Gemini 2.5 Flash Lite vs GPT-4.1 Nano: бенчмарк Vision API 2026 для практического выбора модели
Практический benchmark для сравнения gemini-2.5-flash-lite и gpt-4.1-nano в задачах Vision API: реальная точность распознавания, latency, tail latency, стоимость успешного изображения, usage signals, failure modes и routing recommendations.

Gemini 2.5 Flash Lite vs GPT-4.1 Nano: бенчмарк Vision API 2026 для практического выбора модели#
Выбор vision-модели для production — это не просто вопрос «поддерживает ли модель изображения». Разработчику нужен маршрут, который работает в реальных пользовательских сценариях: загрузка изображений, скриншоты, debugging UI, распознавание логотипов, превью документов, support tickets и agent workflows с визуальным контекстом через OpenAI-compatible API.
В этой статье сравниваются gemini-2.5-flash-lite и gpt-4.1-nano через Crazyrouter OpenAI-compatible Base URL:
https://cn.crazyrouter.com/v1
Формат запроса — chat/completions, где messages[].content[] содержит текст и image_url. Каждая модель тестировалась на двух стабильных публичных изображениях — Python logo и GitHub logo — по 3 запуска на изображение.
Время теста:
2026-06-21T13:36:32Z. Это реальные API-измерения, а не пересказ model card.
Краткая рекомендация#
- Для интерактивной загрузки изображений пользователями предпочтительнее
gemini-2.5-flash-lite: в этом тесте он быстрее. - Для массового тегирования, logo/icon recognition и простой классификации предпочтительнее
gpt-4.1-nano: оценочная стоимость успешного изображения ниже. - Для сложных скриншотов, документов, OCR и анализа графиков добавьте второй этап проверки более сильной моделью.
Scorecard с точки зрения пользователя#
| Критерий выбора | gemini-2.5-flash-lite | gpt-4.1-nano | Почему это важно |
|---|---|---|---|
| HTTP success | 6/6 | 6/6 | Показывает только транспортный успех; не доказывает, что модель увидела изображение. |
| Корректное визуальное распознавание | 6/6 | 6/6 | Главная метрика smoke test для image_url routing. |
| No-image failure claims | 0 | 0 | Помогает найти маршруты, которые приняли запрос, но не передали изображение. |
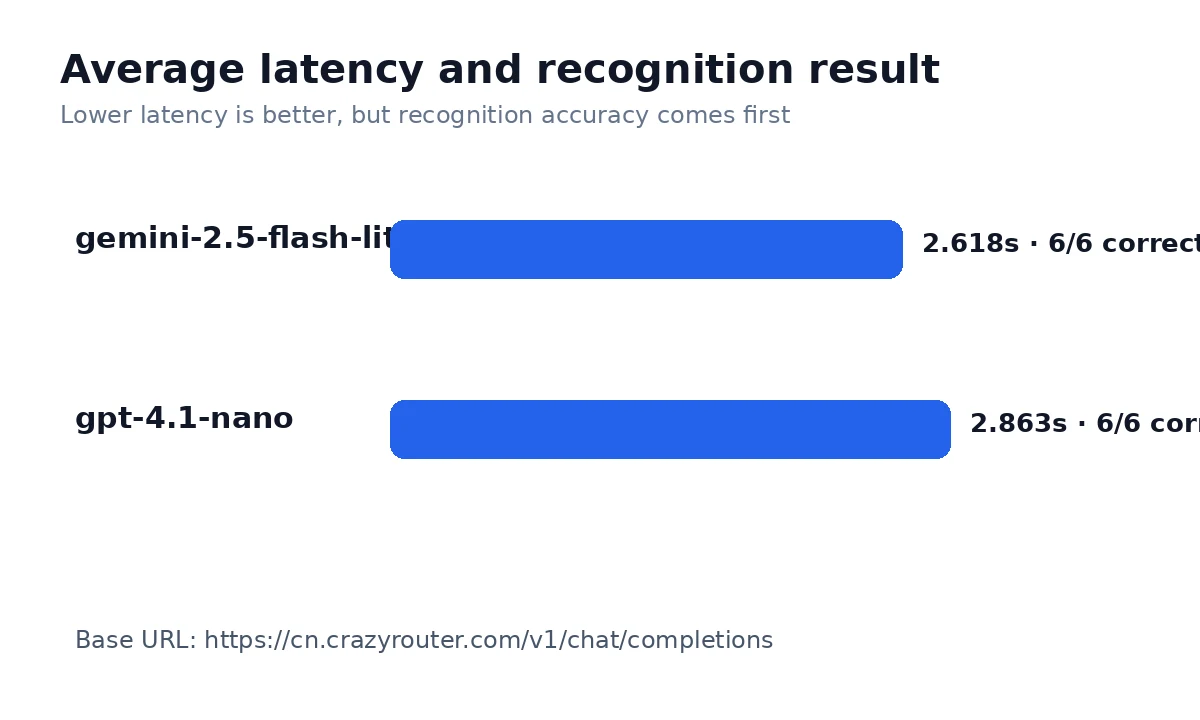
| Average latency | 2.618s | 2.863s | Влияет на ожидание пользователя в обычном запросе. |
| Median latency | 2.627s | 2.562s | Лучше отражает типичный опыт, чем среднее. |
| Slowest request | 4.195s | 4.213s | Tail latency — то, что пользователь ощущает как «зависание». |
| Input price / 1M tokens | $0.055 | $0.065 | Важно для image tagging, OCR pre-filtering и batch classification. |
| Output price / 1M tokens | $0.22 | $0.26 | Важно, если нужны длинные описания изображений. |
| Estimated cost / 10k test-style calls | $0.5466 | $0.1666 | Практичнее, чем raw token price: учитывает наблюдаемый usage. |
| Usage / image signal | поля image tokens равны нулю или отсутствуют; нужен визуальный smoke test, а не только HTTP status | поля image tokens равны нулю или отсутствуют; нужен визуальный smoke test, а не только HTTP status | Usage metadata может показать сломанный vision path даже при HTTP 200. |

Для каких решений полезен этот benchmark#
Это намеренно vision API smoke test. Он помогает понять:
- работает ли
image_urlчерез OpenAI-compatible API; - действительно ли модель видит картинку, а не только текстовый prompt;
- какая модель быстрее для маленького пользовательского image request;
- какой маршрут дешевле для массовой простой классификации;
- выглядит ли usage metadata консистентно с обработкой изображения.
Это не полный benchmark для OCR, chart reasoning, handwriting, medical images, dense document extraction или multi-image reasoning. Для таких задач используйте этот тест как первый routing check и добавляйте отдельные domain-specific evaluation.
Raw benchmark data#
| Метрика | gemini-2.5-flash-lite | gpt-4.1-nano |
|---|---|---|
| HTTP success | 6/6 | 6/6 |
| Correct recognition | 6/6 | 6/6 |
| No-image replies | 0 | 0 |
| Average latency | 2.618s | 2.863s |
| Median latency | 2.627s | 2.562s |
| Fastest request | 1.302s | 2.256s |
| Slowest request | 4.195s | 4.213s |
| Avg prompt tokens observed | 970.5 | 227.0 |
| Avg completion tokens observed | 5.8 | 7.3 |
Примеры ответов#
| Задача | Модель | Пример ответа | Задержка | Prompt tokens |
|---|---|---|---|---|
logo_python | gemini-2.5-flash-lite | The Python programming language logo. | 2.616s | 1109 |
logo_python | gpt-4.1-nano | Python programming language logo. | 4.213s | 227 |
logo_github | gemini-2.5-flash-lite | The GitHub logo. | 2.638s | 1109 |
logo_github | gpt-4.1-nano | GitHub Octocat logo silhouette. | 2.512s | 227 |
Production routing guidance#
1. Real-time image uploads#
Для chat apps, customer support tools и пользовательской загрузки изображений важнее всего latency и reliability. Дешёвая модель не является дешёвой, если пользователи повторяют запросы, уходят из продукта или постоянно запускают fallback.
2. Bulk logo, icon и screenshot tagging#
Для массовой классификации важна стоимость успешного изображения. Используйте более дешёвый маршрут, если задача простая и формат ответа можно валидировать. Fallback нужен для empty answers, no-image claims и low-confidence классификаций.
3. OCR и document workflows#
Этот benchmark не доказывает OCR quality. Для invoices, tables, forms, receipts и dense screenshots нужен отдельный тест на реальных документах. Модель, которая распознаёт логотип, не обязательно хорошо извлекает layout.
4. Agent workflows with visual context#
Agents требуют предсказуемых входных данных. Если маршрут иногда теряет image content при HTTP 200, агент может уверенно принимать неверные решения. Для agent use cases проверяйте answer correctness, usage signals и fail closed при подозрительном image path.
5. Gateway media behavior#
image_url support может означать разные вещи: API принимает URL от клиента, gateway скачивает и конвертирует media, либо upstream provider получает исходный URL. Это влияет на bandwidth, privacy, SSRF controls, latency и billing. Media behavior должен быть частью model routing.
Почему HTTP 200 недостаточно#
Валидный HTTP response доказывает только то, что API что-то вернул. Он не доказывает, что изображение дошло до модели. В monitoring для Vision API нужно отправлять маленькое deterministic test image, задавать вопрос с известным ответом и проверять как текст ответа, так и usage metadata.
Особенно это важно для маршрутов, где usage показывает отсутствие image tokens или модель отвечает, что изображение не было предоставлено. Это может быть не failure самой модели, а проблема adapter, media-fetch, payload conversion или routing.
API example#
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://cn.crazyrouter.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-lite",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Identify the main logo or object in this image."},
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/github/explore/main/topics/python/python.png",
"detail": "low"
}
}
]
}],
max_tokens=40,
temperature=0,
)
print(response.choices[0].message.content)
В кодовых API endpoints UTM-параметры не добавляются. Для ссылок, которые видит человек, можно использовать UTM, например Crazyrouter Pricing.
Final takeaway#
Лучший Vision API route зависит от workflow. Для real-time interactions важны корректное распознавание и низкая latency. Для bulk classification — cost per successful image. Для agents и document workflows — reliability, usage signals и fallback design.
Иными словами: не выбирайте vision-модель только по названию. Выбирайте по задаче, failure mode, media path, latency и стоимости полезного результата.





