Claude Fable 5 vs Claude Opus 4.8:通过 Crazyrouter 中国区 API 的真实实测
我们用 Crazyrouter 中国区 API 对 claude-fable-5 和 claude-opus-4-8 做了 8 项真实测试,覆盖代码修复、严格 JSON、推理、长上下文、API Review、中文总结、Agent 计划和路由策略。

Claude Fable 5 vs Claude Opus 4.8:通过 Crazyrouter 中国区 API 的真实实测#
这不是厂商宣传稿,也不是只看排行榜的二手转述。我们直接用 https://cn.crazyrouter.com/v1 跑了 claude-fable-5 和 claude-opus-4-8,看它们在真实开发任务里到底谁更稳、谁更快、谁更适合路由。
本次测试的核心问题很简单:
claude-fable-5是不是比claude-opus-4-8更强?claude-opus-4-8在什么地方仍然更稳?- 生产路由应该按“模型名”选,还是按“任务类型 + 输出验证”选?
想自己复测的话,直接用这个入口: Crazyrouter。
先说结论#
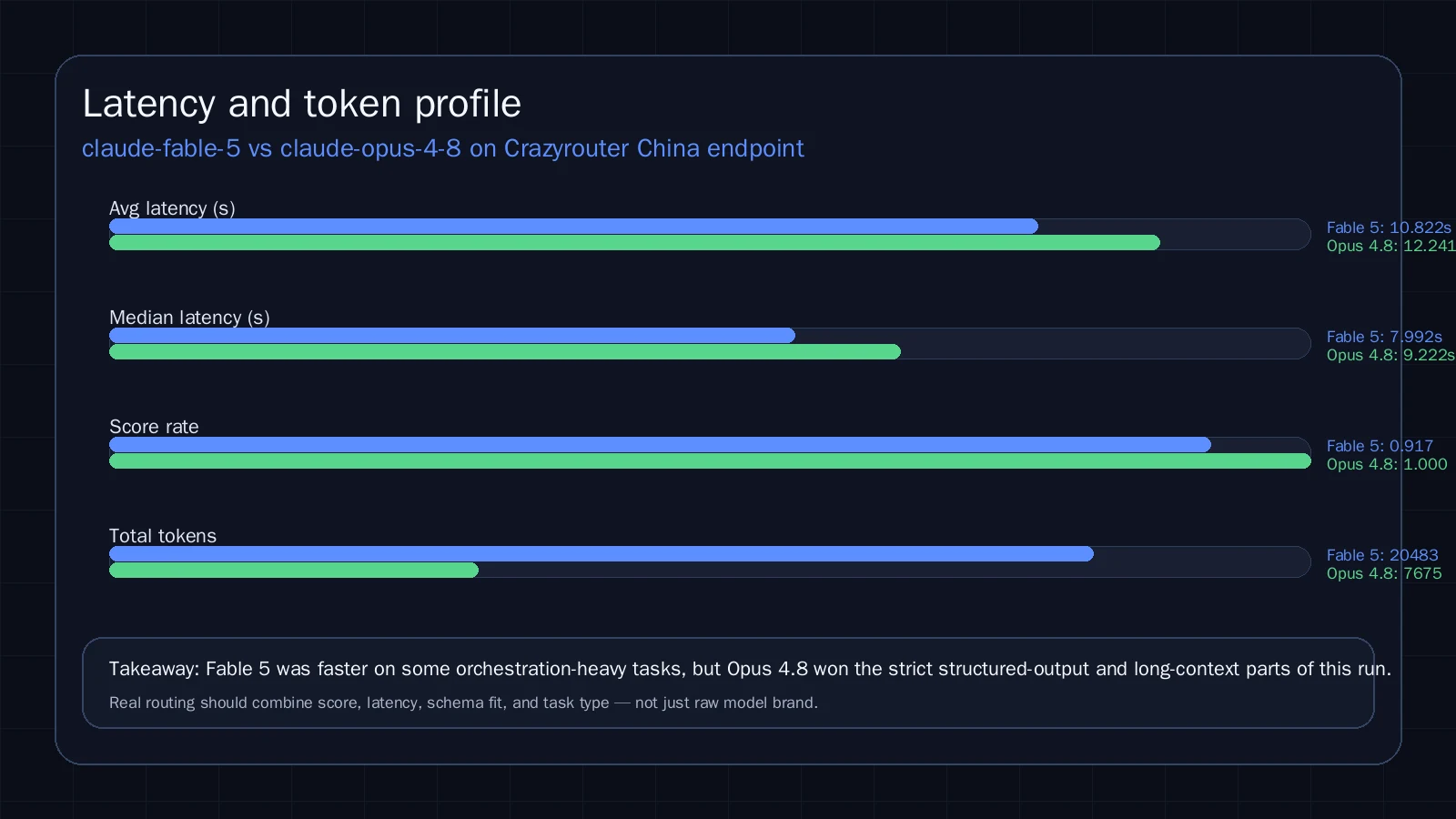
这轮实测的结果有点反直觉,但很有用:Opus 4.8 在总分上赢了,Fable 5 在部分工作流上更快。
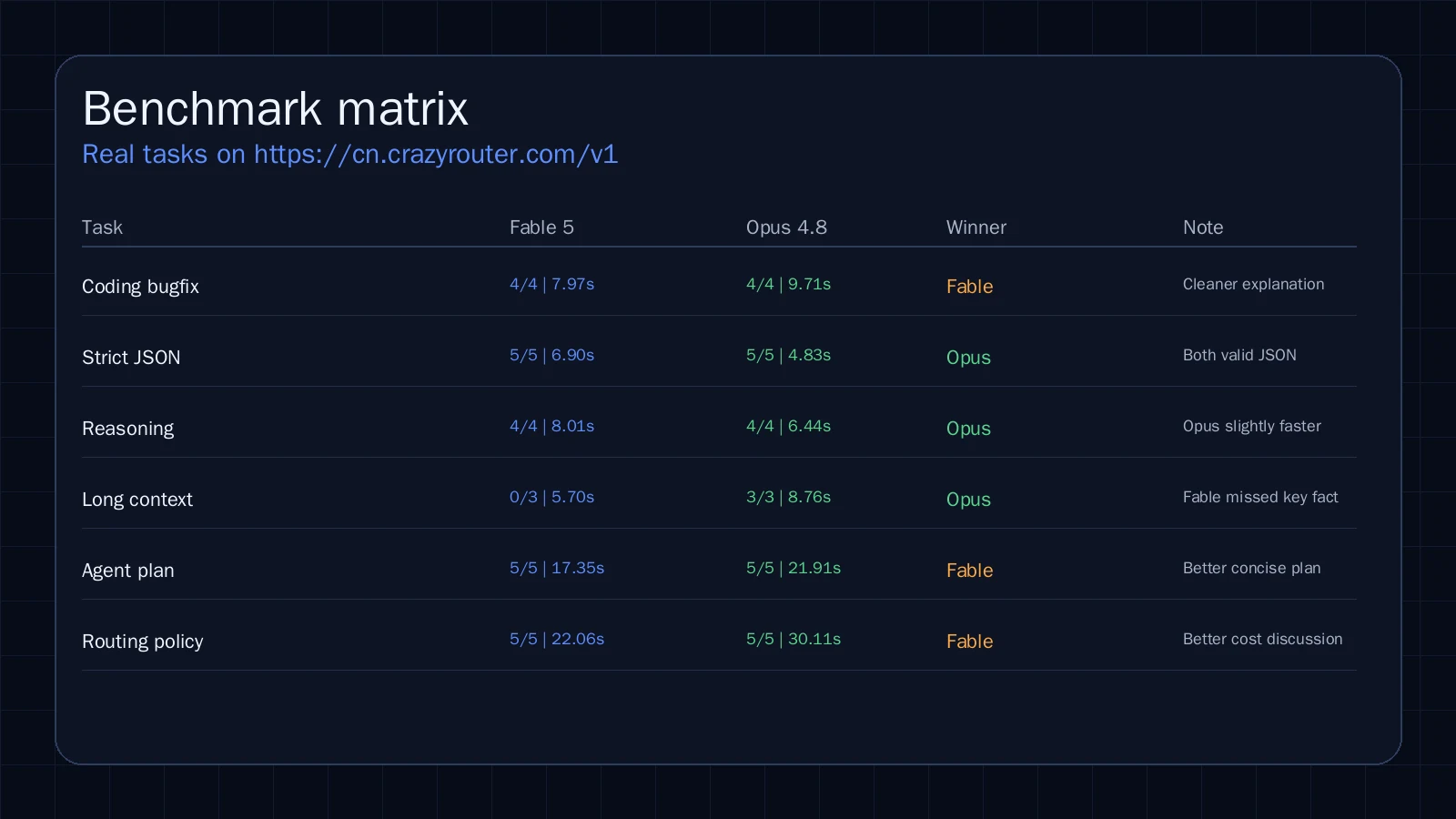
| Model | Tests | Success | Score | Avg latency | Median latency | Total tokens |
|---|---|---|---|---|---|---|
claude-fable-5 | 8 | 8/8 | 33/36 | 10.822s | 7.992s | 20483 |
claude-opus-4-8 | 8 | 8/8 | 36/36 | 12.241s | 9.222s | 7675 |
一句话翻译:
- Fable 5:更像一个偏 agent / orchestration 的模型,写 workflow、做路由策略时有优势。
- Opus 4.8:在严格 JSON、长上下文、推理、API Review 这类“生产验收题”上更稳。
- 真正该学的不是“谁赢了”,而是:怎么按任务路由,怎么按验证结果判定成功。
测试方法#
这次完全基于 Crazyrouter 中国区 API 实测:
- Base URL:
https://cn.crazyrouter.com/v1 - 模型:
claude-fable-5、claude-opus-4-8 - 任务数:8
- 维度:代码修复、严格 JSON、推理、长上下文、API Review、中文总结、Agent 计划、成本路由
- 记录内容:状态码、耗时、输出字符数、token、评分、错误情况
我们刻意没有把“HTTP 200”当成成功。因为在生产里,HTTP 200 但内容不合规,照样是失败。
实测代码#
import requests
base_url = "https://cn.crazyrouter.com/v1"
headers = {
"Authorization": f"Bearer YOUR_CRAZYROUTER_KEY",
"Content-Type": "application/json",
}
payload = {
"model": "claude-opus-4-8",
"messages": [{"role": "user", "content": "Return valid JSON only."}],
"max_tokens": 600,
}
resp = requests.post(f"{base_url}/chat/completions", headers=headers, json=payload, timeout=240)
print(resp.status_code)
print(resp.json()["choices"][0]["message"]["content"])
每项测试的实际表现#
1) 代码修复:Fable 5 略胜#
题目是修复一个 normalize_scores() 的零除 bug。
- Fable 5:
4/4,7.972s - Opus 4.8:
4/4,9.707s
Fable 5 给出的解释更直接,修复思路也更像工程师会写的 review note。
2) 严格 JSON:Opus 4.8 更快#
这个任务要求只输出 JSON,不要代码块,不要多余解释。
- Fable 5:
5/5,6.904s - Opus 4.8:
5/5,4.829s
两者都能正确输出,但 Opus 4.8 更短、更干净,也更适合做 schema 校验链路。
3) 推理:Opus 4.8 更顺手#
题目是两 worker 的依赖调度题,答案应为 11 分钟。
- Fable 5:
4/4,8.012s - Opus 4.8:
4/4,6.438s
两者都对,但 Opus 4.8 更像“直接给你可用答案”,少一点绕弯。
4) 长上下文:这是本轮最关键的分歧#
这个任务把关键信息埋在长噪声日志里,要求找出 request_id、模型和推荐 endpoint。
- Fable 5:
0/3,5.702s - Opus 4.8:
3/3,8.755s
这就是生产里最重要的信号之一:模型不是只看速度,长上下文召回失败就是失败。
这项里,Opus 4.8 明显更适合做日志抽取、事故分析、长文档定位。
5) API Review:Opus 4.8 更稳一点#
这个任务让模型审查一个 JavaScript API client,要求指出 timeout、headers、error handling、retries、endpoint config。
- Fable 5:
5/5,11.274s - Opus 4.8:
5/5,9.689s
两者都能完成,但 Opus 4.8 更简洁、更像 production review。
6) 中文总结:Opus 4.8 更像“可直接发出去”的版本#
- Fable 5:
5/5,7.302s - Opus 4.8:
5/5,6.495s
Fable 5 的中文输出也不错,但 Opus 4.8 的结构更平,适合直接用于文档或 notes。
7) Agent 工作流:Fable 5 更像在做流程设计#
这个题目要求设计一个 5 步安全工作流,包含测试、审批、回滚和证据。
- Fable 5:
5/5,17.354s - Opus 4.8:
5/5,21.909s
这个结果很有意思:Fable 5 在流程设计上更快,也更有“工作流模型”的味道。
8) 路由策略:Fable 5 更适合做成本与调度分析#
最后一道题让模型按任务类型比较 premium model 与 routed policy 的成本质量权衡。
- Fable 5:
5/5,22.055s - Opus 4.8:
5/5,30.109s
Fable 5 在这种“长篇路由分析 + 结构化归纳”的任务里更顺。
你该怎么选#
如果你是做真实产品,不建议只用一个模型打天下。我的建议是按任务路由:
如果任务偏:
- 严格 JSON / schema / 验证链路 / 长上下文抽取
优先 claude-opus-4-8
如果任务偏:
- Agent workflow / 路由策略 / 成本分析 / 流程设计
优先 claude-fable-5
如果任务输出会进入生产系统
不管哪个模型,都要做结构化校验和失败回退
更直白一点:
- Opus 4.8 是更稳的默认生产模型。
- Fable 5 是更适合复杂工作流和调度分析的模型。
- 你真正需要的不是“谁最强”,而是一个能按任务切换、能验证输出、能兜底的路由层。
为什么这类测试比排行榜更重要#
排行榜告诉你“模型在某个 benchmark 上的成绩”。
而真实产品需要知道:
- 它会不会在长日志里漏关键信息?
- 它会不会把 JSON 输出成半 Markdown 半 JSON?
- 它的耗时是否足够稳定?
- 它能不能承受你的真实 prompt 风格?
- 它适不适合放进自动化路由?
这就是为什么我更看重“真实 API 测试记录 + 成功率 + 输出质量 + 耗时”这几个维度,而不是单独看模型宣传。





