用 text-embedding-3-large 搭建 RAG 知识库:从切块、向量化到检索排序
本文用实战方式讲解如何用 text-embedding-3-large 搭建 RAG 知识库,包括文档切块、调用 embeddings API、向量存储、相似度检索、rerank 和生产环境优化建议。

用 text-embedding-3-large 搭建 RAG 知识库:从切块、向量化到检索排序#
很多 RAG demo 看起来很简单:上传 PDF,提问,AI 回答。
但真正上线时,你会发现问题马上来了:
- 文档太长,直接塞不进上下文
- 关键词搜索找不到语义相近内容
- 用户问法很口语,文档写法很正式
- 搜出来的内容不准,模型就开始编
- 数据一多,检索速度和成本都上来了
text-embedding-3-large 解决的是其中最关键的一环:把问题和文档变成可比较的语义向量。
这篇文章不讲空泛概念,直接从工程角度拆一套可落地的 RAG 流程。
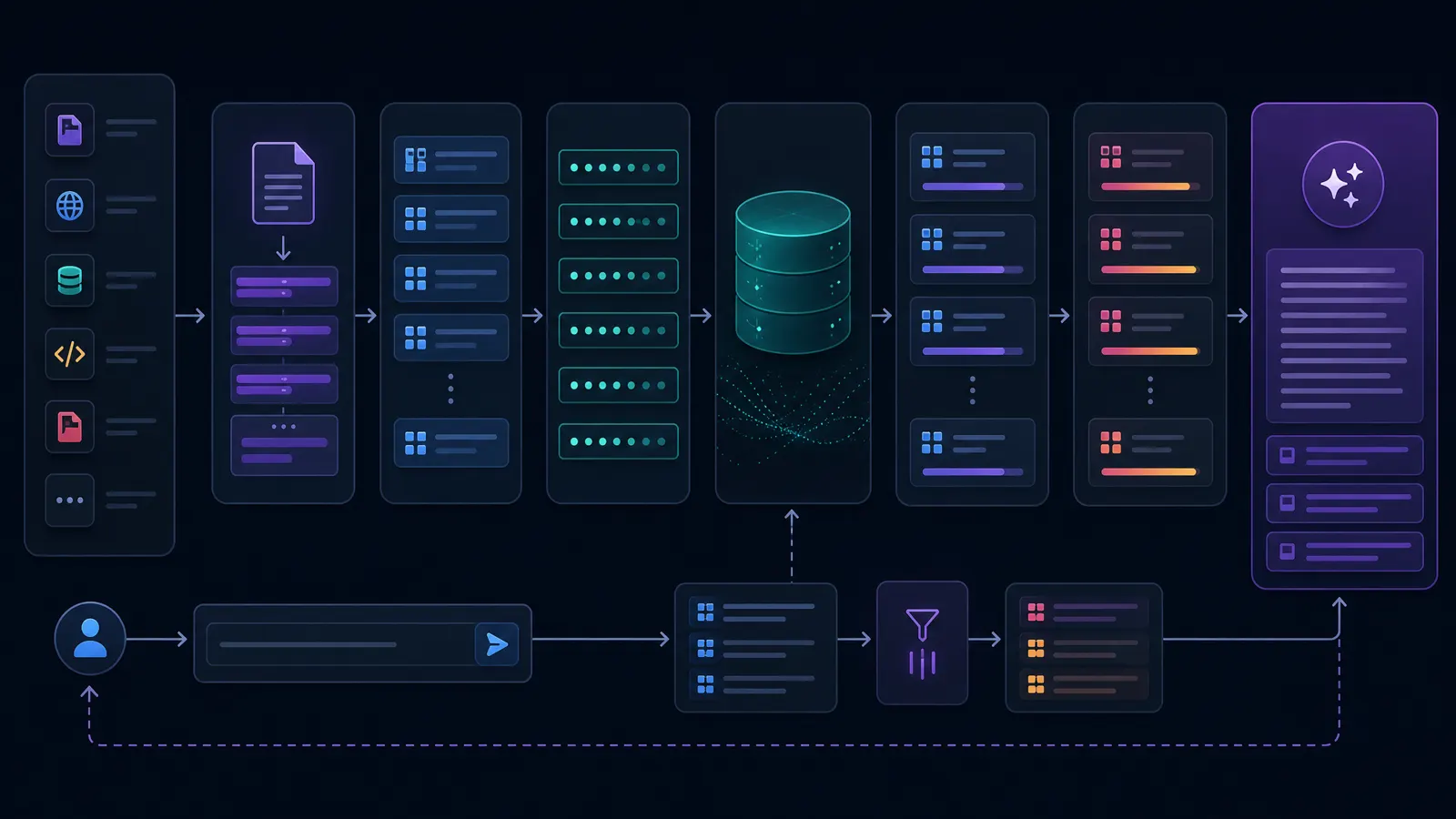
RAG 系统的基本架构#
一个最常见的 RAG 知识库通常分成两条链路。
第一条是离线索引链路:
- 收集文档
- 清洗文本
- 切块 chunking
- 调用 embedding 模型生成向量
- 存入向量数据库
第二条是在线问答链路:
- 用户提问
- 把问题转成 embedding
- 在向量库里检索相似文档块
- 可选:rerank 重新排序
- 拼接上下文
- 调用聊天模型生成答案
这个流程里,text-embedding-3-large 主要出现在第 4 步和在线链路第 2 步。
它不负责最终回答,但它决定了模型能不能拿到正确资料。
第一步:准备文档和切块#
RAG 质量很大程度取决于 chunk。
切得太大:召回结果噪声多,模型读到很多无关内容。
切得太小:上下文不完整,模型拿不到足够信息。
一个常用起点:
| 文档类型 | 建议 chunk 大小 | overlap |
|---|---|---|
| FAQ / 帮助中心 | 200-500 tokens | 30-80 tokens |
| 技术文档 | 400-800 tokens | 80-120 tokens |
| 长篇报告 | 600-1000 tokens | 100-150 tokens |
| 代码文档 | 按函数/类/标题切 | 视情况 |
示例切块代码:
def chunk_text(text, chunk_size=600, overlap=100):
words = text.split()
chunks = []
start = 0
while start < len(words):
end = start + chunk_size
chunk = " ".join(words[start:end])
chunks.append(chunk)
start = end - overlap
return chunks
生产环境不要只按空格切。更好的方式是按标题、段落、列表、代码块边界切。
第二步:用 text-embedding-3-large 生成向量#
下面代码使用 OpenAI 兼容接口。你可以用同一个 SDK 调用 /v1/embeddings。
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://crazyrouter.com/v1"
)
def get_embedding(text: str):
text = text.replace("\n", " ")
response = client.embeddings.create(
model="text-embedding-3-large",
input=text,
encoding_format="float"
)
return response.data[0].embedding
如果你要控制向量维度,可以加 dimensions 参数:
response = client.embeddings.create(
model="text-embedding-3-large",
input=text,
dimensions=1536,
encoding_format="float"
)
维度越低,存储和检索成本通常越低;但召回质量可能下降。建议用真实问题集做 A/B 测试。
第三步:存入向量数据库#
小项目可以用本地文件或 SQLite 做 demo,但生产环境建议使用专门的向量数据库。
常见选择:
| 工具 | 适合场景 |
|---|---|
| pgvector | 已经使用 PostgreSQL,希望少引入组件 |
| Qdrant | 独立向量数据库,部署简单,过滤能力强 |
| Milvus | 大规模向量检索 |
| Pinecone | 托管服务,省运维 |
| Weaviate | 带 schema 和 hybrid search |
无论用哪个库,建议每个 chunk 至少保存这些字段:
{
"id": "doc_001_chunk_003",
"text": "chunk content here",
"embedding": [0.0123, -0.0456],
"metadata": {
"source": "billing-guide.md",
"title": "Billing Guide",
"section": "Token pricing",
"updated_at": "2026-05-18"
}
}
Metadata 很重要。它能让你按产品、语言、时间、权限过滤检索结果。
第四步:查询时做语义检索#
当用户提问时,先把问题转成向量,然后在数据库里找相似 chunk。
def retrieve(query: str, vector_db, top_k=5):
query_vector = get_embedding(query)
results = vector_db.search(
vector=query_vector,
top_k=top_k,
filter={"language": "zh"}
)
return results
如果不用向量数据库,也可以用 numpy 演示 cosine similarity:
import numpy as np
def cosine_similarity(a, b):
a = np.array(a)
b = np.array(b)
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
但数据量到几万条以后,就应该换向量数据库了。
第五步:加入 rerank,减少答非所问#
Embedding 检索是“粗召回”。它很快,但不总是最精确。
Rerank 是“精排序”。它会重新判断 query 和候选文档之间的相关性。
推荐流程:
- embedding 先取 top 20
- rerank 排序
- 最终取 top 5 给聊天模型
这样比直接取 embedding top 5 更稳,尤其适合:
- 技术文档问答
- 客服知识库
- 法务/财务资料
- 多语言内容库
- 文档很多、标题相似的场景
Crazyrouter 支持 /v1/rerank 这类重排序端点,你可以把它放在 RAG 检索链路里,作为召回后的精排步骤。
第六步:把检索结果交给聊天模型#
检索到 chunk 后,拼成 prompt:
def build_prompt(question, chunks):
context = "\n\n".join(
f"Source: {c['metadata']['source']}\n{c['text']}"
for c in chunks
)
return f"""
你是一个严谨的知识库助手。
只根据下面的资料回答问题。
如果资料里没有答案,就说“资料中没有找到”。
资料:
{context}
问题:{question}
"""
然后调用聊天模型生成答案。
answer = client.chat.completions.create(
model="gpt-5-mini",
messages=[{"role": "user", "content": build_prompt(question, chunks)}]
)
print(answer.choices[0].message.content)
这里 embedding 模型和聊天模型各司其职:
text-embedding-3-large:找相关资料gpt-5-mini/ Claude / Gemini:根据资料组织答案
text-embedding-3-large 在多语言 RAG 里的优势#
很多团队的文档不是单一语言。
可能有:
- 英文 API 文档
- 中文帮助中心
- 日文用户手册
- 韩文社区文章
- 越南语教程
多语言 RAG 的难点是:用户用一种语言提问,答案可能藏在另一种语言的文档里。
text-embedding-3-large 官方定位是适合英文和非英文任务的高能力 embedding 模型。做跨语言检索时,建议优先把它作为候选模型测试。
但不要只看官方分数。你应该建立自己的评测集:
| query | 正确文档 | 语言 | 是否召回 |
|---|---|---|---|
| 余额为什么扣费快? | billing-token-cost.md | zh | yes/no |
| how to set API base URL | quickstart.md | en | yes/no |
| Claude Code 怎么配置? | integrations/claude-code.md | zh | yes/no |
最终看 top 3 / top 5 召回率。
生产环境优化建议#
1. 增量索引,不要每次全量重建#
文档更新后,只重新向量化变化的 chunk。
给每个 chunk 存 hash:
import hashlib
def content_hash(text):
return hashlib.sha256(text.encode("utf-8")).hexdigest()
hash 不变就跳过。
2. 使用批量 embedding#
不要一条一条调用。Embeddings API 通常支持批量输入。
response = client.embeddings.create(
model="text-embedding-3-large",
input=[chunk1, chunk2, chunk3],
encoding_format="float"
)
这样更快,也更容易控制请求数。
3. 做 hybrid search#
纯向量搜索有时会漏掉精确关键词,例如错误码、订单号、函数名。
更稳的方式是:
- BM25 / 关键词搜索
- 向量搜索
- 合并结果
- rerank
4. 给答案加引用来源#
不要只输出答案。最好附上引用文档标题和链接。
这会显著提升用户信任,也方便排查错误召回。
5. 分权限检索#
企业知识库一定要做权限过滤。
不要先召回再过滤。应该在向量数据库查询阶段就带上权限条件。
常见问题排查#
| 问题 | 常见原因 | 解决方式 |
|---|---|---|
| 找不到正确文档 | chunk 太大/太小,query 太短 | 调整切块,query rewrite |
| 答案引用错文档 | top_k 太小,缺 rerank | top 20 + rerank |
| 延迟太高 | 每次实时向量化文档 | 文档离线索引,查询实时 embedding |
| 成本上升快 | 重复索引、维度过高 | hash 去重,降维测试 |
| 多语言召回差 | 模型不适合跨语言 | 测试 large,建立多语言评测集 |
什么时候不该用 text-embedding-3-large?#
不是所有项目都需要最高能力 embedding。
这些情况可以先不用:
- 数据量很小,关键词搜索够用
- 只是后台管理工具,对召回质量要求不高
- 预算极紧,且内容主要是单语言 FAQ
- 业务还在 MVP 阶段,没有真实 query 数据
更务实的做法是:先用一组真实问题测试 small 和 large 的召回差异,再决定是否升级。
结论:RAG 的成败,一半在检索#
聊天模型再强,如果上下文拿错了,也只能认真地答错。
text-embedding-3-large 的价值在于让系统能按语义找到资料,而不是只靠关键词碰运气。
如果你要做生产级 RAG,我建议按这个顺序推进:
- 整理真实文档
- 做合理切块
- 用 text-embedding-3-large 建立向量索引
- 用真实用户问题评测 top 5 召回率
- 加 rerank
- 再优化 prompt 和聊天模型
你可以用 OpenAI 兼容 SDK 接入 Crazyrouter embeddings API,同一个 base_url 下同时调用 embedding、rerank 和聊天模型,方便把 RAG 链路串起来。
FAQ#
RAG 知识库一定要用 text-embedding-3-large 吗?#
不一定。它适合高质量、多语言、生产级检索。小项目可以先用成本更低的 embedding 模型做基线。
文档切块多大最合适?#
没有固定答案。技术文档可以从 400-800 tokens 开始,FAQ 可以更短。最终看真实 query 的召回效果。
text-embedding-3-large 可以和 pgvector 一起用吗?#
可以。你可以把生成的向量存到 PostgreSQL 的 pgvector 字段里,再用向量相似度查询。
为什么 embedding 找到了资料,模型还是回答错?#
可能是召回内容有噪声、prompt 没有限制、模型忽略引用,或者问题需要多个文档联合推理。可以加 rerank 和引用约束。
RAG 要不要加 rerank?#
生产环境建议加。Embedding 负责快速召回,rerank 负责精排,组合效果通常更稳。