
国内 Claude API 完整指南:接入方案对比、稳定落地与成本优化
国内 Claude API 完整指南:接入方案对比、稳定落地与成本优化#
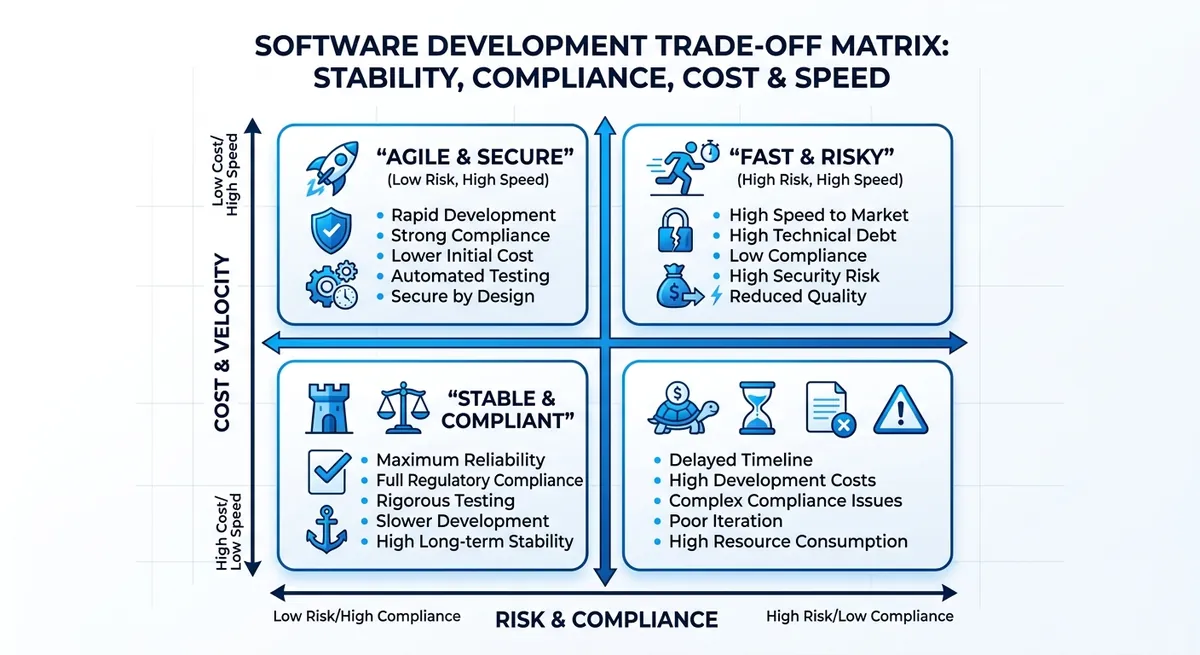
Teams often hit limits faster than expected: a free API tier at 60 requests per minute can stall testing, and burst traffic exposes weak retry logic fast. If you are deploying 国内 Claude API, the hard part is rarely writing prompts. The hard part is picking an access path that stays stable under load, passes compliance checks, and does not let token bills drift out of control.
This guide gives you a practical map by business stage: quick validation, early production, and multi-model scale-up. You will see how to choose between direct vendor access and a gateway route, how to design fallback across models, and how to keep migration cost low by staying OpenAI-SDK compatible. For example, Crazyrouter exposes Claude models through https://crazyrouter.com/v1, supports 300+ models, and publishes free-tier and paid-tier limits at 60 and 600 requests per minute. It also states pricing can be 30-50% lower than official channels and a 99.9% SLA, which is useful when cost and uptime both sit on your release checklist.
Start with the decision that drives everything else: which access path fits your current stage, not your future slide deck.
Claude API in China today: why “usable” is not “ready for production”#
A quick test can pass, but production fails for different reasons. For teams using Claude API in China, the real issue is system design, not a single API call. You need one plan across network path, compliance rules, runtime stability, and team-level access control.
Common mistakes with Claude API in China teams#
- Teams celebrate account signup and one successful request, then skip long-run checks like timeout rate, retry behavior, and fallback models.
- Teams compare only per-call price, then miss ops costs from incident handling, key rotation, traffic switching, and on-call time.
- Teams keep keys in shared scripts, which creates handoff risk when engineers change roles.
| Check point | “It works” stage | Production-ready stage |
|---|---|---|
| Network path | Manual retry by developer | Automatic retry + failover route |
| Stability target | No uptime target | Clear SLA target (example: 99.9%) |
| Throughput plan | Ad hoc requests | Defined limits (example: 60 RPM free, 600 RPM paid) |
| Cost model | Single call price only | Token cost + ops time + failure cost |
Source: Crazyrouter API and product docs (base URL, rate limits, SLA, pricing claim).
Go-live goals for Claude API in China: define four targets before release#
Set a hard availability threshold and alert rules before launch. Set compliance boundaries: what data can be sent, stored, or logged. Set security and permissions: scoped API keys, rotation cycle, audit trail. Set collaboration flow: owner per model route, incident playbook, and fallback policy.
Three Mainstream Paths: Official Direct, Cloud Hosted, and Domestic Relay#
If you are choosing a domestic Claude API route, match the path to your stage, not your long-term architecture plan. Teams lose time when they chase full control too early, then rebuild under pressure.
Official direct access for domestic Claude API control#
Official direct access fits teams that already run stable networking, billing, and incident response. You get full request-path control and clear vendor behavior. The tradeoff is operational pressure: network jitter, payment or account risk checks, and no easy hot backup when one provider fails. Use this path when your on-call team can fix failures fast and you can afford slower rollout speed.
Cloud-hosted and relay paths for domestic Claude API rollout#
Cloud-hosted access works when you need local support, one bill, and tighter integration with your current cloud stack. It reduces setup work, but model choice can be narrower.
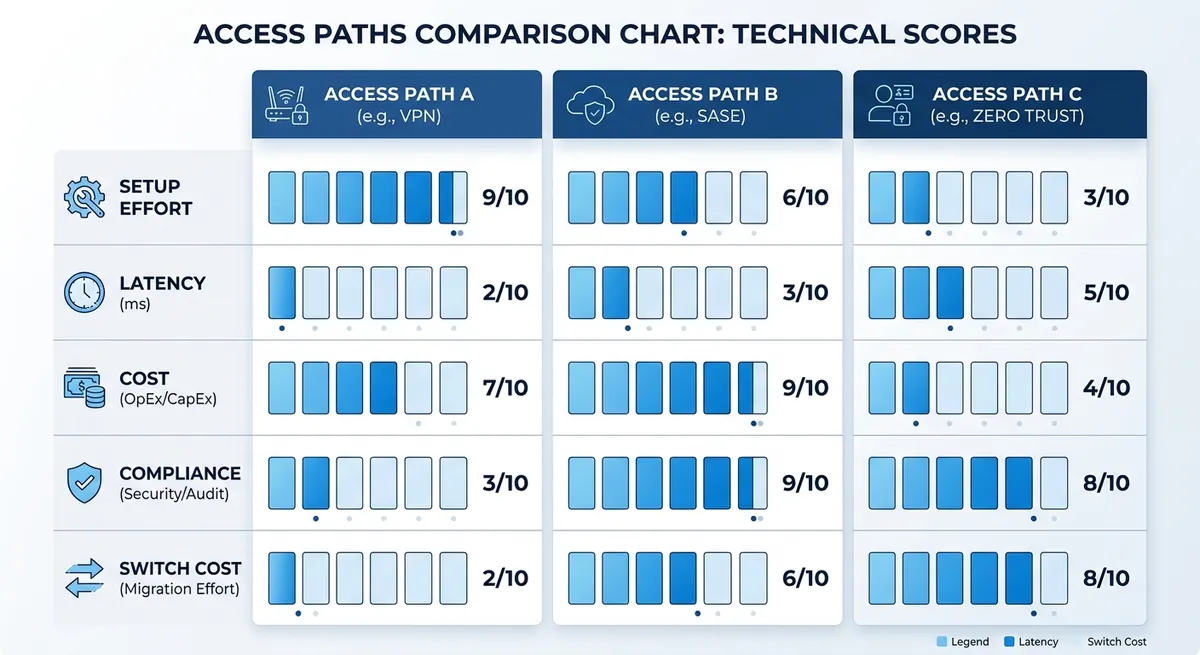
Relay platforms win on speed. You can switch from direct OpenAI SDK calls by changing base_url and api_key. For example, you can use https://crazyrouter.com/v1, keep OpenAI SDK calls, and access Claude with the same request shape. The published limits are 60 requests/min on free tier and 600 requests/min on paid tier, with a stated 99.9% SLA and 30-50% lower pricing than official channels.
| Path | Access difficulty | Latency stability | Cost predictability | Compliance control | Replaceability |
|---|---|---|---|---|---|
| Official direct | High | Medium to low in cross-border links | Medium | High | Medium |
| Cloud hosted | Medium | Medium to high in-region | High | Medium to high | Medium |
| Domestic relay | Low | Medium to high (depends on routing quality) | High if pricing is transparent | Medium (verify logs, key policy, data handling) | High with OpenAI-compatible API |
Source: Crazyrouter product and API docs (https://crazyrouter.com, https://crazyrouter.com/v1, published limits, SLA, and pricing claim).
A practical switch rule: validate fast on relay, move to cloud-hosted or mixed setup when traffic becomes stable, then use official direct for paths that need strict control or compliance proof.
How to Evaluate a Domestic Claude API Service for Long-Term Use#
Price gets attention, but uptime decides if your release survives. For a domestic Claude API, move from “it works” to a repeatable checklist. Your goal is stable output under real load, not a cheap test call.
Stability checks for a domestic Claude API#
Track four numbers every day: success rate, average latency, tail latency (P95/P99), and timeout rate. If a vendor only shares average latency, you still do not know what users see during peak traffic.
Run three tests before production:
- Load test with your real prompt size
- Peak simulation at your expected burst
- Continuous observation for at least 7 days, with incident notes
If you use a gateway route, verify published limits against your plan. Example: Crazyrouter lists 60 requests/min on free tier and 600 requests/min on paid tier, plus a 99.9% SLA.
<.-- IMAGE: Monitoring dashboard mockup with success rate and latency trend lines, including P95 spikes -->
Security and compliance checks for domestic Claude API operations#
Do not keep one key for all environments. Create separate keys for dev, staging, and prod. Limit each key to only the models and routes that app needs. Rotate keys on a schedule, not after a leak.
For logs, mask sensitive fields before storage. Keep audit trails for key creation, revocation, and permission changes. You need clear answers for “who changed what, and when.”
Cost and service checks for domestic Claude API vendors#
Low list price can hide retry and timeout waste. Build cost from request volume, context length, retry rate, and peak multiplier. Then compare vendor claims with your own test logs.
| Check item | What to ask | How to verify |
|---|---|---|
| Unit price | Input/output token pricing | Match invoice with token usage logs |
| Hidden cost | Retry and timeout billing | Replay failed requests in test window |
| Support speed | Human response SLA | Open 2-3 real tickets |
| Update pace | Model/version rollout cycle | Check changelog and model list history |
| Multi-model fallback | OpenAI-SDK compatibility | Swap only base_url in staging |
Source: Crazyrouter public docs and product pages (/v1, models, pricing, SLA, rate limits).
China Claude API rollout: from setup to the first observable request#
If you are shipping a Claude feature in China, speed is not the hard part. Stable calls, safe key handling, and clear logs decide whether your launch survives real traffic. For a practical 国内 Claude API path, you can keep your app on OpenAI SDK and route requests through https://crazyrouter.com/v1.
Step 1: Claude API in China preflight and security baseline#
Prepare four items before any code test: account, API key, network path, and alert target (email or chat bot). Put the key only in environment variables. Do not store it in code, Git history, or database rows.
Split environments: dev, staging, production. Use separate keys for each one. Keep permissions narrow. A service key for chat calls should not manage users or billing settings.
You can use a quick readiness checklist like this:
| Check item | Pass condition | Why this check exists |
|---|---|---|
| API auth | 401 never appears in smoke test | Catches bad key wiring early |
| Rate headroom | Your expected RPM stays below tier limit | Avoids 429 bursts at launch |
| Timeout | Client timeout set and tested | Prevents hanging requests |
| Alert route | Error alert reaches on-call in under 1 minute | Cuts blind spots during incidents |
Source: Crazyrouter API docs (/v1, 60 RPM free tier, 600 RPM paid tier, common 401/429/500 errors).
Step 2: domestic Claude API first request and quality validation#
Run one clean request, then run a repeat batch. Use claude-3-sonnet or claude-3-haiku and record response body, latency, status code, and token usage.
curl https://crazyrouter.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{"model":"claude-3-sonnet","messages":[{"role":"user","content":"Summarize this text in 3 bullets."}]}'
Validate three things right away: answer matches prompt intent, p95 latency stays steady in repeated runs, and retry logic handles 429 with exponential backoff. Add a user-facing fallback message for timeout or upstream failure so the UI does not freeze.
<.-- IMAGE: Request flow chart: client -> gateway -> model service -> logs and monitoring -->
Step 3: turn calls into an operated service for Claude API China traffic#
Now move from testing to operations. Build a small error-code dashboard for 401, 429, and 500. Set threshold alerts. Send daily and weekly summaries with request count, failure rate, and p95 latency by model.
Add version tags to prompts and request templates. Route changes through approval, then release by canary traffic. Treat every prompt or routing edit as a deploy event with rollback ready. This keeps your service stable while you tune cost and quality.
High availability and performance tuning: keep domestic Claude API stable under real traffic#
Performance tuning for domestic Claude API: prompt and call path#
Start by cutting waste in each request. Trim old context, cap output tokens, and block duplicate calls from the same user action. If your chat flow sends 2-3 repeated prompts per click, fix that before touching infra.
For high-frequency Q&A, add a short TTL cache. Cache by hash(prompt + role + model) for 30-120 seconds. Pair it with prompt templates so the same intent maps to the same input shape. This raises cache hits and cuts token burn.
You can use Crazyrouter with the OpenAI SDK by changing only base_url to https://crazyrouter.com/v1. That keeps migration cost low while routing Claude and other models through one key. Free tier is 60 requests/min, paid tier is 600 requests/min, so set your local limiter below those numbers to avoid burst errors.
High availability for China Claude API traffic: retry, rate limit, circuit break, and degrade#
Retry only on retryable errors. Do not retry bad requests.
| Error type | Example code | Retry? | Action |
|---|---|---|---|
| Rate limit | 429 | Yes | Exponential backoff, jitter, max 3 tries |
| Server fault | 500 | Yes | Fast retry, then switch backup channel |
| Auth/config | 401 | No | Fail fast, alert, block bad key |
| Invalid request | 400-class input issue | No | Return fix hint to caller |
Source: Crazyrouter API docs (/v1), rate limits and error examples.
When failure rises, protect the core path. Keep paid chat and support bots online; degrade non-core features like long summaries or image extras. Add a circuit breaker per upstream model and auto-fallback to a cheaper or faster model when timeout spikes. The goal is simple: keep useful answers flowing, even during partial failure.
<.-- IMAGE: HA architecture with primary route, backup route, circuit breaker, and degrade path -->
Team collaboration and multi-account control: reduce bans, leaks, and misoperations#
When a team shares one key and one browser profile, trouble starts fast. One wrong model switch can break production. One leaked key can drain balance. Shared root keys are the main failure point.
Domestic Claude API governance: who can view, change, and release#
Set clear role split before traffic grows. Keep admin rights with a small owner group. Let developers run and test prompts. Give auditors read-only access to logs, billing, and key changes.
| Role | Can view | Can change | Can release |
|---|---|---|---|
| Admin | All projects, keys, logs | Keys, routing, permissions | Yes |
| Developer | Assigned projects, usage logs | Prompt config in dev/test | No |
| Auditor | Logs, billing, change history | No | No |
Source: role split and audit practice based on the provided team-governance requirements.
Domestic Claude API multi-account safety: environment split and risk isolation#
Tools like DICloak let you split dev, test, and ops accounts into separate browser fingerprints and proxy routes. That cuts account-link risk from shared devices and mixed logins. You can map one environment to one identity, then lock cross-environment access.
You can use DICloak permission controls plus approval flow to stop risky actions, like changing production keys without review. Session isolation and operation trails help you trace who changed what and when, then roll back faster after an error.
Pair this with your API gateway policy: one key per service, short expiry, and log checks each day. If you run domestic Claude API through an OpenAI-compatible endpoint, this setup keeps team actions controllable and auditable.
<.-- IMAGE: Team permission matrix showing visibility scope and action boundaries by role -->
Common Issues and Troubleshooting: What to Check When Claude API Fails in China#
When alerts fire on a Claude API in China setup, speed comes from order, not guesswork. Check network path and API key before touching code. <.-- IMAGE: incident flow from alert to recovery with checkpoints: connectivity, auth, limits, payload, fallback -->
Error triage order for Claude API in China#
Use this order every time:
| Check item | What to verify | Fast signal |
|---|---|---|
| Connectivity | https://crazyrouter.com/v1 reachable from your runtime | timeout or DNS failure |
| Auth | Authorization: Bearer ... is valid | 401 invalid_api_key |
| Rate limit | traffic spike vs tier cap | 429 rate_limit_exceeded |
| Request shape | model name, messages JSON, token limits | 400/500 patterns |
| Upstream health | model/channel status in logs | rising 5xx or retries |
Source: Crazyrouter API docs (/v1, 401/429/500 errors, 60 rpm free, 600 rpm paid).
Then replay request logs by timeline. Find the first bad request, not the loudest one. In practice, the first anomaly often shows key expiry, malformed payload, or a sudden burst past 60/600 rpm.
Incident plan for China-based Claude API: degrade, switch, review#
Pre-set backup models and backup routes. You can use Claude as primary, then fail over to gpt-4 or gemini-pro on the same OpenAI-SDK flow by switching model name and keeping one gateway base URL. Keep core paths alive, even with lower quality output.
After recovery, record three items: root cause, blast-radius control, and permanent fix with owner and deadline.
Cost Budget and Selection: How to Use a China Claude API by Stage at the Lowest Cost#
Stage-based decisions for a domestic Claude API: from test to scale#
Most teams overspend when they design for scale before they prove value. Pick the path for your current stage, not your future org chart.
| Team stage | Main goal | Recommended access path | Budget guardrails | Why this fits now |
|---|---|---|---|---|
| Solo or small team | Ship a usable feature fast | OpenAI-compatible gateway with Claude model access | Start with free tier 60 req/min, then paid 600 req/min | You change only base_url, keep existing SDK calls, and avoid early infra work |
| Enterprise team | Stable uptime, audit trail, fast switching | Gateway plus model routing and logs | Track success rate, latency, token spend per model | You can route across 300+ models and keep fallback ready during upstream issues |
Use one API key and one endpoint (https://crazyrouter.com/v1) to keep migration cost low. If your traffic is still uncertain, a gateway route with posted 30-50% lower pricing can reduce burn while you test demand.
One-page domestic Claude API decision checklist you can run today#
Set targets in numbers: p95 latency, success rate, monthly budget cap, and compliance checks. Define one primary model path and one backup path. Monitor four items weekly: request volume, error rate (401/429/500), token cost, and fallback hit rate. Run a short review every two weeks, then adjust routing weights, not your whole stack.
<.-- IMAGE: one-page decision checklist template with latency, budget, fallback, and review cadence fields -->
Frequently Asked Questions#
国内 Claude API 一定要通过中转平台吗?#
不一定。是否使用中转平台,可以按四个条件快速决策:第一,网络是否能稳定直连官方端点;第二,是否有数据合规和审计要求;第三,团队是否具备网关、鉴权、监控与告警能力;第四,上线时间是否很紧。若你能稳定直连、具备运维能力、且合规允许,国内 Claude API 可直接接入。若网络抖动明显、需统一审计、或要一周内上线,中转方案通常更稳、更快交付。
国内 Claude API 如何兼顾速度与稳定性?#
要同时做到快和稳,建议把国内 Claude API 放在“保护层”后面:先做请求缓存,减少重复调用;再做重试,限定次数并加指数退避,避免雪崩;加限流和并发控制,保护上游配额;设置降级策略,如切到短回答或备用模型;做多通道备援,主通道失败时自动切换。持续监控 p95 延迟、超时率、重试率和成功率,按阈值自动告警和回滚。
国内 Claude API 的成本主要由哪些因素决定?#
成本不只看单价。国内 Claude API 的总成本通常由五项组成:输入上下文长度、输出长度、失败后重试次数、峰值流量带来的扩容成本、以及工程侧的缓存命中率。比如长上下文会直接拉高每次调用费用;重试率高会让同一请求被重复计费;峰值时没有限流会触发更多失败与重试。先做 prompt 压缩、输出长度控制、缓存复用,再谈模型切换,往往更省钱。
国内 Claude API 在团队协作中如何避免密钥泄露?#
先定规则,再上工具。把国内 Claude API 密钥放进密钥管理系统,不要写进代码、文档或聊天工具。按角色分级授权:开发、测试、运维用不同密钥和不同权限。设置定期轮换和离职即失效流程,减少长期暴露风险。环境要隔离,开发与生产严格分开。所有调用和变更都记录审计日志,异常下载、异常调用量、异常 IP 立即告警并自动冻结相关密钥。
国内 Claude API 出现调用超时时应该先排查什么?#
先查最基础的两项:网络连通和超时配置。确认 DNS、出口链路、TLS 握手是否正常,再看 connect timeout 与 read timeout 是否过短。第二步查配额与并发:是否触发速率限制、是否瞬时并发过高。第三步查请求本身:上下文是否过长、是否携带大附件、是否开启了不必要的流式返回。按“网络→配置→配额→参数”顺序排查,能最快定位国内 Claude API 超时根因。
国内 Claude API 适合哪些业务场景优先落地?#
优先做“价值清晰、收益可量化、流程可闭环”的场景。国内 Claude API 常见优先项有三类:客服辅助(自动总结工单、生成回复草稿)、内容生产(营销文案、知识库问答)、研发提效(代码解释、测试用例草拟、文档整理)。这些场景容易设 KPI,比如首响时长、人工处理时长、一次解决率。先从单团队试点,跑通指标和质检,再逐步扩到更多业务线。
A strong domestic Claude API strategy depends on choosing compliant access routes while designing for reliability, latency stability, and clear operational ownership from the start. The core takeaway is to launch quickly with a minimal viable integration, then systematically improve monitoring, cost governance, and risk controls so the capability can scale sustainably in production. 先用清单完成一次最小可用接入,再对照监控与治理项做第二轮优化,逐步搭建稳定可持续的国内 Claude API 能力。


