Designing a Codex-Style World Cup 2026 Predictor Workflow with Crazyrouter
A practical Codex-style workflow demo: deterministic World Cup 2026 predictions, validation tests, JSON schema checks, charts, and real Crazyrouter API model routing.
Designing a Codex-Style World Cup 2026 Predictor Workflow with Crazyrouter#
Codex-style coding agents are most useful when they do more than generate code once. For this experiment, I designed a Codex-style workflow that turns a World Cup 2026 prediction prototype into a reproducible engineering demo: deterministic match probabilities, fixture checks, JSON schema validation, charts, raw API audit files, and a real Crazyrouter multi-model test.
Important context: this is a developer workflow demo, not an official World Cup data product and not betting advice. The fixture and rating data used here is a small demo dataset created for reproducible testing. A production sports model would need official live fixtures, lineups, injuries, travel, odds, and continuous result updates.
The live API layer was tested through:
Base URL: https://cn.crazyrouter.com/v1
Date: 2026-06-14 UTC
Endpoints tested:
- GET /v1/models
- POST /v1/chat/completions
Why this should be a Codex-style workflow, not just a prediction prompt#
The weak version of this idea is simple: ask an AI model who will win a match and publish the answer.
The better version is more engineering-heavy:
- keep fixture data in files;
- calculate probabilities with deterministic Python;
- ask models only to explain structured outputs;
- validate JSON;
- preserve raw responses;
- render charts;
- run tests before trusting the result.
That is where a Codex-style workflow becomes interesting. The value is not that an AI can guess sports outcomes. The value is that a coding agent can help turn a rough demo into a workflow with gates.
Claude Code built the prototype. Codex-style workflow hardens it.#
The earlier Claude Code-style version focused on building the first working predictor: fixture data, Elo/Poisson probabilities, charts, and Crazyrouter API calls.
For the Codex-style version, the angle is different:
- add fixture integrity checks;
- add probability normalization checks;
- add JSON schema validation;
- make raw model outputs auditable;
- separate deterministic calculation from model-written explanations;
- treat malformed output as a workflow failure even when HTTP status is 200.
In short: Claude Code is a good builder story. Codex is a good reviewer-builder story.
The prediction model: deterministic first#
The predictor uses a deliberately transparent model:
- Elo-style seed ratings for the demo dataset;
- host boost for relevant host-nation fixtures;
- expected-goals transform;
- Poisson scoreline distribution;
- top score probabilities.
The expected-goals function is intentionally simple:
def expected_goals(rating_for, rating_against, host_boost=0):
diff = (rating_for + host_boost) - rating_against
return max(0.45, min(2.65, 1.28 + diff / 520))
This is not a production sports model. For this article, transparency is more important than pretending to have secret predictive power.
Sample demo predictions#
| Date | Match | Group | xG | Home / Draw / Away | Pick |
|---|---|---|---|---|---|
| 2026-06-11 | Mexico vs South Africa | A | 1.68-0.98 | 55.8% / 24.2% / 19.9% | Mexico |
| 2026-06-11 | South Korea vs Czechia | A | 1.35-1.21 | 40.1% / 26.6% / 33.3% | South Korea |
| 2026-06-12 | USA vs Paraguay | D | 1.53-1.14 | 48.2% / 25.5% / 26.3% | USA |
| 2026-06-13 | Brazil vs Morocco | C | 1.64-0.92 | 54.9% / 24.7% / 20.4% | Brazil |
| 2026-06-13 | Qatar vs Canada | B | 1.1-1.57 | 24.6% / 25.2% / 50.2% | Canada |
| 2026-06-14 | Germany vs Curaçao | E | 2.08-0.48 | 75.1% / 17.7% / 7.2% | Germany |
| 2026-06-14 | Netherlands vs Japan | F | 1.53-1.03 | 49.5% / 25.7% / 24.8% | Netherlands |
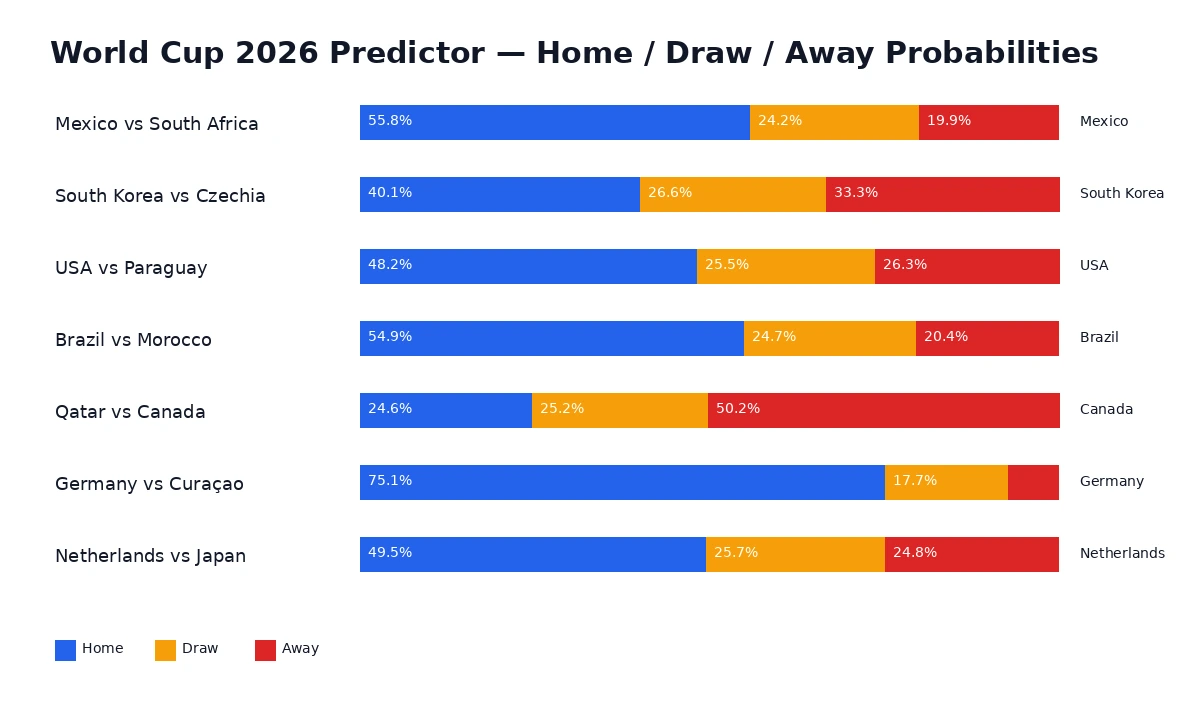
The USA vs Paraguay prediction is a good example. The model gives USA an edge, but not a dominant one: 48.2% home win, 25.5% draw, 26.3% away win. A good workflow should preserve that uncertainty instead of turning it into overconfident prose.
Validation gates#
The demo includes these checks:
Fixture integrity:
- every fixture has id, date, group, home, away, venue
- no duplicate fixture IDs
- every team exists in the rating table
Prediction math:
- home + draw + away probability sums to 1.0 ± 0.002
- expected goals stay within configured bounds
- top score probabilities are sorted descending
- every prediction includes a no-betting-advice disclaimer
LLM output validation:
- response must parse as JSON
- required top-level keys must exist
- match must be an object with date, group, home, away, venue
- probability_summary must include home_win, draw, away_win
This is the main workflow lesson: generated content should pass gates before it becomes product output.
Crazyrouter real API test#
After generating probabilities, the workflow asked several model routes to produce a compact JSON match preview for USA vs Paraguay.
Task:
Return ONLY compact valid JSON. No markdown. No prose.
The top-level object MUST have exactly these keys:
match, predicted_edge, probability_summary, key_factors, uncertainty, disclaimer.
The match value MUST be an object, not a string, with exactly these keys:
date, group, home, away, venue.
The probability_summary value MUST include numeric keys:
home_win, draw, away_win.
The disclaimer MUST include the phrase: not betting advice.
The model-list endpoint worked:
GET /v1/models
HTTP status: 200
Latency: 449 ms
Models returned: 261
API results:
| Model | HTTP | Latency | Total tokens | Valid JSON | Schema valid |
|---|---|---|---|---|---|
gpt-4o-mini | 200 | 2487 ms | 514 | True | True |
gpt-5.5 | 200 | 4664 ms | 859 | True | True |
gemini-2.5-flash | 200 | 2631 ms | 837 | False | False |
qwen-plus | 200 | 5045 ms | 696 | True | True |
deepseek-chat | 200 | 4192 ms | 738 | True | True |
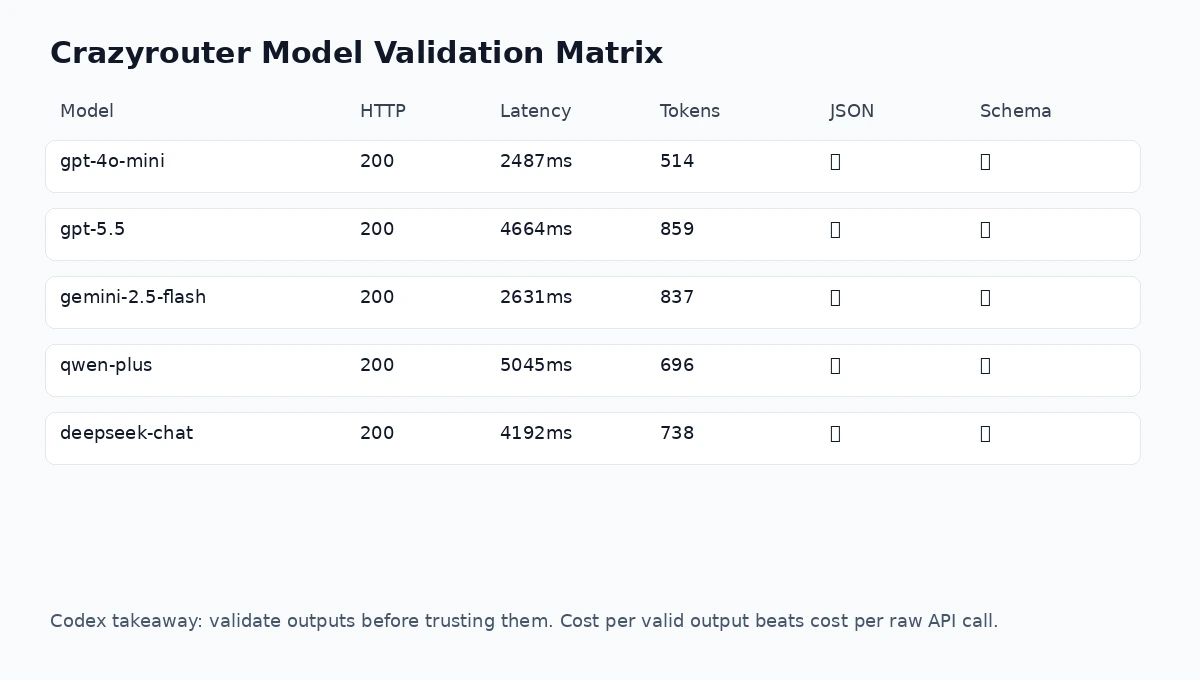
The useful failure: one route still broke the workflow#
With a stricter prompt, 4 out of 5 model routes returned schema-valid JSON. That is exactly what we want from a validation experiment: most routes passed, and one route still exposed a failure case.
In this run:
gpt-4o-mini,gpt-5.5,qwen-plus, anddeepseek-chatreturned schema-valid JSON.gemini-2.5-flashreturned truncated JSON in this specific test.
This is not a reason to reject any model globally. It is a reason to build retries, stricter prompts, schema repair, and fallback routes.
A plain JSON parser asks:
Is this syntactically valid JSON?
A workflow validator asks:
Can the application safely use this object?
Those are different questions.
Why Crazyrouter fits this workflow#
A coding-agent workflow should not be tied to one model route. The same task may need:
- a cheap baseline model;
- a premium model for harder formatting;
- a fast model for drafts;
- a fallback model when JSON breaks;
- a non-US model route for comparison.
Crazyrouter makes that operationally simple because the client shape stays OpenAI-compatible:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_CRAZYROUTER_API_KEY",
base_url="https://cn.crazyrouter.com/v1",
)
The useful metric is not raw request price. It is cost per valid output.
If a cheap route often returns malformed or schema-invalid content, the workflow may spend more on retries than expected. If a premium route returns usable structured output more consistently, it may be cheaper per successful task.
Minimal reproduction structure#
generated/worldcup_predictor_codex_20260613/
├── build_codex_worldcup_predictor.py
├── fixtures.json
├── team_ratings_seed.json
├── predictions.json
├── schema_match_preview.json
├── crazyrouter_test_results.json
├── crazyrouter_raw_<model>.json
├── tests/
│ ├── test_fixture_integrity.py
│ ├── test_prediction_math.py
│ └── test_prediction_schema.py
└── charts/
├── codex-world-cup-2026-match-predictor-crazyrouter-cover.webp
├── codex-world-cup-2026-match-predictor-crazyrouter-01.webp
└── codex-world-cup-2026-match-predictor-crazyrouter-02.webp
Run commands:
python build_codex_worldcup_predictor.py predict
python build_codex_worldcup_predictor.py test
python build_codex_worldcup_predictor.py api-test
python build_codex_worldcup_predictor.py render-charts
Takeaways#
- Coding agents should not just generate code. They should leave behind tests.
- LLMs should explain deterministic probabilities, not invent them.
- HTTP 200 is not workflow success.
- JSON parsing is not enough; schema validation matters.
- The best production metric is cost per valid output, not cost per raw API call.
- API gateways are useful because model routing becomes an engineering choice, not a rewrite.
That is the real lesson from a World Cup predictor demo: the prediction is the hook, but the workflow is the product.





