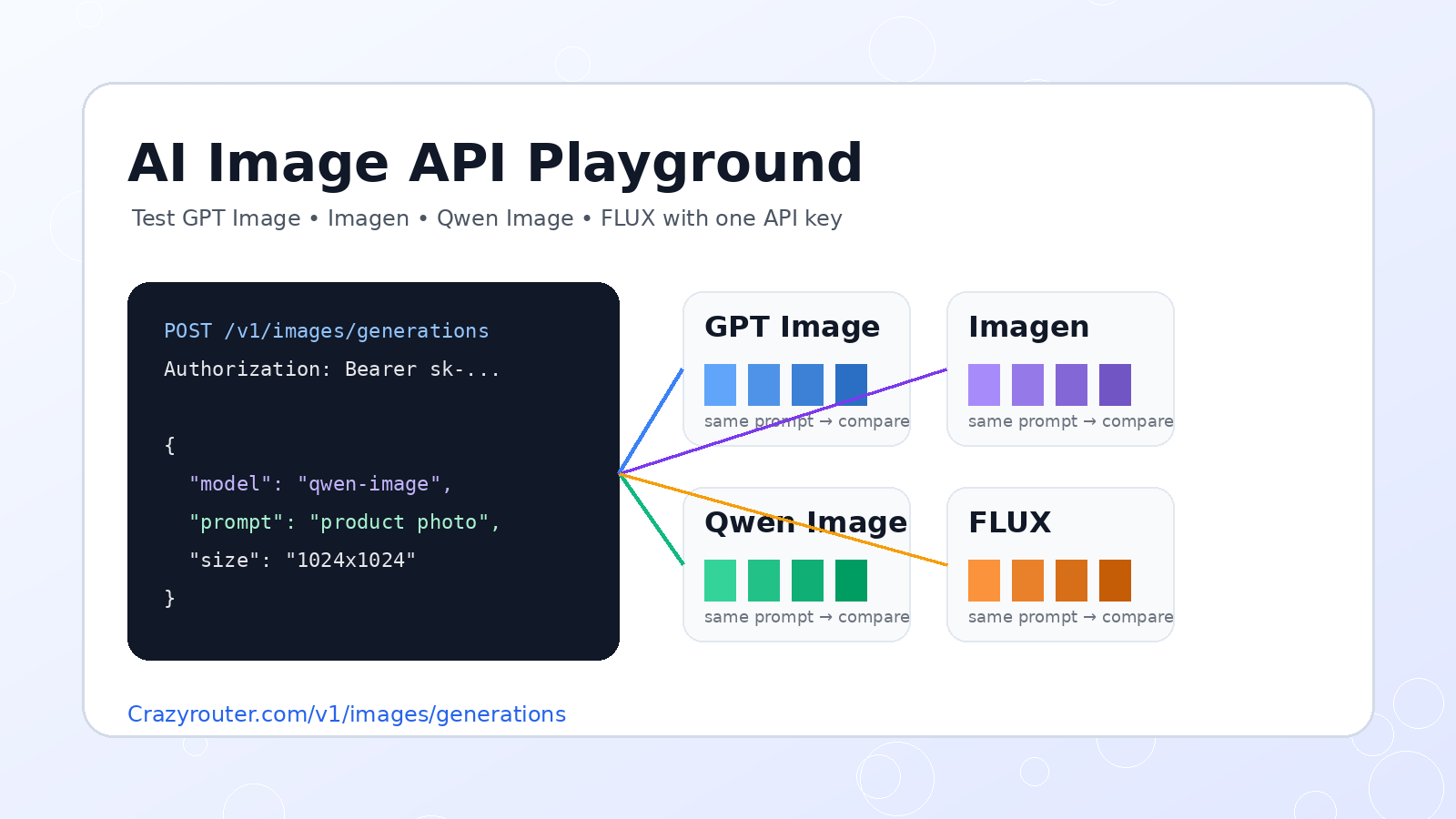
How to Access DeepSeek, Qwen and GLM Models with One API in 2026
A tested guide to accessing DeepSeek, Qwen and GLM model families through one OpenAI-compatible API endpoint using Crazyrouter.

How to Access DeepSeek, Qwen and GLM Models with One API in 2026#
DeepSeek, Qwen and GLM are now part of the serious production LLM stack. The problem is that integrating every provider separately creates API-key sprawl, different SDK patterns, separate billing flows and inconsistent monitoring.
The cleaner approach is to use one OpenAI-compatible gateway and switch model IDs by task.
Real Crazyrouter test#
Real test evidence used in this article:
Base URL: https://cn.crazyrouter.com/v1
Test date: 2026-06-18T14:58:18Z
GET /v1/models: HTTP 200, 620 ms, 262 models returned
DeepSeek routes found: 2
Qwen routes found: 20+
GLM routes found: 20+
Sample model families discovered by /v1/models:
- DeepSeek:
deepseek-v4-flash, deepseek-v4-pro - Qwen:
qwen3-vl-plus, qwen2.5-coder-14b-instruct, qwen2-vl-72b-instruct, qwen3-coder-480b-a35b-instruct, qwen3-vl-30b-a3b-instruct, qwen3-30b-a3b, qwen-plus, qwen2.5-72b-instruct - GLM:
glm-5v-turbo, glm-4-flash, glm-4.1v-thinking-flash, glm-5-turbo, glm-5, glm-4.5-flash, glm-4.5, glm-4v
This confirms that a single /v1/models endpoint exposed DeepSeek, Qwen and GLM routes in one model list.
Why this matters#
If you build with Chinese and global LLMs, you usually want:
- DeepSeek for cost-efficient reasoning/coding routes;
- Qwen for broad model family coverage, coding, vision and multilingual tasks;
- GLM for Chinese-language workflows, OCR/vision and agent tasks;
- GPT/Claude/Gemini fallbacks for quality-sensitive tasks;
- one billing and logging layer.
Basic OpenAI-compatible setup#
from openai import OpenAI
client = OpenAI(
api_key="YOUR_CRAZYROUTER_API_KEY",
base_url="https://cn.crazyrouter.com/v1",
)
resp = client.chat.completions.create(
model="qwen-plus",
messages=[{"role":"user","content":"Summarize this API design in 3 bullets."}],
temperature=0.2,
)
print(resp.choices[0].message.content)
To switch to another family, change only the model ID.
model="glm-4-flash"
# or model="deepseek-chat" depending on available route mapping
Model families found in this test#
DeepSeek routes#
deepseek-v4-flash, deepseek-v4-pro
Qwen sample routes#
qwen3-vl-plus, qwen2.5-coder-14b-instruct, qwen2-vl-72b-instruct, qwen3-coder-480b-a35b-instruct, qwen3-vl-30b-a3b-instruct, qwen3-30b-a3b, qwen-plus, qwen2.5-72b-instruct
GLM sample routes#
glm-5v-turbo, glm-4-flash, glm-4.1v-thinking-flash, glm-5-turbo, glm-5, glm-4.5-flash, glm-4.5, glm-4v
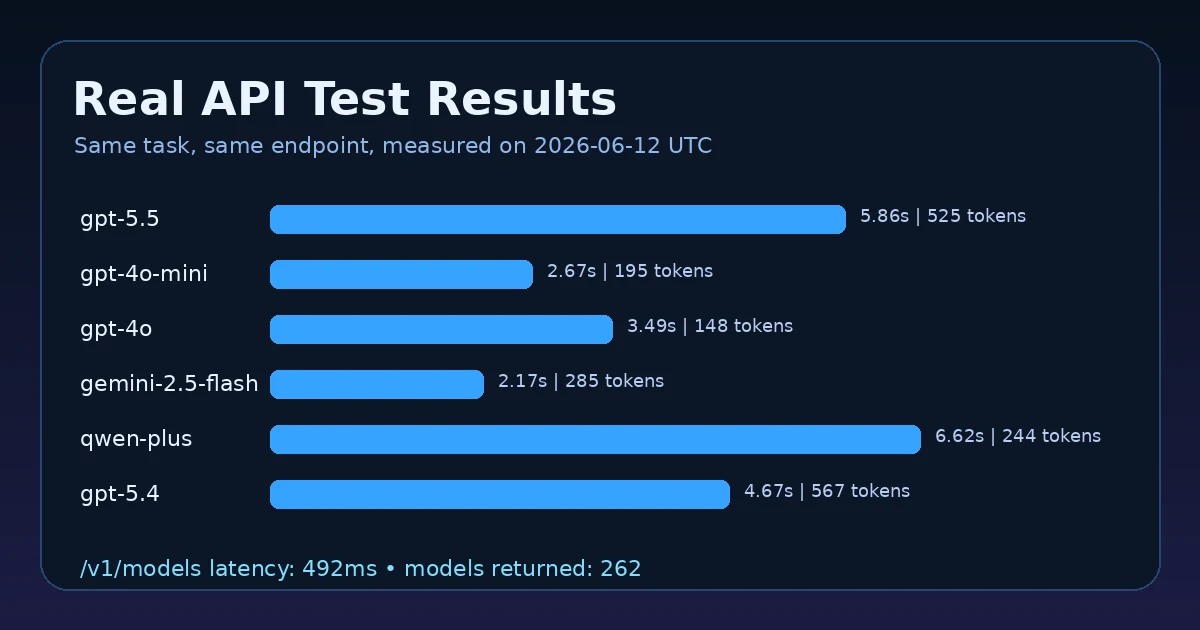
Live chat-completion test results#
| Tested model | HTTP | Latency | Prompt tokens | Completion tokens | Total tokens | Note |
|---|---|---|---|---|---|---|
gpt-4o-mini | 200 | 2.9s | 39 | 53 | 92 | stop |
qwen-plus | 200 | 3.69s | 40 | 42 | 82 | stop |
glm-4-flash | 200 | 5.54s | 34 | 47 | 81 | stop |
deepseek-chat | 200 | 3.27s | 36 | 180 | 216 | returned reasoning tokens, empty content at max_tokens=180; useful validation/fallback example |
qwen3-coder-480b-a35b-instruct | 200 | 28.53s | 40 | 47 | 87 | stop |
The result shows why production teams should validate outputs, not only HTTP status. Some routes returned clean content; the DeepSeek test hit the token limit and returned reasoning tokens without final content under this constrained prompt. That is exactly the kind of case where a gateway-based fallback strategy helps.
Recommended routing pattern#
| Task | First route | Fallback route | Validation |
|---|---|---|---|
| Low-cost summarization | Qwen or GLM flash route | GPT/Gemini mini route | non-empty content |
| Chinese content | GLM/Qwen | stronger Qwen/Claude/GPT route | language + facts |
| Coding helper | Qwen coder route | GPT/Claude coding route | tests/build output |
| Reasoning | DeepSeek route | GPT/Claude/Gemini route | final answer present |
| Extraction JSON | stable JSON route | retry with stricter schema | JSON parse |
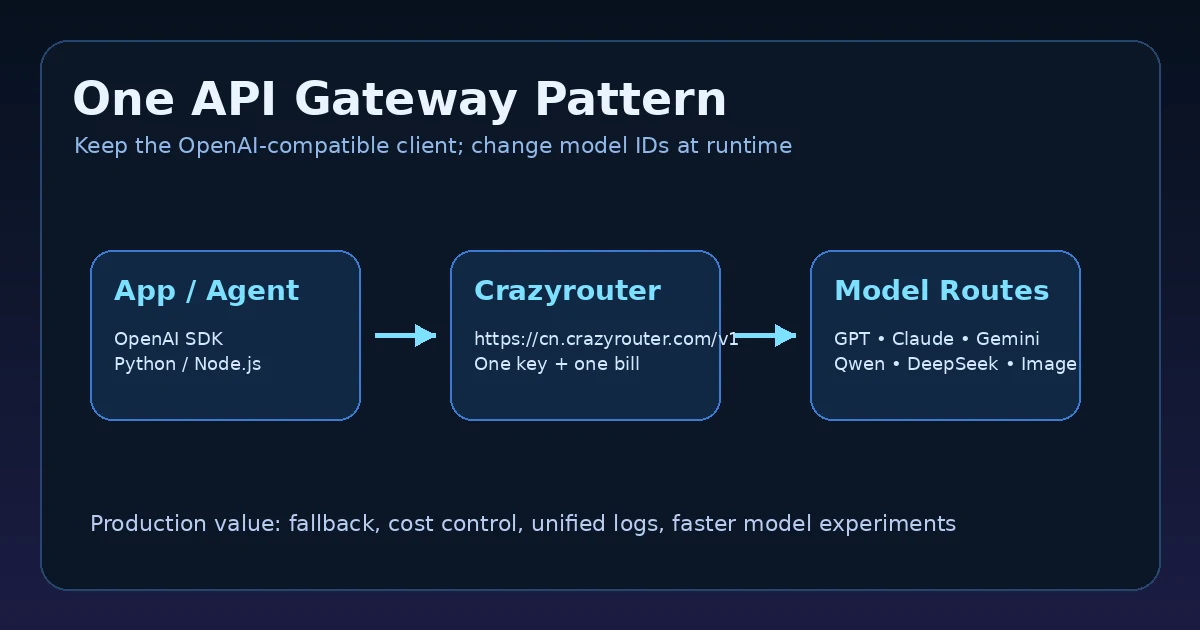
Why one API is better than separate integrations#
Separate integrations seem simple at first, but production complexity grows quickly:
- every provider has its own API key lifecycle;
- model IDs change;
- rate limits differ;
- usage fields vary;
- fallback logic becomes duplicated;
- finance teams lose one clean spending view.
A gateway turns this into one integration surface.
FAQ#
Can I access DeepSeek, Qwen and GLM with one API key?#
Yes. In this test, Crazyrouter exposed DeepSeek, Qwen and GLM routes through https://cn.crazyrouter.com/v1/models.
Is the API OpenAI-compatible?#
The tested Chat Completions flow uses the OpenAI SDK with base_url="https://cn.crazyrouter.com/v1".
Which model family should I use first?#
Use Qwen or GLM for many Chinese/multilingual tasks, DeepSeek for cost-efficient reasoning experiments, and stronger GPT/Claude/Gemini routes when accuracy or formatting needs escalation.
Is HTTP 200 enough?#
No. Always validate content, JSON shape, finish reason and token limits.
Bottom line#
DeepSeek, Qwen and GLM are useful individually, but they are much easier to operate through one gateway. Crazyrouter lets developers keep one OpenAI-compatible client while routing across Chinese and global model families.
Start here: Crazyrouter