中文Tutorial
AI API 成本管控实战:团队如何统一管理 Claude、GPT、DeepSeek 的消费
团队使用多个 AI 模型时,成本容易失控。本文分享实际的成本管控方法:智能路由、用量监控、消费明细导出,帮助技术负责人把 AI API 支出控制在预算内。
C
Crazyrouter Team
April 16, 2026 / 448 views
Share:

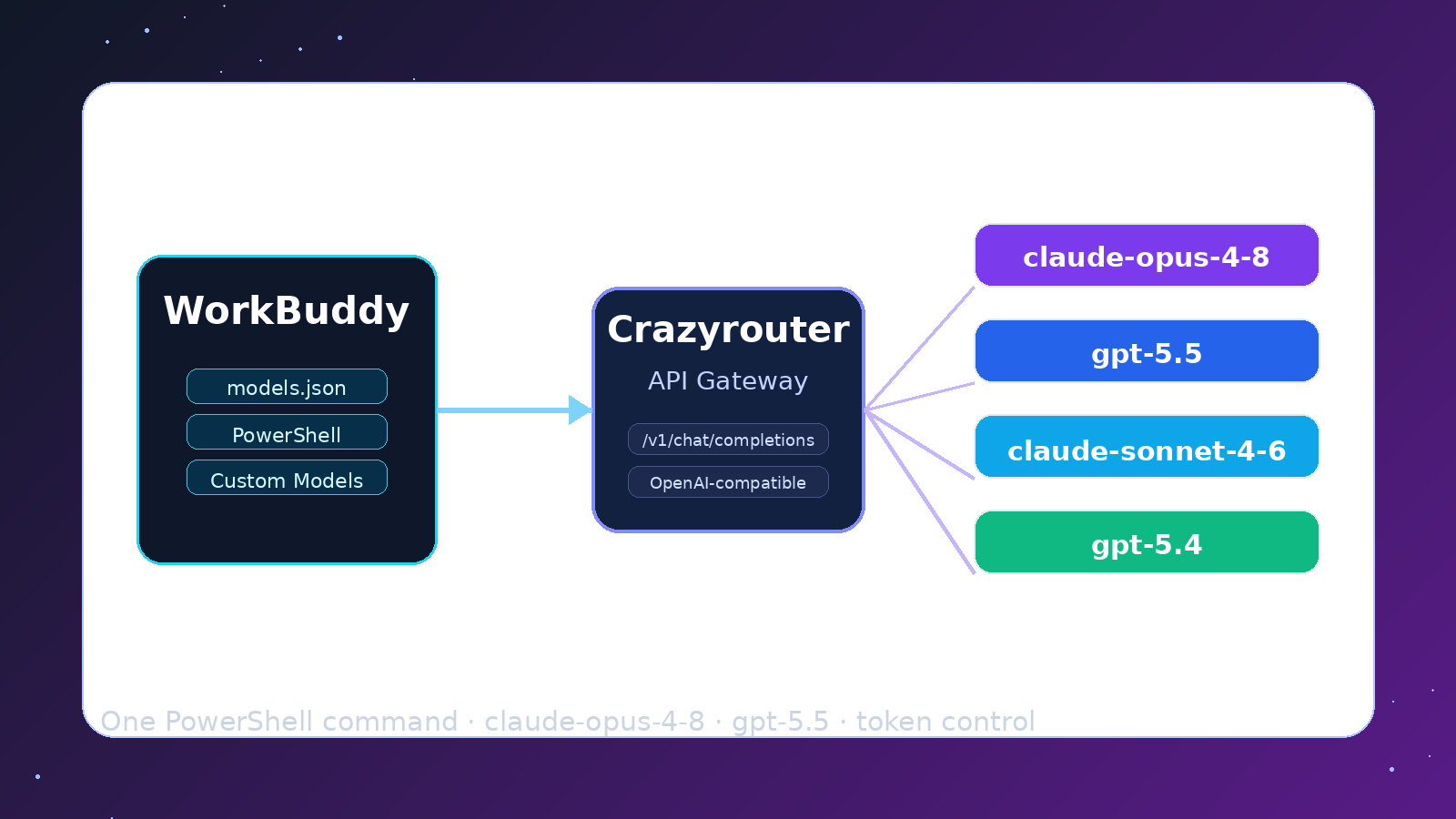
Crazyrouter
AI API 成本管控实战:团队如何统一管理 Claude、GPT、DeepSeek 的消费#
成本失控的常见原因#
团队用 AI API 超预算,通常不是因为单价贵,而是因为:
- 没有统一的消费视图 — 各模型消费分散在不同平台,没人知道总数
- 没有按任务选模型 — 所有任务都用最贵的模型
- 没有用量限额 — 某个成员或某个项目突然跑了大量请求
- Prompt 没有优化 — 输入 Token 浪费严重
- 没有缓存 — 相同请求重复调用
方法一:智能路由 — 按任务复杂度选模型#
这是最有效的省钱方法。不是所有任务都需要最强的模型。
| 任务类型 | 推荐模型 | 大约成本 |
|---|---|---|
| 简单分类、提取 | GPT-5 Nano | 0.40 per 1M |
| 日常对话、摘要 | GPT-5 Mini / DeepSeek | 2.00 per 1M |
| 代码生成、分析 | Claude Sonnet 4.6 | 8.25 per 1M |
| 复杂推理 | o3 / Claude Opus 4 | 30+ per 1M |
价格差距可以达到 100 倍以上。
python
from openai import OpenAI
client = OpenAI(
api_key="your-key",
base_url="https://crazyrouter.com/v1"
)
def smart_route(task_type, prompt):
"""按任务类型自动选择最经济的模型"""
model_map = {
"classify": "gpt-5-nano", # 最便宜
"summarize": "gpt-5-mini", # 性价比
"code": "claude-sonnet-4.6", # 代码最强
"reason": "o3", # 复杂推理
"chinese": "deepseek-chat", # 中文优化
}
model = model_map.get(task_type, "gpt-5-mini")
return client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
# 简单分类任务 → 用最便宜的模型
result = smart_route("classify", "这条评论是正面还是负面:产品很好用")
# 代码生成 → 用 Claude
result = smart_route("code", "写一个 Python 异步爬虫框架")
实际效果:同样的工作量,成本可以降低 60-80%。
方法二:消费监控 — 知道钱花在哪#
按模型统计#
后台可以看到每个模型的调用次数和消费金额:
| 模型 | 调用次数 | 消费 |
|---|---|---|
| claude-sonnet-4.6 | 1,200 | $18.50 |
| gpt-5-mini | 8,500 | $4.20 |
| gpt-5-nano | 15,000 | $1.80 |
| deepseek-chat | 3,200 | $2.10 |
| 合计 | 27,900 | $26.60 |
按成员统计#
给每个团队成员分配独立的 API Key,消费自动隔离:
| 成员 | 消费 | 主要模型 |
|---|---|---|
| 张三 | $12.30 | Claude Sonnet |
| 李四 | $8.20 | GPT-5 Mini |
| 王五 | $6.10 | DeepSeek |
消费明细导出#
支持导出 CSV 格式的详细消费记录,包含:
- 调用时间
- 使用模型
- 输入/输出 Token 数
- 单次消费金额
适合做项目经费核算、月度成本报告。
方法三:用量限额 — 防止意外超支#
给每个 API Key 设置消费上限:
- 实习生的 Key:月上限 $10
- 普通成员:月上限 $50
- 项目负责人:月上限 $200
达到上限后自动停止服务,避免一个失控的脚本把预算烧光。
方法四:Prompt 优化 — 减少无效 Token#
系统提示词精简#
很多团队的 system prompt 写了几千字,但大部分是无效信息。精简 system prompt 可以减少 30-50% 的输入 Token。
上下文窗口管理#
不要每次都把完整对话历史发过去。只保留最近 N 轮对话,或者用摘要替代历史消息。
输出长度控制#
设置 max_tokens 限制输出长度,避免模型生成不必要的长回复。
实际案例:某团队的成本优化效果#
| 指标 | 优化前 | 优化后 | 变化 |
|---|---|---|---|
| 月度 API 支出 | $850 | $280 | -67% |
| 平均每次调用成本 | $0.034 | $0.008 | -76% |
| 使用模型数 | 1 (GPT-5) | 4 (混合路由) | +3 |
| 任务完成质量 | 基准 | 持平 | 无下降 |
关键改变:
- 简单任务从 GPT-5 切到 GPT-5 Nano(省 95%)
- 中文任务用 DeepSeek(省 60%,效果更好)
- 只有复杂任务才用 Claude 或 o3
- 设置了用量限额,杜绝意外超支
如何开始#
- 注册 Crazyrouter 账号
- 充值少量金额测试
- 按团队成员创建多个 API Key
- 实现智能路由逻辑
- 每周查看消费报告,持续优化
机构采购咨询:support@crazyrouter.com
Implementation Guides
AuthenticationCreate and use API keys with the required authorization headers.Usage Logs and Cost MonitoringUse management APIs to query logs, quota, token usage, and dollar cost.Claude Native FormatCall Claude through the Anthropic Messages API on Crazyrouter.Quick Start GuideMake the first Crazyrouter API call and validate your setup.
Crazyrouter
Topics
Tutorial