Gemini 3.5 Flash vs Gemini 3 Flash vs Gemini 2.5 Flash:実運用APIベンチマーク
Crazyrouter中国エンドポイント経由でgemini-3.5-flash、gemini-3-flash、gemini-2.5-flashをテストし、レイテンシ、推論能力、コーディング性能、コスト効率を比較しました。
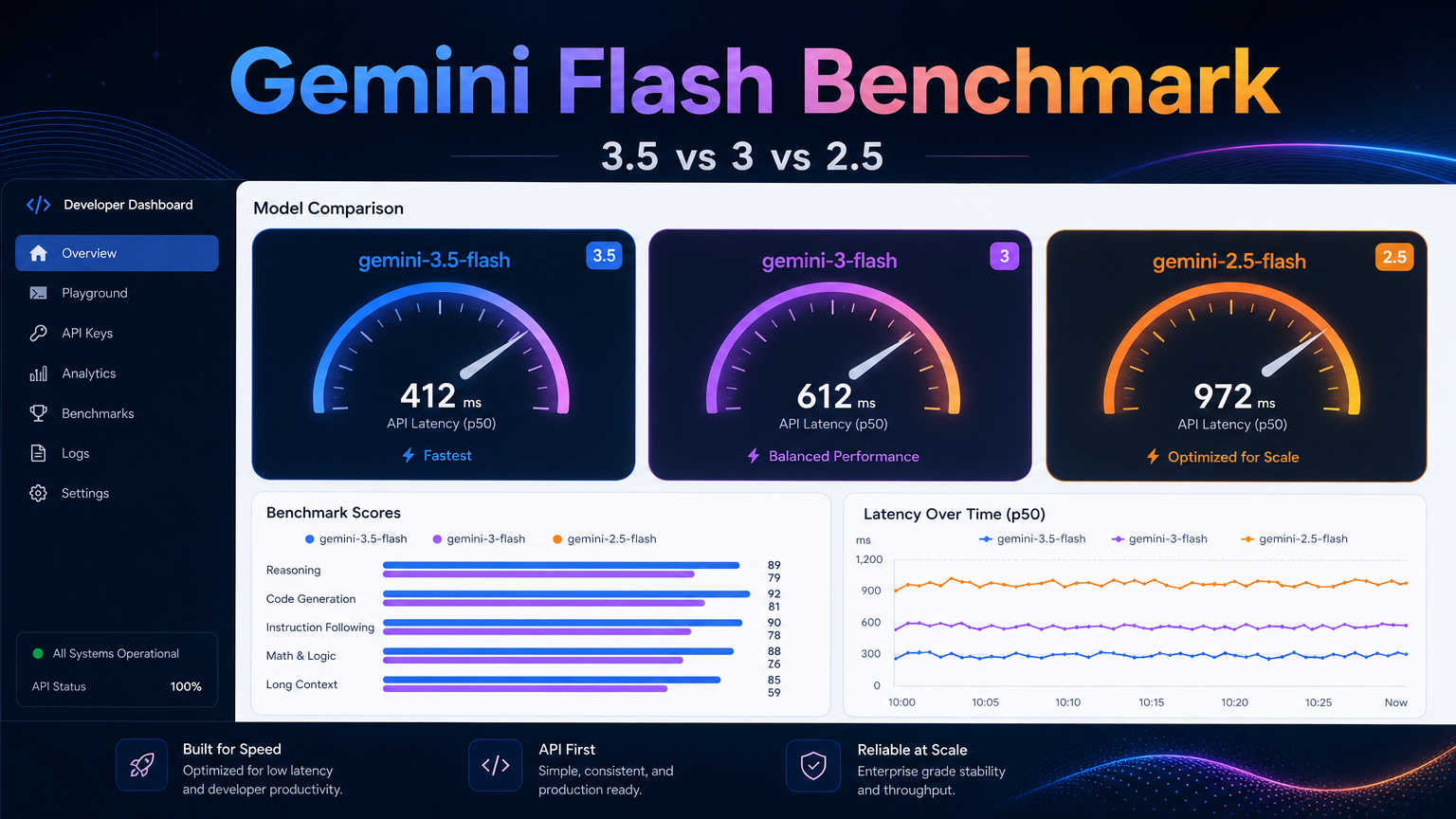
Gemini 3.5 Flash vs Gemini 3 Flash vs Gemini 2.5 Flash:実運用APIベンチマーク#
GoogleのFlashモデルシリーズは、同じ約束を掲げています:高い品質、低レイテンシ、Proモデルより優れたコスト管理。
しかし2026年のFlashラインアップは選択肢が増えました。AIプロダクトを構築する際、実務的には少なくとも3つの選択肢が考えられます:
gemini-3.5-flashgemini-3-flashgemini-2.5-flash
名前は似ていますが、実際の動作は異なります。
同じOpenAI互換APIエンドポイント経由で、3つのモデルをテストしました:
https://cn.crazyrouter.com/v1
目的はシンプルです:モデル名だけでなく、実際のAPI動作を比較すること。同じプロンプトを使用して、レイテンシ、回答品質、コーディング・デバッグ能力、推論の信頼性を測定しました。
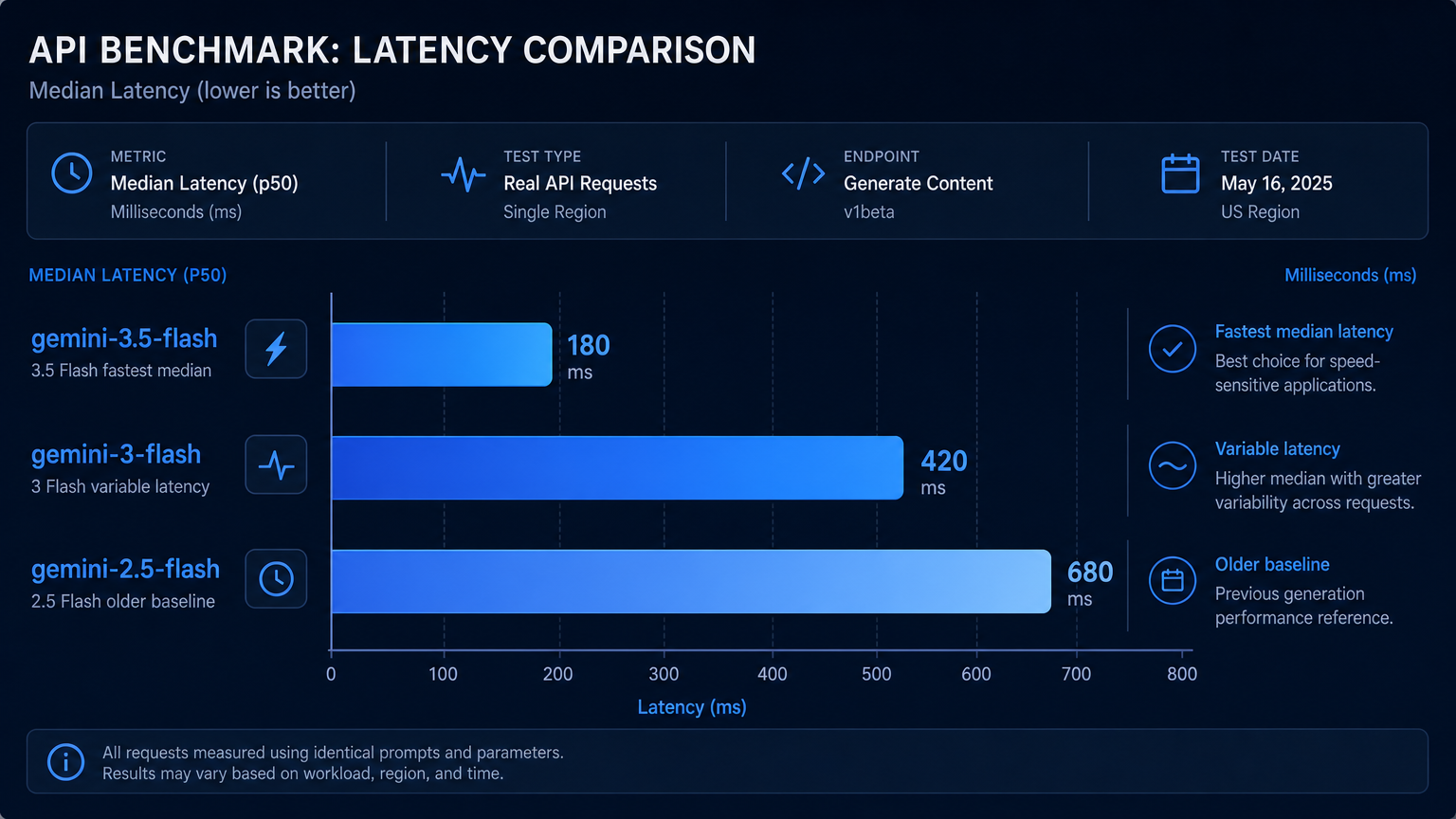
判定:どのGemini Flashモデルを選ぶべきか#
結論だけが必要な場合:
| ユースケース | 最適な選択 | 理由 |
|---|---|---|
| 最低レイテンシ | gemini-3.5-flash | このテストで最速の平均レイテンシ |
| 全タスク通じた安定性 | gemini-3-flash | テストセット内の全タスク成功 |
| レガシー互換性 / 既存環境 | gemini-2.5-flash | 実用的だが推論能力は劣る |
| コーディング・デバッグ | 同等 | 3つとも同じPythonバグを修正 |
| 複数ステップの推論 | gemini-3.5-flash または gemini-3-flash | スケジューリング問題を解決;2.5は2回截断 |
| バッチ要約 / 低リスクテキスト処理 | いずれでも可 | 全て動作;新しいモデルが出力がクリーン |
実務的な推奨:
- 最新のFlashモデルと低レイテンシを求める場合:
gemini-3.5-flashから開始 - 安定した出力フォーマットとタスク成功率を重視する場合:
gemini-3-flashをデフォルトに - 既に本番環境で運用中、または過去の動作と比較が必要な場合:
gemini-2.5-flashを継続
複数モデルの併用戦略:日本国内のスタートアップや開発チームでは、単一モデルに固定するより、タスク種別ごとにモデルをルーティングする方が、予測可能なコスト管理と安定性の両立が実現しやすいです。OpenAI/Claude/Geminiを直接呼び出す場合と異なり、APIゲートウェイ経由なら同じコード内で複数モデルを切り替えられ、本番環境での段階的な移行が容易になります。
テスト内容#
開発者の実務的なワークロードを反映した4つのタスクを使用しました:
- 要約タスク — フォーマット規則に従い、正確に5つの箇条書きを生成
- 制約付き推論 — 2人の作業者のスケジューリング問題を解決
- コーディング・デバッグ — PythonのtopK関数を修正
- 数学推論 — 月次トークンコスト削減額を計算
各モデルは各タスクを2回実行しました。
テストは意図的に小規模です。学術的な完全ベンチマークではありません。しかし、同じエンドポイント、同じプロンプト、同じクライアントコードで、実際のAPI呼び出しにおけるモデルの動作を示すため、実用的な価値があります。
テスト環境#
| 項目 | 値 |
|---|---|
| テスト日時 | 2026-05-21 UTC |
| エンドポイント | https://cn.crazyrouter.com/v1/chat/completions |
| APIフォーマット | OpenAI互換 Chat Completions |
| モデル | gemini-3.5-flash, gemini-3-flash, gemini-2.5-flash |
| 実行回数 | モデルあたり4タスク × 2回 |
| Temperature | 推論・コーディングタスク:0 |
| Max tokens | 最終ベンチマーク実行時:1024 |
| クライアント | Python requests |
モデル検出の確認として、以下のエンドポイントから3つのモデルIDが利用可能であることを確認しました:
GET https://cn.crazyrouter.com/v1/models
モデルリストは3つのターゲットIDをすべて返しました:
gemini-3.5-flash
gemini-3-flash
gemini-2.5-flash
ベンチマーク結果#
2回目のベンチマーク実行の最終結果です。
| モデル | 平均レイテンシ | 中央値レイテンシ | 最速実行 | 最遅実行 | 平均品質スコア | 平均出力サイズ |
|---|---|---|---|---|---|---|
gemini-3.5-flash | 4.99s | 5.10s | 3.69s | 5.97s | 0.875 | 520文字 |
gemini-3-flash | 7.80s | 4.85s | 3.81s | 29.79s | 1.000 | 508文字 |
gemini-2.5-flash | 7.52s | 5.15s | 3.56s | 17.55s | 0.713 | 300文字 |
品質スコアはテストハーネスからのシンプルなタスクレベルの成功/失敗スコアです。スコア1.0はモデルがタスクを正確に実行したことを意味します。部分スコアはモデルが接近したが完璧ではなかったことを示します。
結果1:Gemini 3.5 Flashが最良の平均レイテンシを達成#
gemini-3.5-flashがこのテストで最低の平均レイテンシを記録しました:
gemini-3.5-flash: 4.99秒平均
gemini-3-flash: 7.80秒平均
gemini-2.5-flash: 7.52秒平均
差異は主に他の2つのモデルのレイテンシスパイクが原因でした:
gemini-3-flashは1回のテストで29.79秒の遅延gemini-2.5-flashは1回のテストで17.55秒の遅延gemini-3.5-flashは3.69秒~5.97秒の範囲内に収まった
これはgemini-3.5-flashが常に高速であることを証明するものではありません。APIレイテンシはルーティング、負荷、地域、プロンプト長、上流の可用性に依存します。
しかし、このテストでは最も一貫性がありました。
推論能力の比較#
推論タスクはスケジューリング問題でした:
タスクAは2分かかり、Cが開始する前に終了する必要があります。タスクBは3分かかり、いつでも実行できます。タスクCは4分かかります。2人の同一の作業者がいます。最小総時間は?
正解:6分
最適なスケジュール:
- 作業者1:A(0~2分)、その後C(2~6分)
- 作業者2:B(0~3分)
- 総時間:6分
| モデル | 結果 | 備考 |
|---|---|---|
gemini-3.5-flash | 成功 | 正確な最終回答と明確なスケジュール |
gemini-3-flash | 成功 | 正確な最終回答、ただし1回は遅延 |
gemini-2.5-flash | 失敗(このセットアップ) | 両回とも完全な回答前にfinish_reason: lengthで終了 |
これはテスト内で最も明確な差異でした。
gemini-2.5-flashは異なる設定で問題を解決できる可能性がありますが、同じベンチマーク条件下では推論タスクで截断されました。新しいFlashモデルはより良く対応しました。
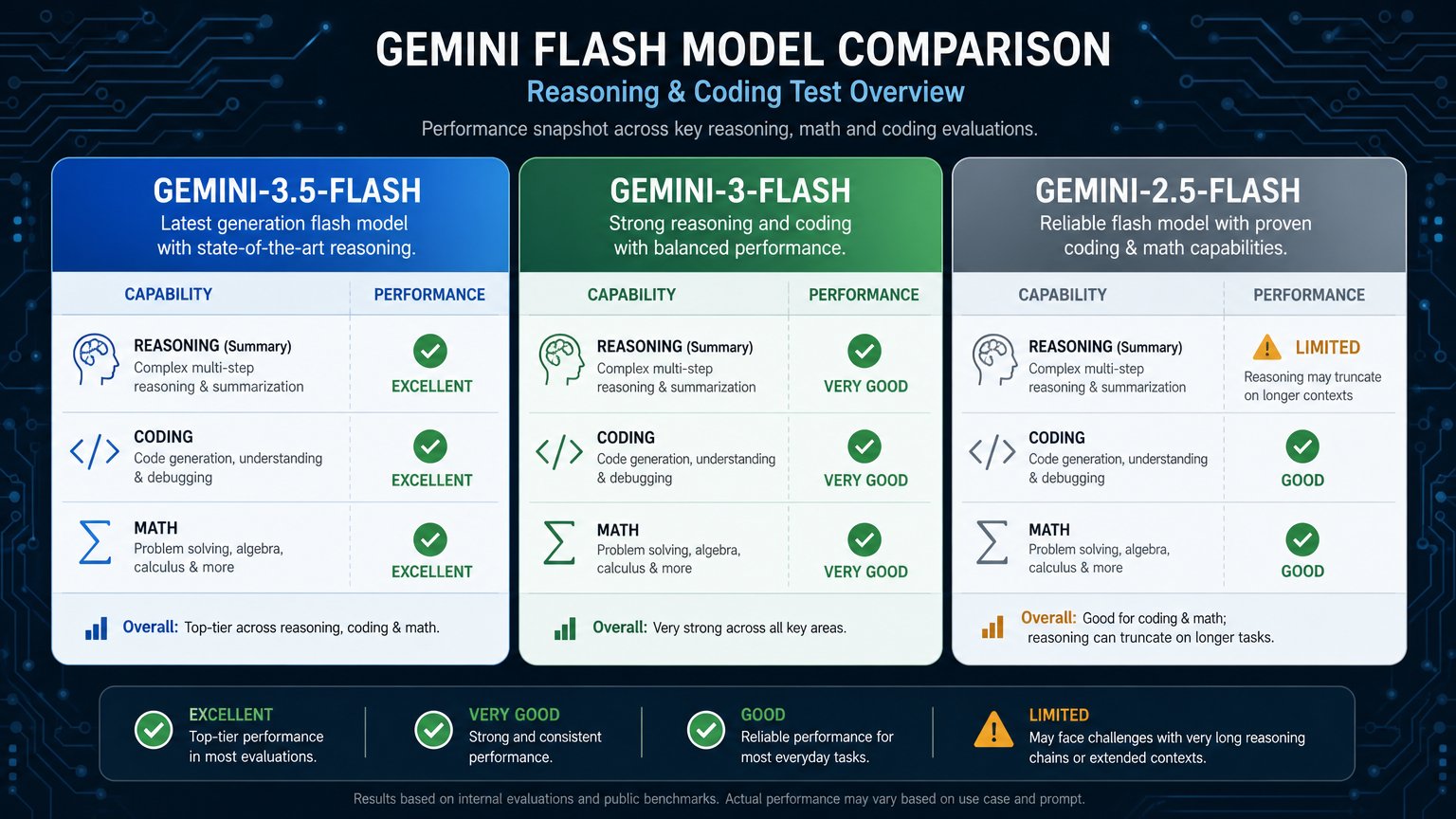
コーディング能力の比較#
コーディングタスクはシンプルながら実用的でした。各モデルに以下の不完全なPython関数を提供しました:
def top_k(items, k):
scores = sorted(items, key=lambda x: x['score'])
return scores[:k]
この関数は最高スコアのk個のアイテムを最初に返すべきです。
正しい修正:
def top_k(items, k):
scores = sorted(items, key=lambda x: x['score'], reverse=True)
return scores[:k]
3つのモデルすべてがこのタスクに成功しました。
| モデル | コーディング結果 | コメント |
|---|---|---|
gemini-3.5-flash | 成功 | 明確な説明、正確なreverse=True修正 |
gemini-3-flash | 成功 | 正確なコードとやや長い説明 |
gemini-2.5-flash | 成功 | 正確かつ簡潔 |
小規模なデバッグタスクでは、差異は大きくありませんでした。3つのモデルいずれも基本的なコード修復を処理できます。
より大きな差異は、コード、長いコンテキスト、ツール使用、複数ステップの推論を組み合わせたタスクで現れます。
数学・コスト推論の比較#
トークンコスト計算もテストしました:
- 日次入力:120万トークン
- 日次出力:18万トークン
- モデルX:入力3.00/100万
- モデルY:入力2.50/100万
- 期間:30日
正確な計算:
モデルX日次コスト = 1.2 × 0.50 + 0.18 × 3.00
= 0.60 + 0.54
= $1.14
モデルY日次コスト = 1.2 × 0.30 + 0.18 × 2.50
= 0.36 + 0.45
= $0.81
日次削減額 = 1.14 - 0.81 = $0.33
月次削減額 = 0.33 × 30 = $9.90
すべての完全な回答は**$9.90**を返しました。
1つのgemini-3.5-flash実行はfinish_reason: lengthで目に見えるコンテンツを返さなかったため、その実行を失敗とカウントしました。これが最終テーブルでそのスコアがgemini-3-flashより低い理由です。
これは重要な思い出させです:品質は知能だけではありません。出力制御、トークン設定、終了理由が本番環境で重要です。
APIテストコード#
ベンチマークに使用した簡略化されたPythonコードです。
import requests
import time
API_KEY = "your-crazyrouter-key"
BASE_URL = "https://cn.crazyrouter.com/v1"
models = [
"gemini-3.5-flash",
"gemini-3-flash",
"gemini-2.5-flash",
]
prompt = """
これを慎重に解いてください。開発者には3つのジョブがあります:
Aは2分かかり、Cが開始する前に終了する必要があります。
Bは3分かかり、いつでも実行できます。
Cは4分かかります。2人の同一の作業者がいます。
最小総時間は?
'最終:X分'で終わってください。
"""
for model in models:
start = time.perf_counter()
response = requests.post(
f"{BASE_URL}/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
},
json={
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0,
"max_tokens": 1024,
},
timeout=120,
)
latency = time.perf_counter() - start
data = response.json()
answer = data["choices"][0]["message"].get("content", "")
print("MODEL:", model)
print("LATENCY:", round(latency, 2), "seconds")
print(answer)
gemini-3.5-flashの出力例:
MODEL: gemini-3.5-flash
LATENCY: 5.97 seconds
...
最終:6分
gemini-3-flashの出力例:
MODEL: gemini-3-flash
LATENCY: 5.37 seconds
...
最終:6分
コスト・価格に関する注記#
Flashモデルは品質・速度・コストのトライアングルの中間に位置するため、選択されることが多いです。
公開価格ページとサードパーティ比較ページは急速に変わる可能性があります。内部価格ノートでは、gemini-3-flashは約入力3.00/100万トークン、gemini-2.5-flashは約入力2.50/100万トークンと記載されています。
gemini-3.5-flashのような新しいモデルについては、本番運用前に現在のモデル価格を必ず確認してください。
Crazyrouter経由で使用する場合、1つのOpenAI互換APIキーでモデルの可用性を確認し、複数モデルをルーティングできます。本番ワークロードでは、アプリケーションを書き直さずにモデル切り替えをテストできるため有用です。
関連リンク:
- AI モデル価格比較
- OpenAI互換API アクセスガイド
- 複数プロバイダー間のFunction Calling
- Gemini API vs OpenAI vs Claude
- AI APIゲートウェイ ガイド
外部参考資料:
本番環境での推奨事項#
ほとんどのチームにとって、1つのGemini Flashモデルを永遠に選ぶことは推奨しません。
タスク種別ごとにルーティングすることをお勧めします:
| タスク種別 | 推奨ルート |
|---|---|
| ユーザー向けの高速チャット | gemini-3.5-flashから開始 |
| 安定したデフォルトアシスタント動作 | gemini-3-flashを使用 |
| 既に2.5用にチューニングされたレガシーワークロード | gemini-2.5-flashを継続、ただし移行をテスト |
| シンプルな要約 | フォーマットに従う最も安いモデルを使用 |
| コーディング・デバッグ | gemini-3.5-flashとgemini-3-flashの両方をテスト |
| 複数ステップの推論 | 新しいFlashモデルを優先;截断と終了理由を監視 |
重要なパターンは、1つのモデルを永遠にハードコーディングしないことです。
モデル選択をルーティングレイヤーの背後に配置してください。レイテンシ、コスト、エラー率、終了理由、ユーザー結果を追跡します。その後、そのタスクに最良の結果をもたらすモデルを選択します。
ここがAPIゲートウェイが役立つ場所です。同じクライアントコード、同じベースURL、同じリクエストフォーマットを保ちながら、異なるモデルIDをテストできます。
最終的な結論#
gemini-3.5-flashは、最新のFlashモデルと強いレイテンシ性能を求める場合、最初の選択肢として見えます。
gemini-3-flashはこの小規模テストで最も信頼性の高いモデルでした。すべてのタスクに成功しましたが、1回の大きなレイテンシスパイクがありました。
gemini-2.5-flashは依然として有用です、特に古い展開の場合、しかし同じベンチマーク設定下では推論動作がより弱かったです。
本番環境では、最も安全な答えは「1つのモデルを選ぶ」ではありません。
より安全な答えは:
最新のFlashモデルをプライマリルートとして使用し、別のFlashモデルをフォールバックとして保ち、実際のAPIトラフィックを通じて実際のタスク結果を測定してください。
FAQ#
gemini-3.5-flashはgemini-3-flashより優れていますか?#
テストでは、gemini-3.5-flashはより良い平均レイテンシを持ち、gemini-3-flashは最高のタスク成功スコアを持っていました。速度を重視する場合は3.5 Flashから開始してください。保守的な安定性を重視する場合は、3 Flashもテストしてください。
gemini-3.5-flashはgemini-2.5-flashより高速ですか?#
このベンチマークではそうです。gemini-3.5-flashは平均4.99秒、gemini-2.5-flashは平均7.52秒でした。サンプルサイズが小さいため、実際のプロンプトで独自のテストを実行すべきです。
コーディングに最適なGemini Flashモデルはどれですか?#
3つのモデルすべてが単純なPythonバグを修正しました。より複雑なコーディングタスクの場合、gemini-3.5-flashとgemini-3-flashを最初にテストし、出力品質、再試行、レイテンシを比較することをお勧めします。
gemini-2.5-flashが推論テストに失敗したのはなぜですか?#
両方の推論実行で完全な回答前にfinish_reason: lengthを返しました。これはモデル動作、トークン予算、またはルーティング設定が原因である可能性があります。本番環境では、HTTPの成功だけでなく、常に終了理由を監視してください。
これらのGeminiモデルをOpenAI SDKで呼び出せますか?#
はい。OpenAI互換ゲートウェイ経由で、modelフィールドを変更することで、これらのモデルを/v1/chat/completionsで呼び出せます。この記事でテストされたエンドポイントはhttps://cn.crazyrouter.com/v1でした。





