Anthropic API Billing Explained: How Claude API Charges Work in 2026
A practical guide to Anthropic API billing in 2026: input tokens, output tokens, prompt caching, Claude pricing examples, hidden cost drivers, and ways to reduce API spend.

Anthropic API Billing Explained: How Claude API Charges Work in 2026#
Anthropic API billing looks simple at first: send a prompt, receive a Claude response, pay for tokens. In real production workloads, it gets more complicated. You have input tokens, output tokens, cached prompt tokens, long-context requests, retries, tool calls, agents, batch jobs, and multiple environments using the same API key.
If you are building with Claude in 2026, understanding billing is not optional. It directly affects your product margins, rate-limit strategy, model choice, and user experience.
This guide explains how Anthropic API billing works, why Claude API costs can surprise teams, and how to reduce spend without lowering output quality.
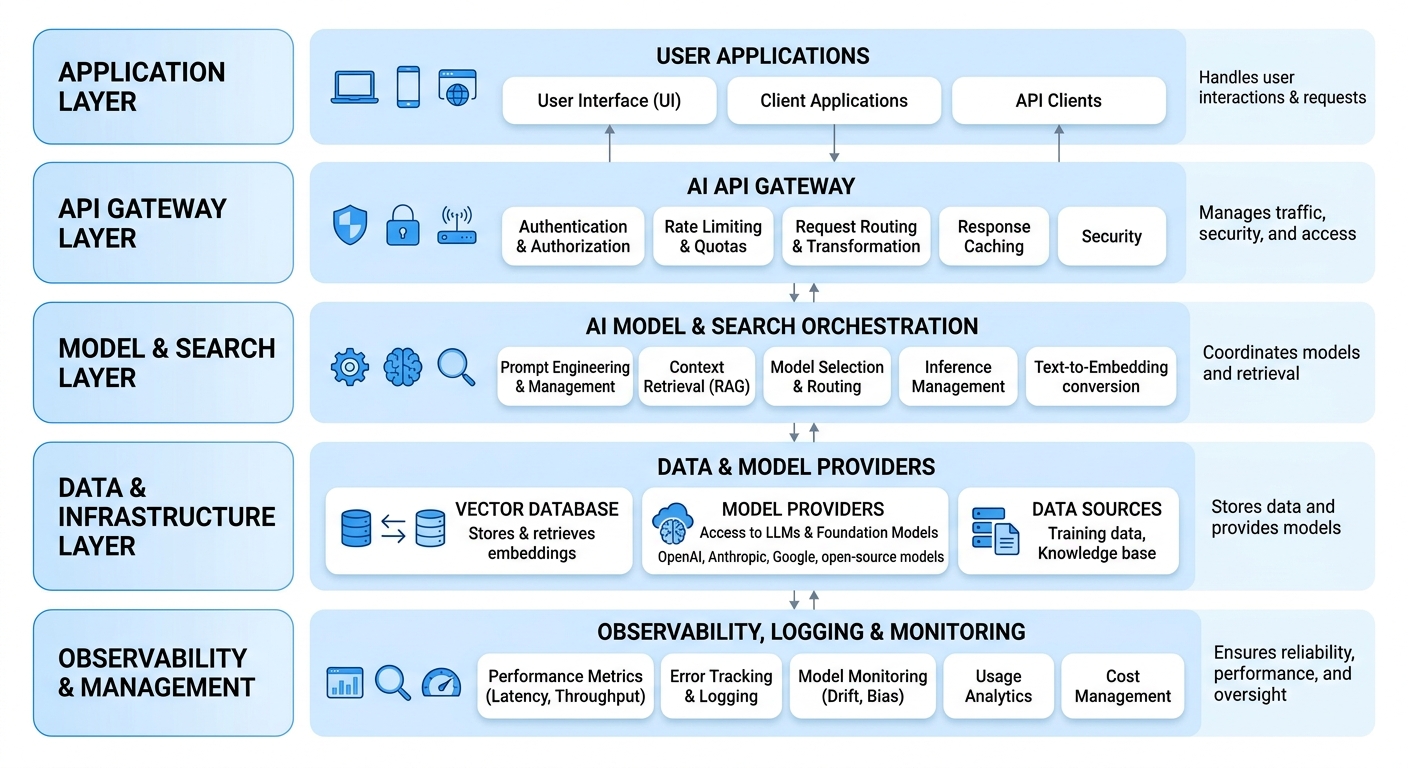
Quick answer: how Anthropic API billing works#
Anthropic API billing is usually based on token usage:
- Input tokens: text, images, tool schemas, system prompts, previous conversation history, and context you send to Claude.
- Output tokens: the tokens Claude generates in the response.
- Cached tokens: reusable prompt/context segments that may be billed differently when prompt caching is enabled.
- Model tier: larger Claude models cost more than smaller/faster Claude models.
- Request pattern: retries, long conversations, agents, and tool loops multiply token usage.
The most important point: you pay for both what you send and what the model returns. A short user question can still become expensive if your application attaches a large system prompt, long chat history, retrieved documents, or verbose tool definitions.
Input tokens vs output tokens#
Most Claude API cost analysis starts with input and output tokens.
| Billing component | What it includes | Why it matters |
|---|---|---|
| Input tokens | User message, system prompt, chat history, retrieved documents, tool definitions | Often grows silently as apps mature |
| Output tokens | Claude's generated response | Controlled by max tokens, prompt style, and task type |
| Cached input tokens | Reused context or prompt sections | Can reduce repeated long-context cost |
| Tool call overhead | Tool schemas, arguments, observations | Important for agent workflows |
For example, a support chatbot might look cheap during testing because each prompt has only a few lines. After launch, the same chatbot may attach:
- a 1,000-token system prompt,
- a 4,000-token knowledge-base excerpt,
- previous conversation history,
- tool definitions,
- and a long final answer.
The user only sees one short message, but the API bill sees every token.
Claude API billing example#
Here is a simplified example. Imagine your app sends a request with:
- 3,000 input tokens,
- 800 output tokens,
- no prompt caching,
- one Claude model selected for quality.
Your actual cost depends on the model's published input/output token pricing. But the calculation pattern is always similar:
Request cost = input_tokens × input_price_per_token
+ output_tokens × output_price_per_token
If your app retries the same request twice after timeout, you may pay for three attempts. If your agent runs five reasoning/tool steps, you may pay for five model calls. If your RAG pipeline attaches too many documents, input costs can dominate.
That is why production teams should track cost by workflow, not just by model.
Why Anthropic API costs surprise teams#
1. Long context is useful, but not free#
Claude models are popular for long-context work: documents, codebases, research notes, legal text, customer records, and multi-turn analysis. Long context is powerful, but every request that includes large context increases input token cost.
A common mistake is sending the entire conversation or full document set every time. Better patterns include:
- summarize old conversation turns,
- retrieve only the most relevant chunks,
- cache stable instructions,
- split analysis into staged tasks,
- use smaller models for extraction and routing.
2. Output tokens can be more expensive than expected#
Many teams optimize prompts but forget to control answer length. If your app asks for comprehensive answers, multi-section reports, code, JSON, and explanations, output tokens rise quickly.
Use explicit constraints:
Return at most 8 bullet points.
Keep the answer under 300 words.
Return JSON only.
Do not repeat the full source text.
3. Agents multiply requests#
Claude-based agents often call the model many times per user task:
- understand the request,
- plan,
- call tools,
- inspect results,
- revise the plan,
- generate output,
- self-check.
This can be worth it for complex coding or research tasks, but billing should be measured per completed task, not per single API call.
4. Retries and fallbacks are hidden cost drivers#
Retries are necessary in production. But every retry can duplicate token cost. If your retry logic is too aggressive, billing rises without improving user experience.
Use:
- timeout budgets,
- exponential backoff,
- idempotency keys where supported,
- cheaper fallback models for simple retries,
- logs that show retry count per request.
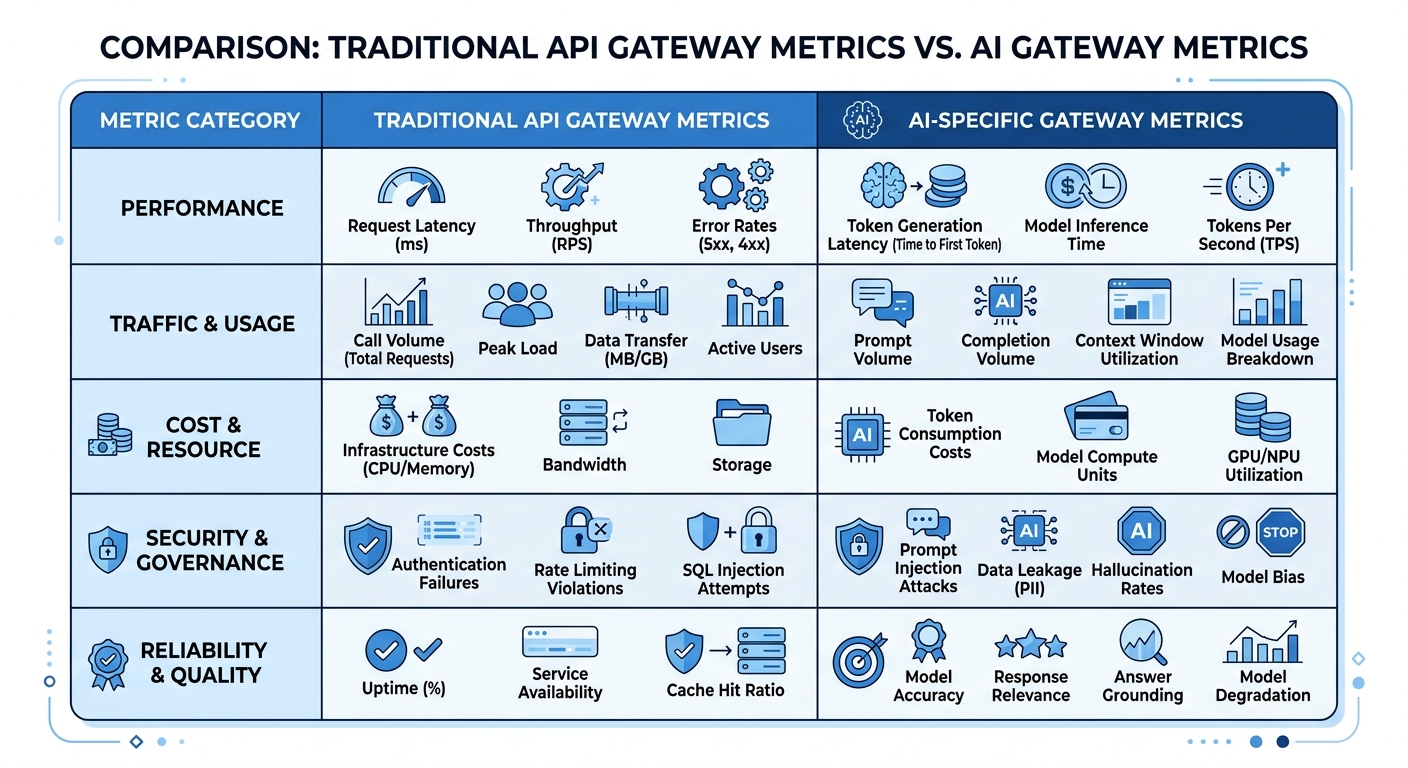
Anthropic billing vs OpenAI billing#
Anthropic and OpenAI both commonly bill API usage by tokens, but developers should compare more than headline price.
| Area | Anthropic Claude API | OpenAI API | What to compare |
|---|---|---|---|
| Input pricing | Model-dependent | Model-dependent | Long context and RAG costs |
| Output pricing | Model-dependent | Model-dependent | Report/code generation costs |
| Caching | Useful for repeated context | Varies by model/API feature | Repeated system prompts and documents |
| Model strengths | Long context, writing, coding, reasoning | Broad ecosystem, multimodal, tooling | Task-level quality per dollar |
| Cost control | Requires instrumentation | Requires instrumentation | Usage by route, user, and feature |
The best choice is rarely “always Claude” or “always OpenAI.” The best setup is usually task-aware routing:
- use a strong Claude model for hard writing/coding/reasoning,
- use a cheaper model for classification or formatting,
- use a fast model for support triage,
- use fallback routing when one provider is unavailable.
How to estimate Claude API cost before launch#
Use this checklist before production:
- Measure average input tokens per request.
- Measure average output tokens per response.
- Separate user-visible requests from internal agent/tool calls.
- Estimate retry rate under real network conditions.
- Group costs by feature: support bot, coding agent, document analysis, summarization, etc.
- Set max output tokens for each route.
- Test smaller models for simple tasks.
- Track cost per successful task, not just total token spend.
A simple spreadsheet can work at first. But once you use multiple models, providers, and environments, you need centralized tracking.
Practical ways to reduce Anthropic API billing#
1. Route simple tasks to cheaper models#
Not every request needs the strongest Claude model. Classification, rewriting, short extraction, JSON formatting, and FAQ responses can often use smaller or cheaper models.
A common production pattern:
| Task | Recommended routing idea |
|---|---|
| Complex coding/debugging | Strong Claude model |
| Simple support triage | Smaller Claude or alternative fast model |
| JSON extraction | Low-cost structured-output model |
| Summaries | Mid-tier model with length limits |
| Fallback after timeout | Cheaper or faster backup model |
2. Cap output length by product route#
Set different output limits for different routes. A customer support preview does not need the same output budget as a deep code review.
3. Reduce repeated context#
Do not attach the same policy, documentation, or tool descriptions unnecessarily. Use prompt caching where it fits. Summarize old chat history. Retrieve fewer but better document chunks.
4. Log token usage per user and feature#
You need to know which feature creates cost. Track:
- user ID,
- route name,
- model,
- input tokens,
- output tokens,
- retries,
- latency,
- success/failure,
- estimated cost.
5. Use an API gateway for billing visibility#
If your app uses Claude, GPT, Gemini, DeepSeek, and other models, billing becomes fragmented. A gateway can centralize:
- one API key,
- model routing,
- usage logs,
- fallback rules,
- cost comparison,
- provider switching.
Crazyrouter is one option for this workflow. It provides an OpenAI-compatible API gateway so teams can call multiple model families through a single base URL while keeping application code stable.
Human-facing link: try Crazyrouter
API endpoint for code: https://crazyrouter.com/v1
Example: calling Claude through an OpenAI-compatible gateway#
Python:
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ["CRAZYROUTER_API_KEY"],
base_url="https://crazyrouter.com/v1"
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
messages=[
{"role": "system", "content": "You are a concise API billing analyst."},
{"role": "user", "content": "Explain how to reduce Claude API billing for a support bot."}
],
max_tokens=600,
temperature=0.2
)
print(response.choices[0].message.content)
Node.js:
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.CRAZYROUTER_API_KEY,
baseURL: "https://crazyrouter.com/v1"
});
const completion = await client.chat.completions.create({
model: "anthropic/claude-haiku-4.5",
messages: [
{ role: "system", content: "You summarize billing logs for developers." },
{ role: "user", content: "Give me five ways to lower Anthropic API cost." }
],
max_tokens: 400
});
console.log(completion.choices[0].message.content);
The key idea is not that every task must use the same model. The key idea is that your application code can stay stable while your routing and cost strategy evolves.
FAQ#
Does Anthropic charge for input and output tokens?#
Yes. API billing usually counts both the tokens you send and the tokens Claude generates. Exact prices depend on the selected Claude model and Anthropic's current pricing.
Why is my Claude API bill higher than expected?#
Common causes include long system prompts, full conversation history, large RAG context, verbose outputs, agent loops, tool calls, and retries after timeouts.
How do I reduce Claude API cost without hurting quality?#
Route simple tasks to cheaper models, cap output length, retrieve less context, summarize old chat history, use prompt caching for repeated context, and monitor cost per feature.
Is prompt caching useful for Anthropic billing?#
It can be useful when the same context or instructions are reused across many requests. It is less useful for fully unique prompts.
Should I use Claude directly or through an API gateway?#
Use direct Anthropic API access if you only need Claude and want first-party simplicity. Use a gateway if you need multiple providers, centralized billing, fallback routing, or model switching without rewriting application code.
Final recommendation#
Anthropic API billing is manageable when you treat it as an engineering metric, not an afterthought. Measure input and output tokens, control retries, route by task type, and optimize cost per successful workflow.
For teams using multiple AI models, the biggest savings usually come from routing: strong models for hard tasks, cheaper models for routine tasks, and centralized logs for every request.
Start with the official Anthropic pricing page for exact model prices, then build your own usage model around your real product traffic.
And if you want to compare Claude, GPT, Gemini, DeepSeek, and other models behind one OpenAI-compatible API, you can test that workflow with Crazyrouter.





