Tokens vs Bytes in AI: What LLMs Actually See When You Type
Understand the real difference between bytes, characters, words, and tokens in AI. Learn how BPE tokenization works, why Chinese costs more than English, and how to optimize your token usage.
Tokens vs Bytes in AI: What LLMs Actually See When You Type#
You type "你好 Hello" into GPT-5. That's 7 characters. But the model processes it as 2 tokens — and your bill is based on those tokens, not the characters.
Meanwhile, your computer stores that same text as 12 bytes.
So what's the difference between bytes, characters, and tokens? Why does AI use tokens instead of raw bytes? And why does the same sentence cost more in Chinese than in English?
This guide explains the full pipeline — from the bytes on your hard drive to the tokens that AI actually reads.
Start at the Bottom: What Is a Byte?#
A byte is the smallest unit of data your computer stores. One byte = 8 bits = a number from 0 to 255.
When you save text to a file, your computer encodes each character into bytes using a standard called UTF-8:
| Character | UTF-8 Bytes | Byte Count | Hex |
|---|---|---|---|
H | 72 | 1 | 48 |
e | 101 | 1 | 65 |
你 | 228, 189, 160 | 3 | e4 bd a0 |
好 | 229, 165, 189 | 3 | e5 a5 bd |
🚀 | 240, 159, 154, 128 | 4 | f0 9f 9a 80 |
Key pattern:
- English letters: 1 byte each
- Chinese/Japanese/Korean characters: 3 bytes each
- Emojis: 4 bytes each
So the text "你好 Hello" is stored as 12 bytes:
你 好 [space] H e l l o
e4 bd a0 e5 a5 bd 20 48 65 6c 6c 6f
(3 bytes) (3 bytes) (1) (1) (1) (1) (1) (1) = 12 bytes
Bytes are how computers store text. But AI models don't read bytes directly.
The Four Levels: Bytes → Characters → Words → Tokens#
There are four ways to break down a piece of text. Each level groups the data differently:
| Level | "Hello, World" | Count | Description |
|---|---|---|---|
| Bytes | 48 65 6c 6c 6f 2c 20 57 6f 72 6c 64 | 12 | Raw storage units |
| Characters | H e l l o , ␣ W o r l d | 12 | Human-readable letters |
| Words | Hello, World | 2 | Space-separated units |
| Tokens | Hello , World | 3 | What AI actually processes |
Now the same comparison with Chinese:
| Level | "你好世界" | Count | Description |
|---|---|---|---|
| Bytes | e4 bd a0 e5 a5 bd e4 b8 96 e7 95 8c | 12 | 3 bytes per character |
| Characters | 你 好 世 界 | 4 | Each character = 1 Chinese word |
| Words | 你好 世界 | 2 | Meaning-based segmentation |
| Tokens | 你好 世界 | 2 | Depends on the tokenizer |
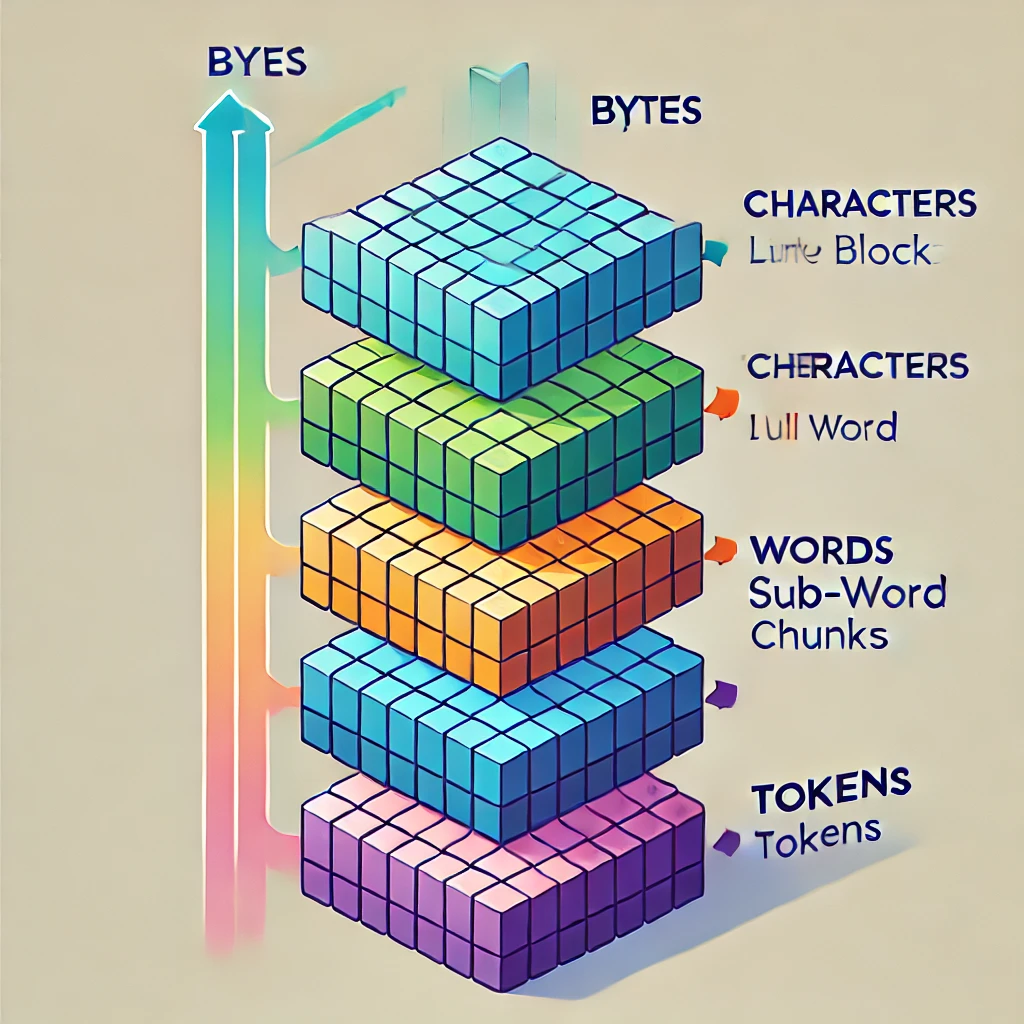
The critical insight: tokens are not bytes, not characters, and not words. They're a middle ground — sub-word units that balance vocabulary size with sequence length.
Why Not Just Use Bytes or Words?#
If bytes and words are simpler, why did AI invent tokens? Because both extremes have serious problems:
Problem with bytes: sequences are too long#
"Hello" is 5 bytes. A 1,000-word blog post is ~5,000 bytes. A novel is ~500,000 bytes.
An AI model needs to process the relationships between all positions in a sequence. The computational cost grows quadratically with sequence length (O(n²) for attention). Double the sequence length → 4x the compute cost.
Using raw bytes would make sequences 3-4x longer than necessary, making AI models unaffordably slow.
Problem with words: vocabulary explodes#
English has over 170,000 words in common use. Add technical terms, names, URLs, code, and other languages — you'd need a vocabulary of millions.
A huge vocabulary means:
- A massive embedding table (memory-hungry)
- Most words are rare, so the model barely learns them
- Any word not in the vocabulary is completely unknown (the "OOV" problem)
Tokens: the sweet spot#
Tokens split text into sub-word units — pieces that are larger than bytes but smaller than words:
"unbelievable" → ["un", "bel", "ievable"] (3 tokens)
"tokenization" → ["Token", "ization"] (2 tokens)
"Hello" → ["Hello"] (1 token — common enough to keep whole)
This gives you:
- Short sequences (efficient processing)
- Small vocabulary (~100K-200K entries, not millions)
- No unknown words (any text can be broken into known sub-words)
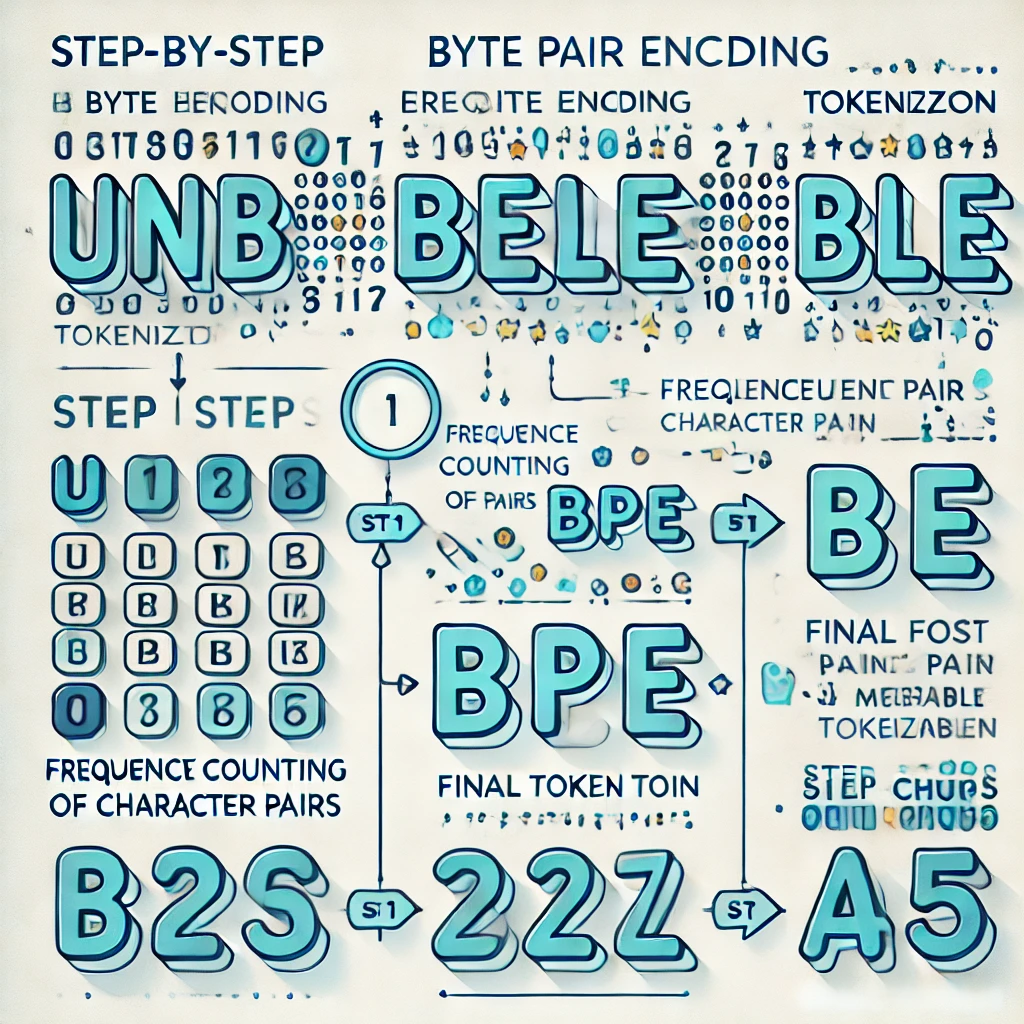
How BPE Tokenization Actually Works#
Most modern LLMs use a variant of Byte Pair Encoding (BPE) to build their tokenizer. Here's how it works:
Step 1: Start with individual characters#
Take your training text and split everything into single characters:
"low" → ["l", "o", "w"]
"lower" → ["l", "o", "w", "e", "r"]
"newest" → ["n", "e", "w", "e", "s", "t"]
Step 2: Count the most frequent pair#
Look at all adjacent character pairs and find the most common one:
("l", "o") appears 2 times ← most frequent
("o", "w") appears 2 times
("e", "w") appears 1 time
...
Step 3: Merge the most frequent pair#
Replace all occurrences of ("l", "o") with a new token "lo":
"low" → ["lo", "w"]
"lower" → ["lo", "w", "e", "r"]
Step 4: Repeat thousands of times#
Keep counting and merging until you reach your target vocabulary size (typically 50K-200K tokens).
After many merges, common words like "the", "Hello", and "you" become single tokens, while rare words get split into sub-word pieces.
See it yourself with tiktoken#
You can inspect exactly how GPT-5 tokenizes any text using OpenAI's tiktoken library:
import tiktoken
# o200k_base is used by GPT-4o and GPT-5
enc = tiktoken.get_encoding("o200k_base")
text = "你好 Hello"
tokens = enc.encode(text)
token_strings = [enc.decode([t]) for t in tokens]
print(f"Text: {text}")
print(f"UTF-8 bytes: {len(text.encode('utf-8'))}")
print(f"Tokens ({len(tokens)}): {token_strings}")
print(f"Token IDs: {tokens}")
Tested output:#
Text: 你好 Hello
UTF-8 bytes: 12
Tokens (2): ['你好', ' Hello']
Token IDs: [177519, 32949]
12 bytes compressed into just 2 tokens. That's the power of BPE — common phrases get their own token, dramatically shortening the sequence.
Different Models, Different Tokenizers#
Each AI model family uses its own tokenizer with a different vocabulary. The same text can produce different token counts:
| Text | cl100k_base (GPT-4) | o200k_base (GPT-4o/5) | UTF-8 Bytes |
|---|---|---|---|
| Hello, how are you today? | 7 | 7 | 25 |
| Explain quantum computing in simple terms | 7 | 6 | 41 |
| 你好,请用中文解释一下什么是token | 15 | 9 | 47 |
| こんにちは、トークンとは何ですか? | 12 | 10 | 51 |
| Python fibonacci function (5 lines) | 28 | 28 | 92 |
Key takeaway: GPT-5's tokenizer (o200k_base) is significantly more efficient for Chinese and Japanese — 你好 is 15 tokens on GPT-4 but only 9 tokens on GPT-5 for the same Chinese sentence. That's a 40% cost reduction just from a better tokenizer.
Claude uses its own tokenizer, and Gemini uses SentencePiece. Token counts will vary across providers — which means the same prompt can cost different amounts depending on which model you use.
How Token Counts Affect Your Bill#
AI APIs charge per token, not per byte or per word. And different languages have very different token efficiencies:
Token efficiency by language (o200k_base)#
| Language | Text | Tokens | Bytes | Bytes/Token |
|---|---|---|---|---|
| English | "Hello, how are you today?" | 7 | 25 | 3.6 |
| Chinese | "你好,今天怎么样?" | 5 | 27 | 5.4 |
| Japanese | "こんにちは" | 1 | 15 | 15.0 |
| Korean | "안녕하세요" | 2 | 15 | 7.5 |
| Code | def fibonacci(n): (5 lines) | 28 | 92 | 3.3 |
For GPT-5's tokenizer, Japanese is actually the most token-efficient language — こんにちは packs 15 bytes into a single token.
Real cost comparison#
Suppose you process 1 million characters of text through GPT-5 ($1.25/M input tokens):
| Language | ~Tokens per 1M chars | Cost |
|---|---|---|
| English | ~330K | $0.41 |
| Chinese | ~500K | $0.63 |
| Mixed (EN+CN) | ~400K | $0.50 |
Chinese text costs roughly 50% more than English for the same character count — because each Chinese character takes more tokens on average.
Optimization tip: compare models before committing#
Different models have different tokenizers, different prices, and different capabilities. The cheapest option for your use case might surprise you.
With a unified API gateway, you can test the same prompt across multiple models and compare both quality and cost:
from openai import OpenAI
client = OpenAI(
api_key="your-crazyrouter-key",
base_url="https://crazyrouter.com/v1"
)
# Test the same prompt across models
for model in ["gpt-5", "gpt-5-mini", "deepseek-v3.2", "claude-sonnet-4"]:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Explain tokenization in 2 sentences"}],
max_tokens=100
)
usage = response.usage
print(f"{model}: {usage.prompt_tokens} in / {usage.completion_tokens} out")
With Crazyrouter, one API key gives you access to 627+ models — making it easy to find the most cost-effective model for your specific language and workload.
The Future: Will Byte-Level Models Replace Tokens?#
In late 2024, Meta released research on the Byte Latent Transformer (BLT) — a model architecture that processes raw bytes directly, eliminating the tokenizer entirely.
Why byte-level models are interesting:#
- Truly language-agnostic — no tokenizer bias toward English
- No out-of-vocabulary problem — any byte sequence is valid input
- No tokenizer-model mismatch — the model sees exactly what you typed
Why tokens still dominate in 2026:#
- Byte sequences are 3-4x longer — much more expensive to process
- All production models (GPT-5, Claude, Gemini) still use token-based architectures
- BLT is research-stage — not yet available as a commercial API
The practical reality: tokens will remain the standard for at least the next 3-5 years. Understanding how they work is a necessary skill for any developer using AI APIs.
Quick Reference: Tokens vs Bytes vs Characters vs Words#
| Property | Bytes | Characters | Words | Tokens |
|---|---|---|---|---|
| What is it | Raw storage unit | Human-readable symbol | Space-separated text | Sub-word unit for AI |
| Size | Always 1 byte | 1-4 bytes (UTF-8) | Variable | Variable |
| "Hello" | 5 | 5 | 1 | 1 |
| "你好" | 6 | 2 | 1 | 1 |
| "unbelievable" | 12 | 12 | 1 | 3 |
| Used by | Computers (storage) | Humans (reading) | Search engines | AI models |
| AI billing? | No | No | No | Yes |
Key relationships:#
- 1 English token ≈ 4 characters ≈ 4 bytes ≈ 0.75 words
- 1 Chinese token ≈ 1-3 characters ≈ 3-9 bytes ≈ 1-2 words
- 1,000 tokens ≈ 750 English words ≈ 4,000 characters
Useful tokenizer tools:#
- OpenAI Tokenizer — count tokens for GPT models
- tiktoken (Python) — programmatic token counting
- Anthropic Token Counter — for Claude models
FAQ#
Are tokens the same as bytes?#
No. Bytes are the raw storage units of your computer (1 byte = 8 bits). Tokens are the processed units that AI models read. The text "Hello" is 5 bytes but 1 token. The text "你好" is 6 bytes but also 1 token. The relationship between bytes and tokens depends on the language and the specific tokenizer.
Why don't AI models just process raw bytes?#
Efficiency. "Hello" as bytes is a sequence of length 5; as a token it's length 1. For a 1,000-word article, byte-level processing would create sequences 3-4x longer. Since the computational cost of transformer attention is O(n²), this would make AI models dramatically more expensive and slower.
Does the same text use the same number of tokens across all models?#
No. GPT-5 uses the o200k_base tokenizer, GPT-4 uses cl100k_base, and Claude uses its own. A Chinese sentence might be 15 tokens on GPT-4 but only 9 tokens on GPT-5. This means the same prompt can cost different amounts on different models.
Why does Chinese text cost more than English in AI APIs?#
Two reasons. First, Chinese characters require 3 bytes each in UTF-8 (vs 1 byte for English letters). Second, even with modern tokenizers, Chinese characters are less efficiently compressed into tokens. A typical Chinese sentence uses about 50% more tokens than an English sentence conveying the same meaning.
How can I reduce my token costs?#
Five practical approaches: (1) Write concise prompts — every extra word costs tokens. (2) Use max_tokens to cap output length. (3) Pick the cheapest model that meets your quality bar. (4) Cache repeated queries. (5) Use an API gateway like Crazyrouter to easily compare pricing across 627+ models with a single API key.
Further Reading#
- What Are Tokens in AI? A Beginner's Guide to AI API Pricing
- AI API Pricing Guide 2026: Complete Cost Breakdown
- How to Cut Your AI API Costs by 50%
- Context Window & Token Limits Explained
Understanding the difference between bytes and tokens is the first step to controlling your AI costs. For more developer guides and the latest model pricing data, visit the Crazyrouter Blog.




