırın#
Farklı modellerin farklı tokenizer'ları, farklı fiyatları ve farklı yetenekleri vardır. Kullanım senaryonuz için en ucuz seçenek sizi şaşırtabilir.
Birleşik bir API geçidi (gateway) ile aynı promptu birden fazla modelde test edebilir, hem kaliteyi hem maliyeti karşılaştırabilirsiniz:
from openai import OpenAI
client = OpenAI(
api_key="your-crazyrouter-key",
base_url="https://crazyrouter.com/v1"
)
# Aynı promptu farklı modellerde test edin
for model in ["gpt-5", "gpt-5-mini", "deepseek-v3.2", "claude-sonnet-4"]:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Explain tokenization in 2 sentences"}],
max_tokens=100
)
usage = response.usage
print(f"{model}: {usage.prompt_tokens} in / {usage.completion_tokens} out")
Crazyrouter ile tek bir API anahtarıyla 627'den fazla modele erişebilir, kendi diliniz ve iş yükünüz için en maliyet-etkin modeli kolayca bulabilirsiniz.
Gelecek: Byte Düzeyinde Modeller Tokenların Yerini Alacak mı?#
2024 yılı sonlarında Meta, Byte Latent Transformer (BLT) üzerine bir araştırma yayımladı. Bu mimari, tokenizer'ı tamamen ortadan kaldırarak ham byte'ları doğrudan işliyor.
Byte düzeyinde modeller neden ilgi çekici:#
- Gerçek anlamda dilden bağımsız — İngilizce lehine tokenizer yanlılığı yok
- Sözlük dışı kelime (OOV) sorunu yok — herhangi bir byte dizisi geçerli girdidir
- Tokenizer-model uyumsuzluğu yok — model tam olarak yazdığınızı görür
2026'da tokenlar neden hâlâ baskın:#
- Byte dizileri 3-4 kat daha uzun — işleme maliyeti çok daha yüksek
- Tüm üretim modelleri (GPT-5, Claude, Gemini) hâlâ token tabanlı mimari kullanıyor
- BLT araştırma aşamasında — henüz ticari bir API olarak sunulmuyor
Pratik gerçeklik: Tokenlar en az 3-5 yıl daha standart olmaya devam edecek. Nasıl çalıştıklarını anlamak, yapay zeka API'lerini kullanan her geliştirici için zorunlu bir beceridir.
Hızlı Başvuru: Token vs Byte vs Karakter vs Kelime#
| Özellik | Byte | Karakter | Kelime | Token |
|---|---|---|---|---|
| Nedir? | Ham depolama birimi | İnsanın okuyabildiği sembol | Boşlukla ayrılan metin | Yapay zeka için alt-kelime birimi |
| Boyut | Her zaman 1 byte | 1-4 byte (UTF-8) | Değişken | Değişken |
| "Hello" | 5 | 5 | 1 | 1 |
| "你好" | 6 | 2 | 1 | 1 |
| "unbelievable" | 12 | 12 | 1 | 3 |
| Kullanan | Bilgisayarlar (depolama) | İnsanlar (okuma) | Arama motorları | Yapay zeka modelleri |
| Yapay zeka faturalandırması? | Hayır | Hayır | Hayır | Evet |
Temel ilişkiler:#
- 1 İngilizce token ≈ 4 karakter ≈ 4 byte ≈ 0,75 kelime
- 1 Çince token ≈ 1-3 karakter ≈ 3-9 byte ≈ 1-2 kelime
- 1.000 token ≈ 750 İngilizce kelime ≈ 4.000 karakter
Faydalı tokenizer araçları:#
- OpenAI Tokenizer — GPT modelleri için token sayımı
- tiktoken (Python) — programatik token sayımı
- Anthropic Token Counter — Claude modelleri için
SSS#
Token ve byte aynı şey midir?#
Hayır. Byte, bilgisayarınızın ham depolama birimidir (1 byte = 8 bit). Token ise yapay zeka modellerinin okuduğu işlenmiş birimdir. "Hello" metni 5 byte ama 1 tokendir. "你好" metni 6 byte ama yine 1 tokendir. Byte ve token arasındaki ilişki, dile ve kullanılan tokenizer'a bağlıdır.
Yapay zeka modelleri neden doğrudan ham byte işlemiyor?#
Verimlilik. "Hello" byte olarak 5 uzunluğunda bir dizidir; token olarak uzunluğu 1'dir. 1.000 kelimelik bir makale için byte düzeyinde işleme, 3-4 kat daha uzun diziler oluşturur. Transformer attention mekanizmasının hesaplama maliyeti O(n²) olduğundan, bu durum yapay zeka modellerini çok daha pahalı ve yavaş hale getirir.
Aynı metin tüm modellerde aynı sayıda token mı kullanır?#
Hayır. GPT-5 o200k_base tokenizer'ını, GPT-4 cl100k_base'i, Claude ise kendine özgü bir tokenizer'ı kullanır. Bir Çince cümle GPT-4'te 15 token olabilirken GPT-5'te sadece 9 token olabilir. Bu da aynı promptun farklı modellerde farklı tutarlara mal olabileceği anlamına gelir.
Çince metin yapay zeka API'lerinde neden İngilizceden daha pahalıdır?#
İki nedeni var. Birincisi, Çince karakterler UTF-8'de her biri 3 byte gerektirir (İngilizce harfler için 1 byte). İkincisi, modern tokenizer'larla bile Çince karakterler tokenlara daha az verimli şekilde sıkıştırılır. Tipik bir Çince cümle, aynı anlamı ifade eden bir İngilizce cümleden yaklaşık %50 daha fazla token kullanır.
Token maliyetlerimi nasıl düşürebilirim?#
Beş pratik yaklaşım: (1) Kısa ve öz promptlar yazın — her fazla kelime token maliyetidir. (2) Çıktı uzunluğunu sınırlamak için max_tokens kullanın. (3) Kalite gereksinimlerinizi karşılayan en ucuz modeli seçin. (4) Tekrarlanan sorguları önbelleğe alın. (5) Crazyrouter gibi bir API geçidi kullanarak tek bir API anahtarıyla 627'den fazla modelin fiyatlandırmasını kolayca karşılaştırın.
İleri Okuma#
- What Are Tokens in AI? A Beginner's Guide to AI API Pricing
- AI API Pricing Guide 2026: Complete Cost Breakdown
- How to Cut Your AI API Costs by 50%
- Context Window & Token Limits Explained
Byte ve token arasındaki farkı anlamak, yapay zeka maliyetlerinizi kontrol altına almanın ilk adımıdır. Daha fazla geliştirici rehberi ve güncel model fiyatlandırma verileri için Crazyrouter Blog'u ziyaret edin.





