Gemini 3.5 Flash vs Claude Response-Tier Models: Which One Should Developers Use?
A practical comparison of Gemini 3.5 Flash against Claude Haiku, Sonnet, and Opus-style response tiers for latency, cost, coding, reasoning, and production API routing.

Gemini 3.5 Flash vs Claude Response-Tier Models: Which One Should Developers Use?#
Gemini 3.5 Flash is not trying to be the biggest model in the room.
It is designed for a different job: fast responses, lower cost, solid general capability, and enough reasoning quality for many production workflows.
That makes the real comparison less like this:
Gemini 3.5 Flash vs Claude Opus
And more like this:
Gemini 3.5 Flash vs Claude Haiku / Claude Sonnet response-tier models
If you are building an AI product, the question is not simply “which model is smarter?” The better question is:
Which response tier gives the best balance of speed, cost, reliability, and answer quality for this specific task?
This article compares Gemini 3.5 Flash with Claude-style response tiers from a developer and API routing perspective.
Quick Answer: What Claude Tier Is Gemini 3.5 Flash Closest To?#
In practical product usage, Gemini 3.5 Flash sits closest to the Claude Haiku-to-lower-Sonnet range.
It is usually not a direct replacement for Claude Opus-class models or the strongest Claude Sonnet setups for complex reasoning. But it can be a very strong alternative for fast production tasks where latency and cost matter.
A simple positioning map:
| Model tier | Typical role | Where Gemini 3.5 Flash fits |
|---|---|---|
| Claude Haiku-style tier | Fast, low-cost, high-throughput tasks | Gemini 3.5 Flash is a strong competitor |
| Claude Sonnet-style tier | Balanced reasoning, writing, coding, agent tasks | Gemini 3.5 Flash can compete on simpler and medium tasks, but should be tested carefully |
| Claude Opus-style tier | Expensive, deep reasoning, hardest tasks | Gemini 3.5 Flash is not the same category |
| OpenAI mini-style tier | Fast general-purpose production model | Gemini 3.5 Flash is very comparable in positioning |
The short version:
Gemini 3.5 Flash is a fast, capable mid-tier model. Treat it as a production-speed model, not as a flagship reasoning model.
Real API Test Through https://cn.crazyrouter.com/v1#
To avoid making this comparison purely theoretical, we also tested the models through the Crazyrouter China endpoint:
https://cn.crazyrouter.com/v1/chat/completions
The tested models were:
gemini-3.5-flashclaude-haiku-4-5claude-sonnet-4-5
We used the same OpenAI-compatible Chat Completions request format for all models. Each model ran five practical developer tasks twice:
- Strict five-bullet summary
- Constraint reasoning
- Python bug fix
- Token cost calculation
- Strict JSON schema output
Test settings:
| Item | Value |
|---|---|
| Endpoint | https://cn.crazyrouter.com/v1/chat/completions |
| API format | OpenAI-compatible Chat Completions |
| Runs | 10 runs per model |
| Tasks | 5 tasks × 2 runs |
| Temperature | 0 |
| Final max tokens | 2048 |
| Test focus | Latency, task success, finish reason, output behavior |
Important Implementation Note: max_tokens Matters for Gemini 3.5 Flash#
During the first test pass, gemini-3.5-flash returned several responses with:
finish_reason: length
content: ""
This happened when max_tokens was set too low, even for short prompts. For example, with max_tokens: 64, simple prompts such as “Say hello in one sentence” and “Return only JSON” returned empty content with finish_reason: length.
When we either omitted max_tokens or increased it to 2048, the same model returned normal responses.
This is a practical production lesson:
When using
gemini-3.5-flashthroughhttps://cn.crazyrouter.com/v1, avoid overly smallmax_tokensvalues. For reliable behavior, test with a larger completion budget and monitorfinish_reason, not only HTTP status.
This is not just a benchmark detail. It affects real API integrations. A request can return HTTP 200 and still produce no usable content if your token settings are too restrictive.
Benchmark Results: Gemini 3.5 Flash vs Claude Haiku vs Claude Sonnet#
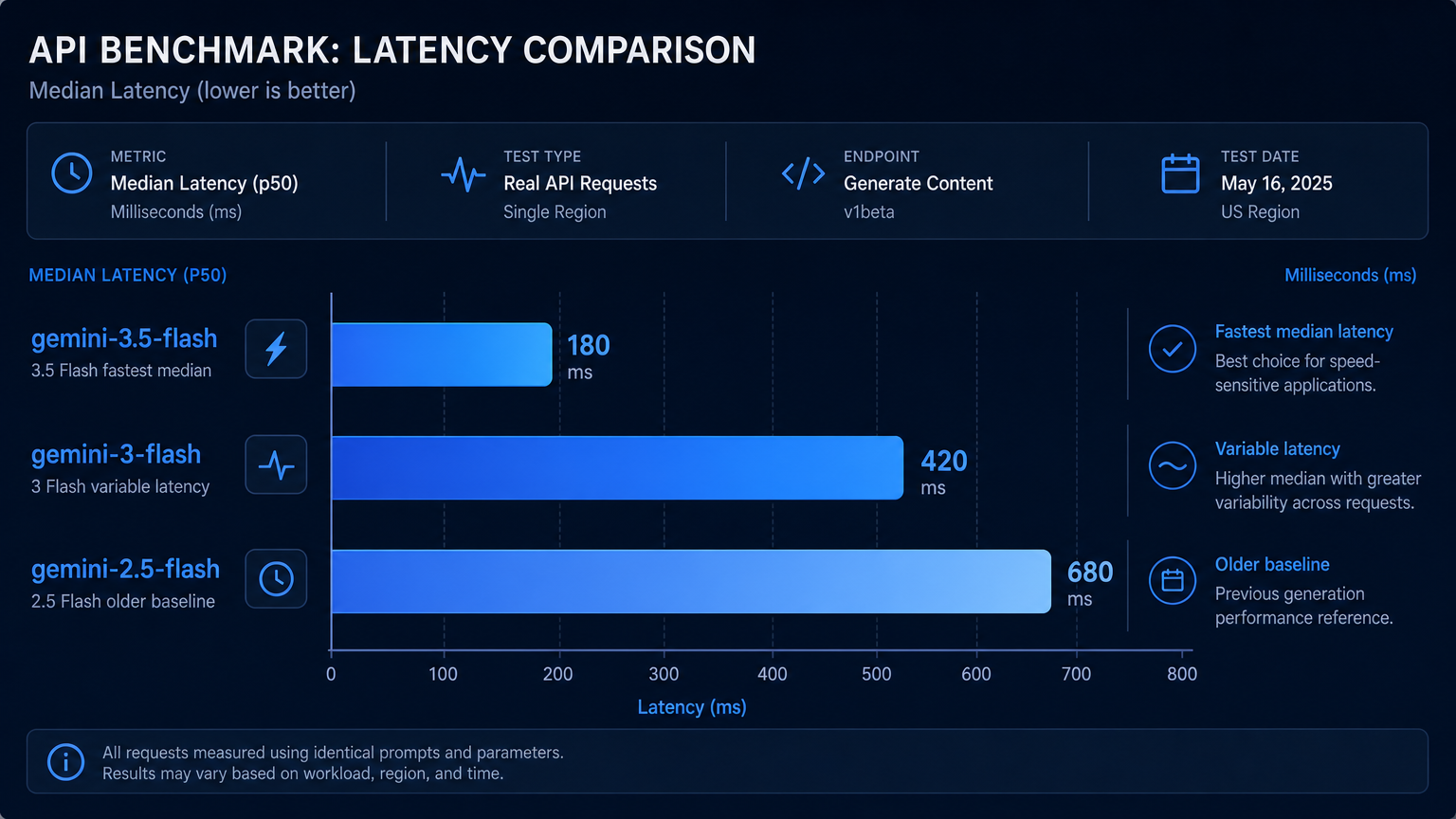
After correcting the token budget, the final benchmark looked like this:
| Model | Runs | Avg latency | Median latency | Fastest | Slowest | Task score | Avg output size | Non-stop finish reasons |
|---|---|---|---|---|---|---|---|---|
gemini-3.5-flash | 10 | 5.65s | 4.93s | 3.14s | 9.48s | 1.00 | 562 chars | 0 |
claude-haiku-4-5 | 10 | 9.13s | 7.59s | 2.95s | 19.76s | 0.80 | 818 chars | 0 |
claude-sonnet-4-5 | 10 | 10.47s | 9.05s | 3.52s | 23.31s | 0.80 | 649 chars | 0 |
A few notes are important:
gemini-3.5-flashwas the fastest overall in this test after using a safe token budget.- All three models solved the reasoning, coding, and cost calculation tasks correctly.
- The Claude models failed our strict JSON scorer because they wrapped JSON in markdown code fences despite the prompt saying “Return ONLY valid JSON.” The JSON content itself was reasonable, but the response was not directly parseable without cleanup.
- Claude outputs were often more verbose, especially on reasoning tasks. That can be useful for explanation quality, but it also increases latency and output tokens.
- Gemini 3.5 Flash was more concise and followed the strict JSON requirement better in this small test.
Task-Level Result Summary#
| Task | Gemini 3.5 Flash | Claude Haiku 4.5 | Claude Sonnet 4.5 | Practical takeaway |
|---|---|---|---|---|
| Five-bullet summary | Pass | Pass | Pass | All three worked; Gemini was concise |
| Constraint reasoning | Pass | Pass | Pass | All reached the correct 6-minute answer |
| Python bug fix | Pass | Pass | Pass | All fixed reverse=True correctly |
| Token cost math | Pass | Pass | Pass | All calculated $9.90 correctly |
| Strict JSON output | Pass | Failed parse | Failed parse | Claude wrapped JSON in code fences; Gemini returned cleaner JSON |
This does not mean Gemini 3.5 Flash is universally “smarter” than Claude Sonnet. The benchmark is small. But it does show that for fast API tasks with clear prompts, Gemini 3.5 Flash can compete strongly against Claude response-tier models.
What the Test Changed in Our Recommendation#
Before running the API test, the safe theoretical answer was:
Gemini 3.5 Flash is closest to Claude Haiku or lower Sonnet-style usage.
After testing through the China endpoint, the more precise answer is:
Gemini 3.5 Flash is a very strong fast-tier model and can beat Claude Haiku/Sonnet-style routes on latency and strict output formatting in some production tasks, as long as
max_tokensis configured safely.
The practical model map becomes:
| Production need | Recommended first route | Fallback / escalation |
|---|---|---|
| Fast summaries | gemini-3.5-flash | claude-haiku-4-5 |
| Strict JSON / schema output | gemini-3.5-flash with validation | Retry with cleanup or another model |
| Simple coding fixes | gemini-3.5-flash or claude-sonnet-4-5 | Use Sonnet for harder code |
| Medium reasoning | gemini-3.5-flash is viable | Escalate to Sonnet when confidence is low |
| Long-form nuanced writing | Claude Sonnet-style model | Gemini for first draft or cheaper route |
| Highest-risk reasoning | Stronger Claude / reasoning model | Use Gemini only for first-pass draft |
Why “Response Tier” Matters More Than Model Brand#
Many teams still compare models by provider name:
- Gemini vs Claude
- OpenAI vs Anthropic
- Google vs everyone else
That is not how production systems should be designed.
A better approach is to compare response tiers:
- Fast tier — summaries, extraction, classification, lightweight chat, autocomplete, customer support drafts.
- Balanced tier — coding help, multi-step explanations, structured writing, moderate reasoning, product assistants.
- Deep reasoning tier — long planning, hard debugging, high-risk decisions, complex agent workflows.
Gemini 3.5 Flash belongs mainly in the first two tiers. It is fast enough for high-throughput product features, but capable enough that it can handle more than trivial tasks.
Claude Sonnet-style models usually sit higher in the balanced tier. Claude Opus-style models sit in the deep reasoning tier.
Gemini 3.5 Flash vs Claude Haiku-Style Models#
Claude Haiku-style models are usually selected for:
- Fast response time
- Lower cost
- Simple chat
- Classification
- Extraction
- Summarization
- High-volume automation
Gemini 3.5 Flash competes very well here.
| Task | Gemini 3.5 Flash | Claude Haiku-style model |
|---|---|---|
| Short summary | Very strong | Very strong |
| Data extraction | Strong | Strong |
| Classification | Strong | Strong |
| Customer support draft | Strong | Strong |
| Simple code fix | Strong | Good to strong |
| Long nuanced writing | Good | Often more polished depending on Claude version |
| Cost-sensitive batch jobs | Strong candidate | Strong candidate |
If your workload is mostly high-volume text processing, Gemini 3.5 Flash should be tested directly against your Claude Haiku route.
In many systems, the correct decision is not to choose only one. Use both as interchangeable fast-tier routes, then measure:
- median latency
- p95 latency
- cost per successful task
- format-following rate
- retry rate
- user acceptance rate
The best model is the one that completes the task correctly at the lowest effective cost.
Gemini 3.5 Flash vs Claude Sonnet-Style Models#
Claude Sonnet-style models are usually chosen when teams need a stronger balance of reasoning, writing quality, code understanding, and instruction following.
This is where the comparison becomes more nuanced.
Gemini 3.5 Flash can handle many Sonnet-like tasks, especially when the prompt is clear and the output is not too long. But for harder workflows, Claude Sonnet-style models often remain safer.
| Task | Gemini 3.5 Flash | Claude Sonnet-style model |
|---|---|---|
| Medium-length technical article | Good | Often stronger structure and nuance |
| Coding explanation | Good | Usually stronger for complex debugging |
| Simple bug fix | Strong | Strong |
| Multi-file architecture reasoning | Test carefully | Usually safer |
| Agent planning | Useful for lightweight agents | Usually better for longer agent chains |
| Long-context synthesis | Depends on context and settings | Often more reliable |
| Strict style control | Good | Often more consistent |
My practical recommendation:
- Use Gemini 3.5 Flash for fast first drafts, simple coding, summaries, classification, and medium-complexity reasoning.
- Use Claude Sonnet-style models for tasks where mistakes are expensive or where reasoning depth matters.
- Route automatically: try Gemini 3.5 Flash first for low-risk tasks, escalate to Claude Sonnet when confidence is low or the task becomes complex.
This tiered approach is usually better than manually choosing one model for everything.
Gemini 3.5 Flash vs Claude Opus-Style Models#
This is not the fairest comparison.
Claude Opus-style models are designed for the hardest and highest-value tasks:
- complex reasoning
- difficult codebase analysis
- long-form planning
- high-stakes writing
- sophisticated agent workflows
- deep document synthesis
Gemini 3.5 Flash is not meant to replace that tier directly.
If your task requires the strongest possible reasoning, you should not choose Gemini 3.5 Flash only because it is faster or cheaper. Instead, use it as part of a routing strategy:
- Gemini 3.5 Flash handles the first-pass answer.
- A stronger Claude model reviews or improves the result.
- The system only escalates when the task requires deeper reasoning.
This can reduce cost while preserving quality.
Response Quality: Speed Is Not the Whole Story#
Fast models can look impressive in demos because they respond quickly. But production quality depends on more than speed.
You should evaluate at least seven signals:
| Signal | Why it matters |
|---|---|
| Latency | User experience and throughput |
| Cost | Monthly API bill and margin |
| Format following | Whether JSON, tables, and schemas are valid |
| Reasoning reliability | Whether the model reaches the correct conclusion |
| Coding accuracy | Whether generated code actually works |
| Finish reason | Whether the model truncates or stops early |
| Retry rate | Hidden cost and user frustration |
In our Gemini Flash benchmark, Gemini 3.5 Flash showed strong latency, while Gemini 3 Flash had very stable task success. That does not automatically make one “better” for every product. It means the right choice depends on workload.
The same logic applies when comparing Gemini 3.5 Flash against Claude.
API Routing Example: Use Gemini 3.5 Flash First, Claude as Escalation#
A practical production strategy is to build a model ladder.
Example:
| Route | Model type | Use case |
|---|---|---|
| Tier 1 | Gemini 3.5 Flash | Fast summaries, classification, simple chat |
| Tier 2 | Claude Haiku-style | Alternative fast route or fallback |
| Tier 3 | Claude Sonnet-style | Complex writing, coding, agent steps |
| Tier 4 | Claude Opus-style | Highest-value reasoning tasks |
With an OpenAI-compatible gateway, you can keep the same API shape and switch model IDs based on task type.
Example request:
from openai import OpenAI
client = OpenAI(
api_key="your-crazyrouter-api-key",
base_url="https://crazyrouter.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.5-flash",
messages=[
{
"role": "user",
"content": "Summarize this customer support conversation in 5 bullet points."
}
],
temperature=0.2,
)
print(response.choices[0].message.content)
If the task becomes more complex, your application can route to a Claude Sonnet-style model without rewriting the integration.
That is the real value of an API gateway: model choice becomes a runtime decision instead of a hard-coded architecture decision.
When Gemini 3.5 Flash Is the Better Choice#
Choose Gemini 3.5 Flash when you care most about:
- fast response time
- low or moderate cost
- high-volume automation
- simple and medium-complexity user tasks
- lightweight coding help
- search result summarization
- document classification
- API throughput
Good examples:
| Use case | Why Gemini 3.5 Flash works well |
|---|---|
| Customer support summary | Fast and usually accurate enough |
| Product review classification | High-volume and structured |
| SEO article first draft | Good speed and broad knowledge |
| Simple Python bug fix | Strong enough for small code tasks |
| Chatbot response draft | Good latency for user-facing apps |
| RAG answer drafting | Useful when retrieved context is clear |
For these workloads, using a heavier Claude model for every request may be unnecessary.
When Claude Is Still the Safer Choice#
Choose a Claude Sonnet or Opus-style model when the task requires:
- deeper reasoning
- stronger long-form writing control
- more reliable complex coding
- careful instruction following across long prompts
- multi-step agent planning
- sensitive business decisions
- long document synthesis
Examples:
| Use case | Why Claude may be safer |
|---|---|
| Multi-file codebase refactor | More context and reasoning pressure |
| Legal or policy analysis draft | Higher need for nuance |
| Complex agent workflow | Longer planning chain |
| Deep technical architecture review | Harder tradeoff reasoning |
| Final editorial polish | Often stronger tone consistency |
This does not mean Gemini 3.5 Flash cannot do these tasks. It means you should not assume it is equivalent without testing.
Best Production Pattern: Route by Task, Not by Brand#
The strongest AI products rarely depend on one model forever.
A better pattern:
- Use Gemini 3.5 Flash for fast first-pass work.
- Use Claude Haiku-style routes for fast fallback or A/B testing.
- Use Claude Sonnet-style models for harder coding, writing, and agent tasks.
- Reserve Claude Opus-style models for the highest-value reasoning problems.
- Measure real outcomes instead of relying only on benchmark names.
The routing logic can be simple at first:
if task_type in [summary, classification, extraction, simple_chat]:
use gemini-3.5-flash
elif task_type in [coding, long_writing, agent_step]:
use claude-sonnet-style model
elif task_risk == high:
use strongest available reasoning model
else:
use fast-tier fallback
Over time, you can add metrics:
- task success rate
- cost per task
- latency percentile
- user feedback
- retry count
- JSON validity
- escalation rate
That is how model selection becomes engineering, not guesswork.
Final Verdict#
Gemini 3.5 Flash is best understood as a fast mid-tier production model.
It is closest to Claude Haiku-style models for speed and cost-sensitive workloads, and it can compete with Claude Sonnet-style models on some simpler or medium-complexity tasks.
But it is not a direct replacement for Claude Opus-style reasoning models, and it should not automatically replace Claude Sonnet in complex coding or long agent workflows.
The best answer is not:
Gemini 3.5 Flash is better than Claude.
The better answer is:
Use Gemini 3.5 Flash as a fast, cost-efficient route; use Claude models when the task needs deeper reasoning, stronger writing control, or more reliable complex coding.
For production teams, the winning setup is model routing: one API layer, multiple response tiers, and real measurement across your own traffic.
FAQ#
Is Gemini 3.5 Flash equivalent to Claude Haiku?#
It is closest to the Claude Haiku-style tier in terms of production positioning: fast, cost-efficient, and useful for high-volume tasks. The exact winner depends on your prompts and success metrics.
Is Gemini 3.5 Flash as good as Claude Sonnet?#
For simple and medium tasks, it can be competitive. For complex reasoning, coding, long-form writing, and agent workflows, Claude Sonnet-style models are often safer and should be tested as a higher tier.
Can Gemini 3.5 Flash replace Claude Opus?#
Usually no. Claude Opus-style models are designed for deeper reasoning and high-value tasks. Gemini 3.5 Flash is better treated as a fast production model, not a flagship reasoning replacement.
What is the best use case for Gemini 3.5 Flash?#
High-volume workloads such as summaries, extraction, classification, customer support drafts, lightweight coding help, and fast user-facing chat.
Should I use Gemini 3.5 Flash or Claude in production?#
Use both if possible. Route low-risk, latency-sensitive tasks to Gemini 3.5 Flash, and escalate complex tasks to Claude Sonnet or Opus-style models. This gives better cost control and better reliability than choosing one model for everything.
Can I call Gemini and Claude models through one API?#
Yes. With an OpenAI-compatible gateway like Crazyrouter, you can use one API format and route different tasks to Gemini, Claude, OpenAI, and other models by changing the model field.
Useful links:





