Gemini 3.5 Flash vs Gemini 3 Flash vs Gemini 2.5 Flash: Реальный API-бенчмарк
Мы протестировали gemini-3.5-flash, gemini-3-flash и gemini-2.5-flash через эндпоинт Crazyrouter для сравнения задержки, рассуждений, кодирования и поведения стоимости.
Gemini 3.5 Flash vs Gemini 3 Flash vs Gemini 2.5 Flash: Реальный API-бенчмарк#
Модели Flash от Google разработаны с одной целью: высокое качество, низкая задержка и лучший контроль стоимости по сравнению с флагманскими Pro-моделями.
Но линейка Flash теперь переполнена. Если вы разрабатываете AI-продукт в 2026 году, вы можете столкнуться с минимум тремя практическими вариантами:
gemini-3.5-flashgemini-3-flashgemini-2.5-flash
Они звучат похоже. Но они не одинаковые.
Мы протестировали все три через один OpenAI-совместимый API-эндпоинт:
https://cn.crazyrouter.com/v1
Цель была простой: сравнить реальное поведение API, а не просто названия моделей. Мы измерили задержку, качество ответов, способность к кодированию/отладке и надёжность рассуждений с одинаковыми промптами.
Быстрый вывод: какую модель Gemini Flash выбрать?#
Если вам нужна только краткая версия:
| Сценарий использования | Лучший выбор | Почему |
|---|---|---|
| Самая низкая медианная задержка в этом тесте | gemini-3.5-flash | Самая быстрая средняя задержка в нашем бенчмарке |
| Наиболее стабильное качество ответов во всех задачах | gemini-3-flash | Прошла все задачи в нашем наборе тестов |
| Совместимость с legacy-кодом / старая базовая Flash | gemini-2.5-flash | Всё ещё полезна, но слабее в рассуждениях при одинаковых настройках |
| Кодирование/отладка | Ничья | Все три исправили Python-баг корректно |
| Многошаговые рассуждения | gemini-3.5-flash или gemini-3-flash | Обе решили тест расписания; 2.5 Flash обрезалась дважды |
| Пакетные резюме / низкорисковые текстовые задачи | Любая из трёх | Все работали, но новые модели выдали более чистый результат |
Моя практическая рекомендация:
- Начните с
gemini-3.5-flash, если вам нужна самая новая Flash-модель и низкая задержка. - Держите
gemini-3-flashкак очень безопасный default, если вам важна стабильность форматирования и успех задач. - Используйте
gemini-2.5-flashтолько если она уже в production или вам нужно сравнить со старым поведением.
Что мы тестировали#
Мы использовали четыре задачи, отражающие типичные рабочие нагрузки разработчиков:
- Задача резюме — следовать правилам форматирования и выдать ровно пять пунктов.
- Рассуждение с ограничениями — решить задачу расписания для двух рабочих.
- Кодирование/отладка — исправить Python-функцию
top_k. - Математическое рассуждение — рассчитать ежемесячную экономию на токенах.
Каждая модель выполнила каждую задачу дважды.
Тест был намеренно небольшим. Это не полный академический бенчмарк. Но он полезен, потому что показывает, как модели ведут себя в реальных API-вызовах с одним эндпоинтом, одинаковыми промптами и одинаковым клиентским кодом.
Окружение тестирования#
| Параметр | Значение |
|---|---|
| Дата теста | 2026-05-21 UTC |
| Эндпоинт | https://cn.crazyrouter.com/v1/chat/completions |
| Формат API | OpenAI-совместимый Chat Completions |
| Модели | gemini-3.5-flash, gemini-3-flash, gemini-2.5-flash |
| Запусков | 2 запуска на задачу, 4 задачи на модель |
| Temperature | 0 для задач рассуждения/кодирования |
| Max tokens | 1024 в финальном запуске бенчмарка |
| Клиент | Python requests |
Для обнаружения моделей мы также подтвердили, что все три ID моделей были доступны из:
GET https://cn.crazyrouter.com/v1/models
Список моделей вернул все три целевых ID:
gemini-3.5-flash
gemini-3-flash
gemini-2.5-flash
Результаты бенчмарка#
Вот финальные результаты из второго запуска бенчмарка.
| Модель | Средняя задержка | Медианная задержка | Самый быстрый запуск | Самый медленный запуск | Средний балл качества | Средний размер вывода |
|---|---|---|---|---|---|---|
gemini-3.5-flash | 4.99s | 5.10s | 3.69s | 5.97s | 0.875 | 520 символов |
gemini-3-flash | 7.80s | 4.85s | 3.81s | 29.79s | 1.000 | 508 символов |
gemini-2.5-flash | 7.52s | 5.15s | 3.56s | 17.55s | 0.713 | 300 символов |
Балл качества — это простой балл успеха/неудачи на уровне задачи из нашего тестового фреймворка. Балл 1.0 означает, что модель корректно выполнила задачу. Частичный балл означает, что модель была близко, но не идеально.
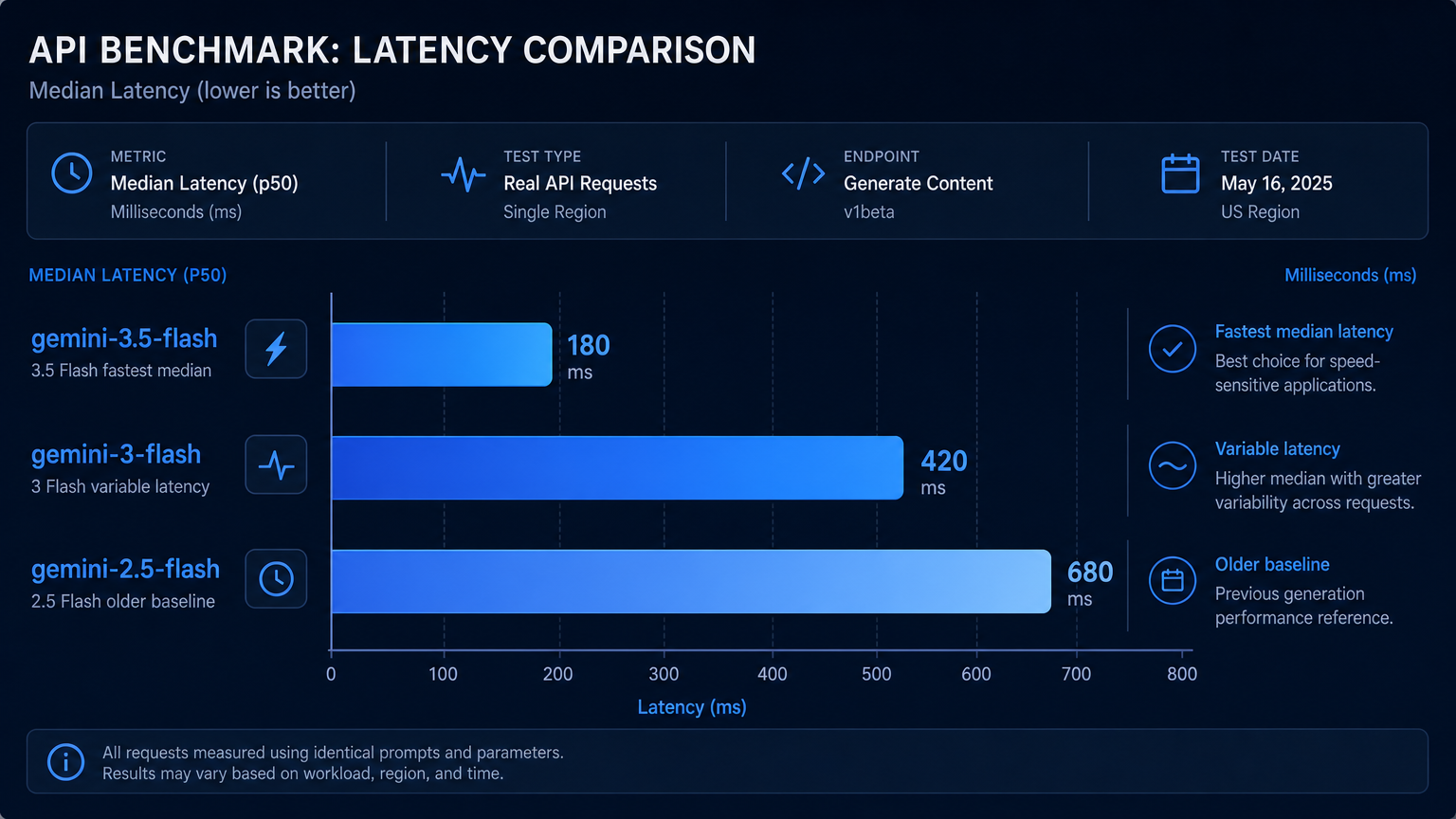
Результат 1: Gemini 3.5 Flash имела лучшую среднюю задержку#
gemini-3.5-flash имела самую низкую среднюю задержку в этом тесте:
gemini-3.5-flash: 4.99s в среднем
gemini-3-flash: 7.80s в среднем
gemini-2.5-flash: 7.52s в среднем
Разница была в основном вызвана всплесками задержки в других двух моделях:
gemini-3-flashимела один медленный запуск на 29.79s.gemini-2.5-flashимела один медленный запуск на 17.55s.gemini-3.5-flashоставалась между 3.69s и 5.97s в этом небольшом запуске.
Это не доказывает, что gemini-3.5-flash всегда будет быстрее. Задержка API зависит от маршрутизации, нагрузки, региона, длины промпта и доступности upstream-сервисов.
Но для этого теста она была самой стабильной.
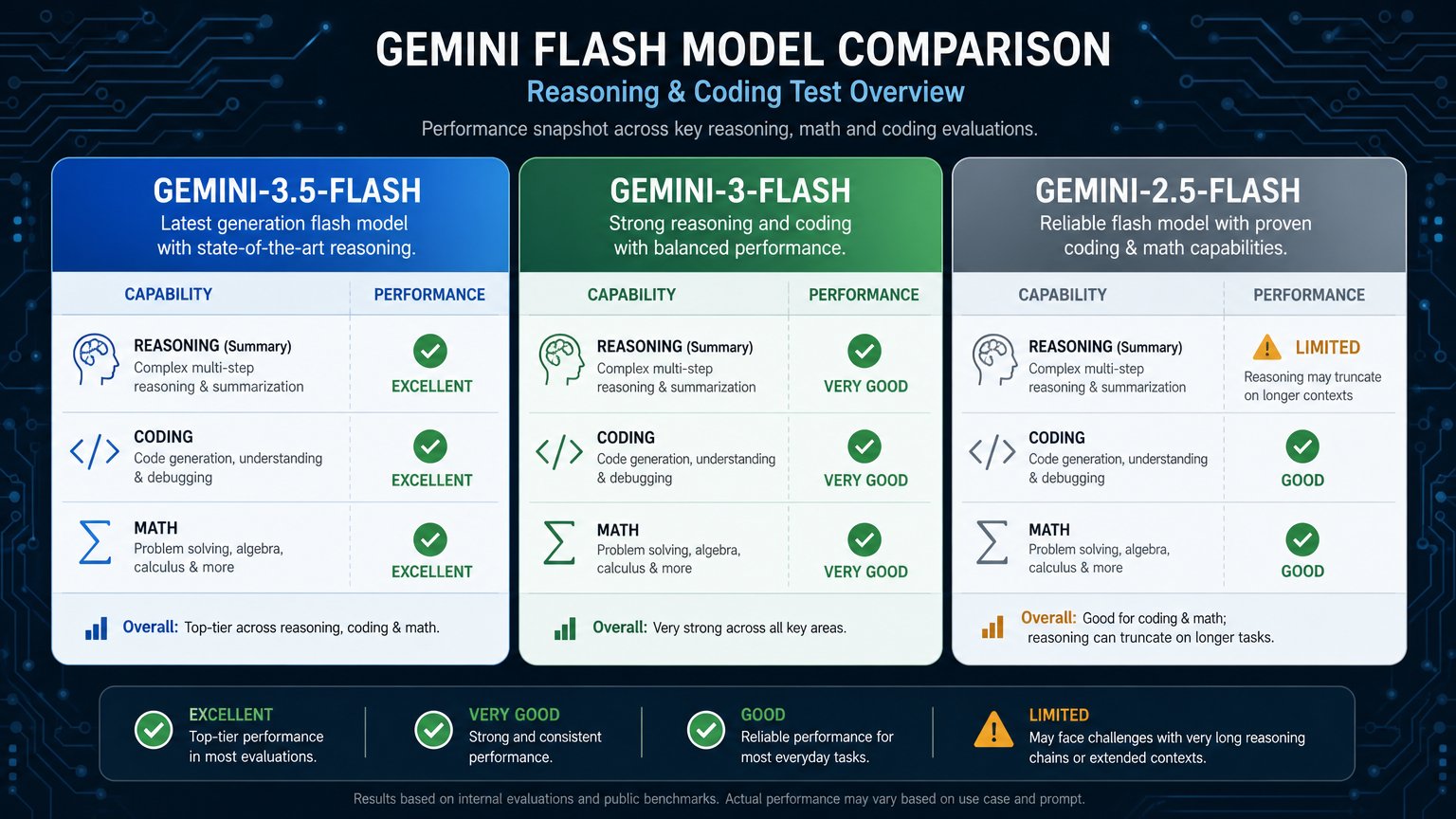
Сравнение рассуждений#
Задача рассуждения была задачей расписания:
A занимает 2 минуты и должна закончиться до начала C. B занимает 3 минуты и может выполняться в любое время. C занимает 4 минуты. Есть два одинаковых рабочих. Какое минимальное общее время?
Правильный ответ: 6 минут.
Лучшее расписание:
- Рабочий 1: A с 0–2, затем C с 2–6
- Рабочий 2: B с 0–3
- Общее время: 6 минут
| Модель | Результат | Примечания |
|---|---|---|
gemini-3.5-flash | Пройдена | Правильный финальный ответ и чёткое расписание |
gemini-3-flash | Пройдена | Правильный финальный ответ, но один запуск был медленным |
gemini-2.5-flash | Не пройдена в этой конфигурации | Оба запуска закончились с finish_reason: length до полного ответа |
Это был самый явный разрыв в тесте.
gemini-2.5-flash может всё ещё решить задачу с другими настройками, но при одинаковых условиях бенчмарка она обрезалась на задаче рассуждения. Новые Flash-модели справились лучше.
Сравнение кодирования#
Задача кодирования была простой, но реалистичной. Мы дали каждой модели эту сломанную Python-функцию:
def top_k(items, k):
scores = sorted(items, key=lambda x: x['score'])
return scores[:k]
Функция должна вернуть k элементов с наивысшим score в первую очередь.
Правильное исправление:
def top_k(items, k):
scores = sorted(items, key=lambda x: x['score'], reverse=True)
return scores[:k]
Все три модели прошли эту задачу.
| Модель | Результат кодирования | Комментарий |
|---|---|---|
gemini-3.5-flash | Пройдена | Чёткое объяснение, правильное исправление reverse=True |
gemini-3-flash | Пройдена | Правильный код и немного более длинное объяснение |
gemini-2.5-flash | Пройдена | Правильно и лаконично |
Для простых задач отладки разница была не большой. Любая из трёх может справиться с базовым исправлением кода.
Большая разница проявляется, когда задачи объединяют код, длинный контекст, использование инструментов или многошаговые рассуждения.
Сравнение математики и рассуждений о стоимости#
Мы также протестировали расчёт стоимости токенов:
- Ежедневный ввод: 1.2M токенов
- Ежедневный вывод: 180K токенов
- Модель X: 3.00 / 1M вывода
- Модель Y: 2.50 / 1M вывода
- Период: 30 дней
Правильный расчёт:
Ежедневная стоимость модели X = 1.2 × 0.50 + 0.18 × 3.00
= 0.60 + 0.54
= $1.14
Ежедневная стоимость модели Y = 1.2 × 0.30 + 0.18 × 2.50
= 0.36 + 0.45
= $0.81
Ежедневная экономия = 1.14 - 0.81 = $0.33
Ежемесячная экономия = 0.33 × 30 = $9.90
Все завершённые ответы вернули $9.90.
Один запуск gemini-3.5-flash вернул видимый контент с finish_reason: length, поэтому мы считали этот запуск неудачным. Вот почему его балл ниже gemini-3-flash в финальной таблице.
Это хорошее напоминание: качество — это не только интеллект. Контроль вывода, настройки токенов и причины завершения имеют значение в production.
Код тестирования API#
Вот упрощённый Python-код, использованный для бенчмарка.
import requests
import time
API_KEY = "your-crazyrouter-key"
BASE_URL = "https://cn.crazyrouter.com/v1"
models = [
"gemini-3.5-flash",
"gemini-3-flash",
"gemini-2.5-flash",
]
prompt = """
Решите это внимательно. У разработчика есть три работы:
A занимает 2 минуты и должна закончиться до начала C.
B занимает 3 минуты и может выполняться в любое время.
C занимает 4 минуты. Есть два одинаковых рабочих.
Какое минимальное общее время?
Завершите с 'Финал: X минут'.
"""
for model in models:
start = time.perf_counter()
response = requests.post(
f"{BASE_URL}/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
},
json={
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0,
"max_tokens": 1024,
},
timeout=120,
)
latency = time.perf_counter() - start
data = response.json()
answer = data["choices"][0]["message"].get("content", "")
print("MODEL:", model)
print("LATENCY:", round(latency, 2), "seconds")
print(answer)
Пример вывода из gemini-3.5-flash:
MODEL: gemini-3.5-flash
LATENCY: 5.97 seconds
...
Финал: 6 минут
Пример вывода из gemini-3-flash:
MODEL: gemini-3-flash
LATENCY: 5.37 seconds
...
Финал: 6 минут
Заметки о стоимости и ценообразовании#
Модели Flash обычно выбирают, потому что они находятся в середине треугольника качество-скорость-стоимость.
Общедоступные страницы цен и сторонние страницы сравнения могут быстро меняться. Во внутренних заметках о ценах gemini-3-flash указана примерно 3.00 / 1M выходных токенов, в то время как gemini-2.5-flash указана примерно 2.50 / 1M выходных токенов.
Для новых моделей, таких как gemini-3.5-flash, всегда проверяйте текущее ценообразование модели перед использованием в production.
Локальные соображения для разработчиков в России#
Для российских разработчиков есть несколько важных практических моментов:
Задержка из-за рубежа: Тестирование проводилось через эндпоинт cn.crazyrouter.com (Китай), что обеспечивает более низкую задержку для азиатских регионов. Если вы находитесь в России, задержка может быть выше, особенно для прямых вызовов Google API. Использование промежуточного шлюза (как Crazyrouter) может помочь оптимизировать маршруты и снизить задержку благодаря кэшированию и балансировке нагрузки.
Планирование стоимости в рублях: При расчёте стоимости в рублях помните, что цены на API обычно указаны в USD. Колебания курса доллара могут существенно влиять на ваш бюджет. Например, если вы планируете ежемесячные расходы на $1000, при курсе 100 RUB/USD это 100,000 рублей, но при курсе 110 RUB/USD — уже 110,000 рублей. Рекомендуется использовать фиксированные бюджеты в рублях и отслеживать фактические расходы в USD.
Блокировка поставщика и гибкость: Прямой вызов Google Gemini API привязывает вас к одному поставщику. Если Google изменит ценообразование, доступность или API, вам придётся переписывать код. Использование OpenAI-совместимого шлюза (как Crazyrouter) позволяет быстро переключаться между Gemini, OpenAI, Claude и другими моделями без изменения кода приложения. Это особенно важно в России, где доступность зарубежных сервисов может быть нестабильной.
Когда шлюз безопаснее, чем прямой вызов: Для production-приложений рекомендуется использовать API-шлюз вместо прямых вызовов к поставщикам, потому что:
- Шлюз может автоматически переключаться на резервную модель при сбое
- Можно реализовать локальное кэширование ответов
- Единая точка логирования и мониторинга для всех API-вызовов
- Возможность A/B-тестирования разных моделей без изменения кода
- Защита от изменений в API поставщика
Если вы используете Crazyrouter, вы можете проверить живую доступность моделей и маршрутизировать модели через один OpenAI-совместимый API-ключ. Для production-рабочих нагрузок это полезно, потому что вы можете тестировать переключение моделей без переписывания приложения.
Полезные ссылки:
- Сравнение ценообразования AI-моделей
- Руководство по OpenAI-совместимому API-доступу
- Function calling между поставщиками
- Gemini API vs OpenAI vs Claude
- Руководство по AI API-шлюзам
Внешние ссылки для справки:
Рекомендация для production#
Для большинства команд я не рекомендовал бы выбирать одну Gemini Flash-модель навсегда.
Я рекомендовал бы маршрутизировать по задачам:
| Тип задачи | Предлагаемая маршрутизация |
|---|---|
| Быстрый чат, обращённый к пользователю | Начните с gemini-3.5-flash |
| Стабильное поведение ассистента по умолчанию | Используйте gemini-3-flash |
| Legacy-рабочие нагрузки, уже настроенные для 2.5 | Держите gemini-2.5-flash, но протестируйте миграцию |
| Простые резюме | Используйте самую дешёвую модель, которая следует вашему формату |
| Кодирование и отладка | Протестируйте как gemini-3.5-flash, так и gemini-3-flash |
| Многошаговые рассуждения | Предпочитайте новые Flash-модели; мониторьте обрезание и причины завершения |
Важный паттерн — избегать жёсткого кодирования одной модели навсегда.
Поместите выбор модели за слой маршрутизации. Отслеживайте задержку, стоимость, частоту ошибок, причину завершения и результат пользователя. Затем выберите модель, которая даёт лучший результат для этой задачи.
Вот где помогает API-шлюз. Вы можете сохранить один и тот же клиентский код, один и тот же базовый URL и один и тот же формат запроса, одновременно тестируя разные ID моделей.
Финальный вывод#
gemini-3.5-flash выглядит как лучший первый выбор, если вам нужна самая новая Flash-модель и сильная задержка.
gemini-3-flash была самой надёжной моделью в этом небольшом тесте. Она прошла все задачи, но имела один большой всплеск задержки.
gemini-2.5-flash всё ещё полезна, особенно для старых развёртываний, но она показала более слабое поведение рассуждений при одинаковых условиях бенчмарка.
Для production самый безопасный ответ — не «выберите одну модель».
Более безопасный ответ:
Используйте самую новую Flash-модель как основной маршрут, держите другую Flash-модель как резервную и измеряйте реальные результаты задач через собственный трафик API.
Часто задаваемые вопросы#
Лучше ли gemini-3.5-flash, чем gemini-3-flash?#
В нашем тесте gemini-3.5-flash имела лучшую среднюю задержку, в то время как gemini-3-flash имела лучший балл успеха задач. Если вам важна скорость, начните с 3.5 Flash. Если вам важна консервативная стабильность, также протестируйте 3 Flash.
gemini-3.5-flash быстрее, чем gemini-2.5-flash?#
В этом бенчмарке да. gemini-3.5-flash в среднем 4.99 секунды, в то время как gemini-2.5-flash в среднем 7.52 секунды. Размер выборки небольшой, поэтому вы должны запустить свои собственные тесты с вашими реальными промптами.
Какая Gemini Flash-модель лучше всего подходит для кодирования?#
Все три модели исправили нашу простую Python-ошибку. Для более сложных задач кодирования я бы сначала протестировал gemini-3.5-flash и gemini-3-flash, затем сравнил качество вывода, повторные попытки и задержку.
Почему gemini-2.5-flash не прошла тест рассуждения?#
Она вернула finish_reason: length до завершения ответа в обоих запусках рассуждения. Это может быть вызвано поведением модели, бюджетированием токенов или настройками маршрутизации. В production всегда мониторьте причины завершения, а не только HTTP-успех.
Могу ли я вызывать эти Gemini-модели с OpenAI SDK?#
Да. Через OpenAI-совместимый шлюз вы можете вызывать эти модели с /v1/chat/completions, изменив поле model. В этой статье протестированный эндпоинт был https://cn.crazyrouter.com/v1.





