
"トークンとバイトの違いとは?AIが実際にテキストを処理する仕組みを徹底解説"
トークンとバイトの違いとは?AIが実際にテキストを処理する仕組みを徹底解説#
GPT-5に「你好 Hello」と入力してみてください。7文字のテキストですが、モデルが実際に処理するのは2トークンです。そして課金はトークン数に基づいて行われます。文字数ではありません。
一方、コンピュータ上では同じテキストが12バイトとして保存されています。
では、バイト・文字・トークンの違いは何でしょうか? なぜAIは生のバイトではなくトークンを使うのでしょうか? そして、なぜ同じ内容の文章でも中国語のほうが英語より高くなるのでしょうか?
この記事では、ハードドライブ上のバイトからAIが実際に読み取るトークンまで、テキスト処理の全パイプラインを解説します。
最初の一歩:バイトとは何か?#
バイトはコンピュータがデータを保存する最小単位です。1バイト = 8ビット = 0〜255の数値で表されます。
テキストをファイルに保存する際、コンピュータはUTF-8という規格を使って各文字をバイト列にエンコードします:
| Character | UTF-8 Bytes | Byte Count | Hex |
|---|---|---|---|
H | 72 | 1 | 48 |
e | 101 | 1 | 65 |
你 | 228, 189, 160 | 3 | e4 bd a0 |
好 | 229, 165, 189 | 3 | e5 a5 bd |
🚀 | 240, 159, 154, 128 | 4 | f0 9f 9a 80 |
重要なパターン:
- 英字:各1バイト
- 中国語・日本語・韓国語の文字:各3バイト
- 絵文字:各4バイト
つまり「你好 Hello」というテキストは12バイトで保存されます:
你 好 [space] H e l l o
e4 bd a0 e5 a5 bd 20 48 65 6c 6c 6f
(3 bytes) (3 bytes) (1) (1) (1) (1) (1) (1) = 12 bytes
バイトはコンピュータがテキストを保存する方法です。しかし、AIモデルはバイトを直接読み取るわけではありません。
4つの階層:バイト → 文字 → 単語 → トークン#
テキストは4つの異なるレベルで分解できます。それぞれのレベルでデータのグループ化の方法が異なります:
| レベル | "Hello, World" | 個数 | 説明 |
|---|---|---|---|
| バイト | 48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 | 12 | 生のストレージ単位 |
| 文字 | H e l l o , ␣ W o r l d | 12 | 人間が読める文字 |
| 単語 | Hello, World | 2 | スペース区切りの単位 |
| トークン | Hello , World | 3 | AIが実際に処理する単位 |
中国語の場合も見てみましょう:
| レベル | "你好世界" | 個数 | 説明 |
|---|---|---|---|
| バイト | e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c | 12 | 1文字あたり3バイト |
| 文字 | 你 好 世 界 | 4 | 各文字 = 1つの漢字 |
| 単語 | 你好 世界 | 2 | 意味に基づく分割 |
| トークン | 你好 世界 | 2 | トークナイザーに依存 |
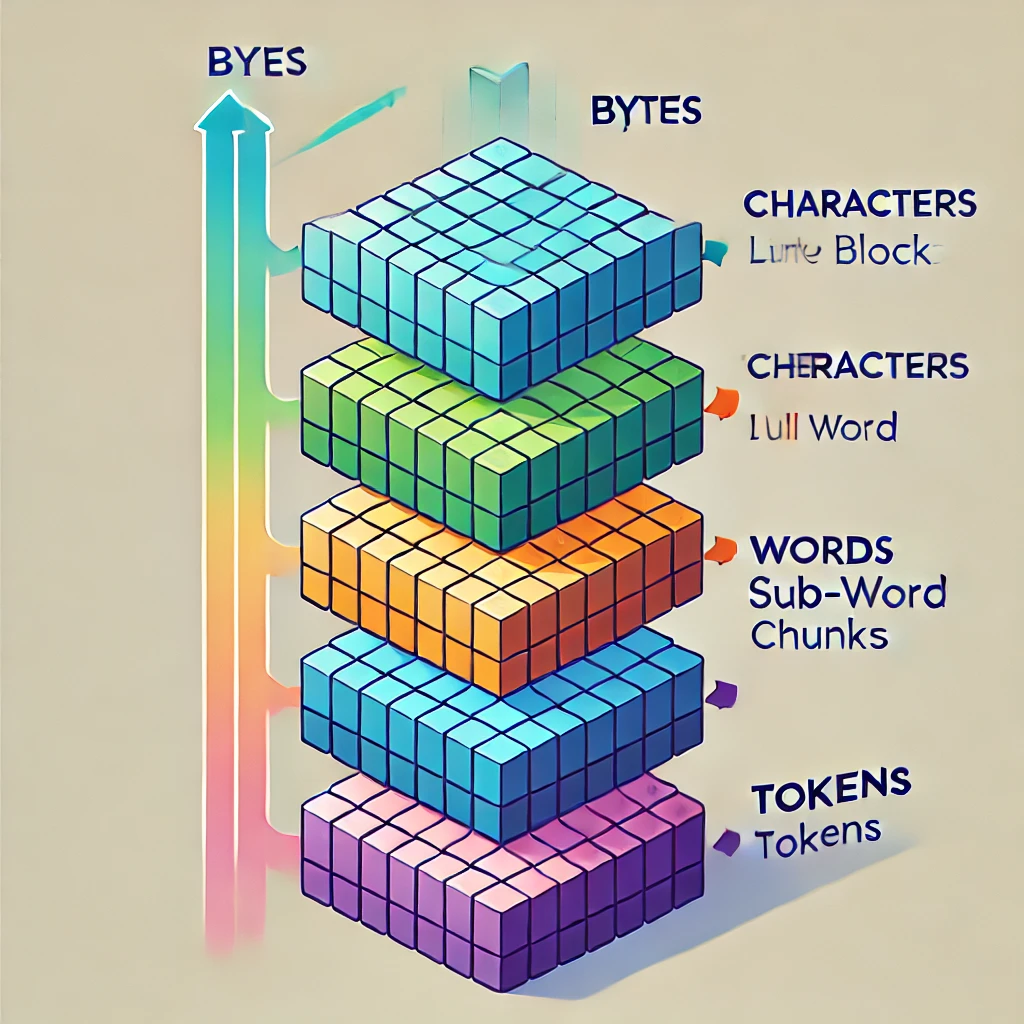
ここで最も重要なポイント:トークンはバイトでも文字でも単語でもありません。 語彙サイズとシーケンス長のバランスを取る「サブワード単位」という中間的な存在です。
なぜバイトや単語をそのまま使わないのか?#
バイトや単語のほうがシンプルなのに、なぜAIはわざわざトークンという仕組みを作ったのでしょうか? それは、どちらの極端なアプローチにも深刻な問題があるからです。
バイトの問題:シーケンスが長すぎる#
「Hello」は5バイトです。1,000語のブログ記事は約5,000バイト。小説になると約500,000バイトにもなります。
AIモデルはシーケンス内のすべての位置間の関係性を処理する必要があります。計算コストはシーケンス長に対して二次的に増加します(アテンションのO(n²))。シーケンス長が2倍になると、計算コストは4倍に跳ね上がります。
生のバイトを使うとシーケンスが3〜4倍長くなり、AIモデルの処理速度が実用に耐えないレベルまで低下してしまいます。
単語の問題:語彙が爆発する#
英語には一般的に使われる単語だけで17万語以上あります。これに専門用語、固有名詞、URL、コード、さらに他言語を加えると、数百万語の語彙が必要になります。
巨大な語彙は以下の問題を引き起こします:
- 膨大な埋め込みテーブル(メモリを大量に消費)
- 大半の単語は出現頻度が低く、モデルが十分に学習できない
- 語彙にない単語はまったく処理できない(「OOV(未知語)」問題)
トークン:最適なバランス#
トークンはテキストをサブワード単位に分割します。バイトより大きく、単語より小さい断片です:
"unbelievable" → ["un", "bel", "ievable"] (3 tokens)
"tokenization" → ["Token", "ization"] (2 tokens)
"Hello" → ["Hello"] (1 token — 頻出語なのでそのまま1トークン)
これにより以下のメリットが得られます:
- 短いシーケンス(効率的な処理)
- 小さな語彙(数百万語ではなく、約10万〜20万エントリ)
- 未知語なし(あらゆるテキストを既知のサブワードに分解可能)
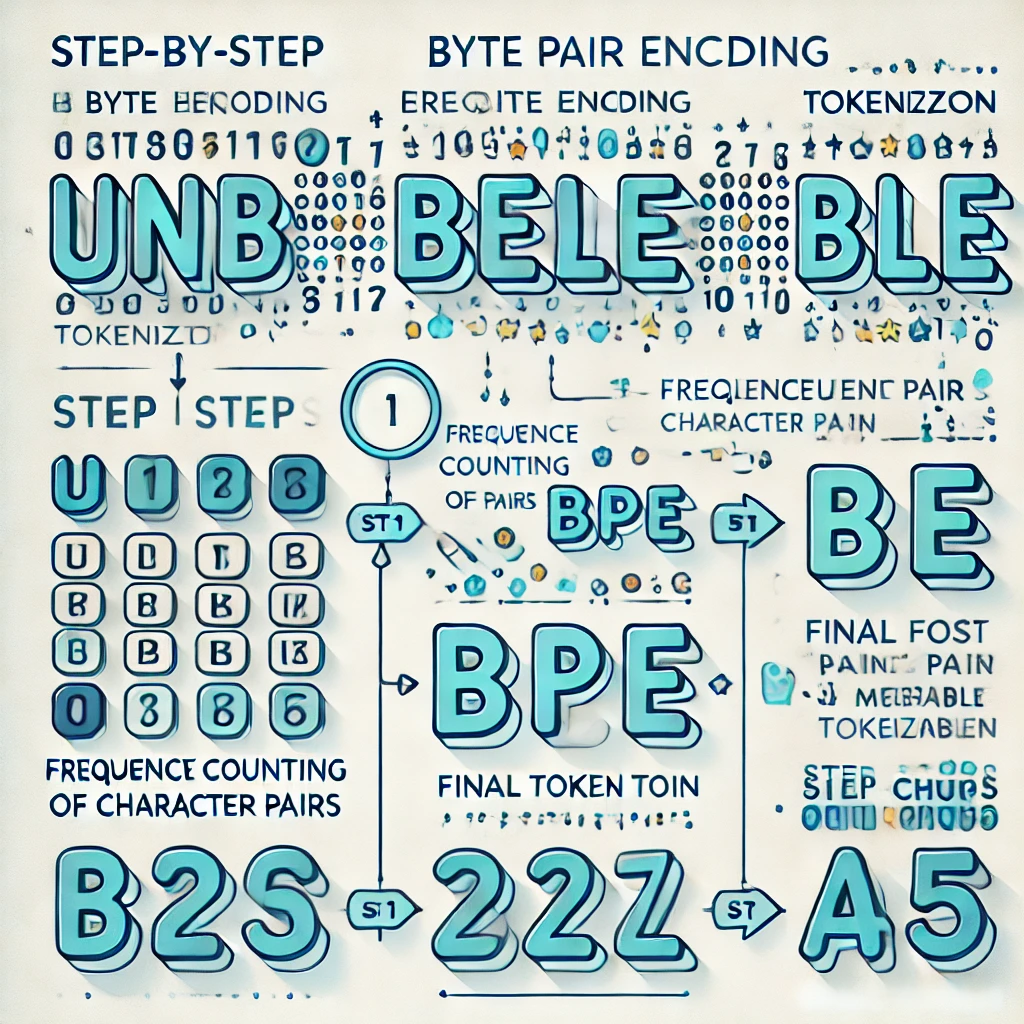
BPEトークナイゼーションの仕組み#
最新のLLMのほとんどは、トークナイザーの構築にByte Pair Encoding(BPE) の一種を使用しています。その仕組みを見ていきましょう。
ステップ1:個々の文字から始める#
学習用テキストをすべて1文字ずつに分割します:
"low" → ["l", "o", "w"]
"lower" → ["l", "o", "w", "e", "r"]
"newest" → ["n", "e", "w", "e", "s", "t"]
ステップ2:最も頻出するペアを数える#
隣接する文字ペアをすべて調べ、最も出現頻度が高いものを見つけます:
("l", "o") appears 2 times ← 最多
("o", "w") appears 2 times
("e", "w") appears 1 time
...
ステップ3:最頻出ペアをマージする#
("l", "o")のすべての出現箇所を新しいトークン「lo」に置き換えます:
"low" → ["lo", "w"]
"lower" → ["lo", "w", "e", "r"]
ステップ4:数千回繰り返す#
目標の語彙サイズ(通常5万〜20万トークン)に達するまで、カウントとマージを繰り返します。
多くのマージを経て、「the」「Hello」「you」のような頻出語は1つのトークンになり、珍しい単語はサブワードに分割されるようになります。
tiktokenで実際に確認してみよう#
OpenAIのtiktokenライブラリを使えば、GPT-5がテキストをどのようにトークナイズするか正確に確認できます:
import tiktoken
# o200k_base is used by GPT-4o and GPT-5
enc = tiktoken.get_encoding("o200k_base")
text = "你好 Hello"
tokens = enc.encode(text)
token_strings = [enc.decode([t]) for t in tokens]
print(f"Text: {text}")
print(f"UTF-8 bytes: {len(text.encode('utf-8'))}")
print(f"Tokens ({len(tokens)}): {token_strings}")
print(f"Token IDs: {tokens}")
実行結果:#
Text: 你好 Hello
UTF-8 bytes: 12
Tokens (2): ['你好', ' Hello']
Token IDs: [177519, 32949]
12バイトがたった2トークンに圧縮されました。これがBPEの威力です。頻出するフレーズには専用のトークンが割り当てられ、シーケンスが大幅に短縮されます。
モデルごとに異なるトークナイザー#
AIモデルのファミリーごとに独自のトークナイザーと語彙を持っています。同じテキストでもモデルによってトークン数が異なります:
| Text | cl100k_base (GPT-4) | o200k_base (GPT-4o/5) | UTF-8 Bytes |
|---|---|---|---|
| Hello, how are you today? | 7 | 7 | 25 |
| Explain quantum computing in simple terms | 7 | 6 | 41 |
| 你好,请用中文解释一下什么是token | 15 | 9 | 47 |
| こんにちは、トークンとは何ですか? | 12 | 10 | 51 |
| Python fibonacci function (5 lines) | 28 | 28 | 92 |
重要なポイント:GPT-5のトークナイザー(o200k_base)は中国語と日本語に対して大幅に効率的です。 同じ中国語の文でもGPT-4では15トークンだったものが、GPT-5では9トークンで済みます。トークナイザーの改善だけで40%のコスト削減になるわけです。
Claudeは独自のトークナイザーを使用し、GeminiはSentencePieceを採用しています。トークン数はプロバイダーによって異なるため、同じプロンプトでもモデルごとにコストが変わる可能性があります。
トークン数が請求額に与える影響#
AI APIはバイト単位でも単語単位でもなく、トークン単位で課金されます。そして、言語によってトークン効率に大きな差があります。
言語別トークン効率(o200k_base)#
| Language | Text | Tokens | Bytes | Bytes/Token |
|---|---|---|---|---|
| English | "Hello, how are you today?" | 7 | 25 | 3.6 |
| Chinese | "你好,今天怎么样?" | 5 | 27 | 5.4 |
| Japanese | "こんにちは" | 1 | 15 | 15.0 |
| Korean | "안녕하세요" | 2 | 15 | 7.5 |
| Code | def fibonacci(n): (5 lines) | 28 | 92 | 3.3 |
GPT-5のトークナイザーでは、日本語は実は最もトークン効率の高い言語です。「こんにちは」という15バイトのテキストがたった1トークンに圧縮されます。
実際のコスト比較#
GPT-5(入力 $1.25/100万トークン)で100万文字のテキストを処理した場合を考えてみましょう:
| Language | ~Tokens per 1M chars | Cost |
|---|---|---|
| English | ~330K | $0.41 |
| Chinese | ~500K | $0.63 |
| Mixed (EN+CN) | ~400K | $0.50 |
中国語テキストは同じ文字数でも英語に比べて約50%高コストになります。これは各中国語文字が平均的により多くのトークンを消費するためです。
最適化のヒント:コミットする前にモデルを比較しよう#
モデルごとにトークナイザー、価格、性能が異なります。ユースケースに最適なコスパの選択肢は意外かもしれません。
統合APIゲートウェイを使えば、同じプロンプトを複数のモデルで実行し、品質とコストの両面で比較できます:
from openai import OpenAI
client = OpenAI(
api_key="your-crazyrouter-key",
base_url="https://crazyrouter.com/v1"
)
# Test the same prompt across models
for model in ["gpt-5", "gpt-5-mini", "deepseek-v3.2", "claude-sonnet-4"]:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Explain tokenization in 2 sentences"}],
max_tokens=100
)
usage = response.usage
print(f"{model}: {usage.prompt_tokens} in / {usage.completion_tokens} out")
Crazyrouterなら、1つのAPIキーで627以上のモデルにアクセスできるため、お使いの言語やワークロードに最もコスト効率の良いモデルを簡単に見つけることができます。
未来の展望:バイトレベルモデルはトークンを置き換えるか?#
2024年末、MetaはByte Latent Transformer(BLT) に関する研究を発表しました。これはトークナイザーを完全に排除し、生のバイトを直接処理するモデルアーキテクチャです。
バイトレベルモデルが注目される理由:#
- 真の言語非依存性 — 英語偏重のトークナイザーバイアスがない
- 未知語問題がゼロ — あらゆるバイト列が有効な入力になる
- トークナイザーとモデルの不整合がない — 入力したテキストがそのままモデルに見える
2026年現在、トークンが依然として主流である理由:#
- バイトシーケンスは3〜4倍長い — 処理コストが大幅に増加
- すべての本番モデル(GPT-5、Claude、Gemini)がトークンベースのアーキテクチャを使用
- BLTは研究段階 — 商用APIとしてはまだ提供されていない
現実的な見通し:トークンは少なくとも今後3〜5年はスタンダードであり続けるでしょう。トークンの仕組みを理解することは、AI APIを使うすべての開発者にとって必須のスキルです。
クイックリファレンス:トークン vs バイト vs 文字 vs 単語#
| プロパティ | バイト | 文字 | 単語 | トークン |
|---|---|---|---|---|
| 定義 | 生のストレージ単位 | 人間が読める記号 | スペース区切りのテキスト | AI用のサブワード単位 |
| サイズ | 常に1バイト | 1〜4バイト(UTF-8) | 可変 | 可変 |
| "Hello" | 5 | 5 | 1 | 1 |
| "你好" | 6 | 2 | 1 | 1 |
| "unbelievable" | 12 | 12 | 1 | 3 |
| 使用者 | コンピュータ(保存) | 人間(読み書き) | 検索エンジン | AIモデル |
| AI課金の基準? | いいえ | いいえ | いいえ | はい |
重要な換算目安:#
- 1英語トークン ≈ 4文字 ≈ 4バイト ≈ 0.75語
- 1中国語トークン ≈ 1〜3文字 ≈ 3〜9バイト ≈ 1〜2語
- 1,000トークン ≈ 英語750語 ≈ 4,000文字
便利なトークナイザーツール:#
- OpenAI Tokenizer — GPTモデルのトークン数を確認
- tiktoken(Python) — プログラムでのトークンカウント
- Anthropic Token Counter — Claudeモデル用
よくある質問#
トークンとバイトは同じものですか?#
いいえ。バイトはコンピュータの生のストレージ単位(1バイト = 8ビット)です。トークンはAIモデルが読み取る処理単位です。「Hello」は5バイトですが1トークン、「你好」は6バイトですが同じく1トークンです。バイトとトークンの対応関係は、言語や使用するトークナイザーによって異なります。
なぜAIモデルは生のバイトを処理しないのですか?#
効率の問題です。「Hello」はバイトとしてはシーケンス長5ですが、トークンとしては長さ1になります。1,000語の記事の場合、バイトレベル処理ではシーケンスが3〜4倍長くなります。Transformerのアテンション計算コストはO(n²)であるため、処理が大幅に遅く、高コストになってしまいます。
同じテキストはすべてのモデルで同じトークン数になりますか?#
いいえ。GPT-5はo200k_base、GPT-4はcl100k_base、Claudeは独自のトークナイザーを使用しています。中国語の文がGPT-4で15トークン、GPT-5では9トークンということもあります。つまり、同じプロンプトでもモデルによってコストが異なる可能性があります。
なぜ中国語テキストはAI APIで英語より高コストなのですか?#
2つの理由があります。第一に、中国語の各文字はUTF-8で3バイト必要です(英字は1バイト)。第二に、最新のトークナイザーでも中国語の文字はトークンへの圧縮効率が英語より低いためです。一般的に、中国語の文は同じ意味を伝える英語の文より約50%多くのトークンを消費します。
トークンコストを削減するにはどうすればよいですか?#
5つの実践的なアプローチがあります:(1)プロンプトを簡潔にする — 余分な単語はすべてトークンとしてコストになります。(2)max_tokensで出力長を制限する。(3)品質基準を満たす最も安価なモデルを選ぶ。(4)繰り返しのクエリをキャッシュする。(5)CrazyrouterのようなAPIゲートウェイを使い、1つのAPIキーで627以上のモデルの価格を簡単に比較する。
関連記事#
- What Are Tokens in AI? A Beginner's Guide to AI API Pricing
- AI API Pricing Guide 2026: Complete Cost Breakdown
- How to Cut Your AI API Costs by 50%
- Context Window & Token Limits Explained
バイトとトークンの違いを理解することは、AIコストをコントロールするための第一歩です。最新のモデル価格データや開発者向けガイドは、Crazyrouter Blogをご覧ください。


