"Claude Plans, Codex Reviews: Rebuilding the Viral Two-Agent Coding Workflow with Crazyrouter"
"Twitter is full of Codex-in-Claude-Code workflows. We rebuilt the useful part: one agent plans or implements, a second agent reviews adversarially, and the whole process becomes reproducible packets instead of copy-paste chaos."

Claude Plans, Codex Reviews: Rebuilding the Viral Two-Agent Coding Workflow with Crazyrouter#
Over the last few weeks, a recurring AI coding pattern has been showing up on Twitter/X:
Let one coding agent plan or implement, then let another agent review, challenge, or rescue the work before commit.
Some posts describe Codex running inside Claude Code. Others talk about dynamic workflows, adversarial review, or task handoff between agents. The exact product integration matters, but the underlying workflow is more important:
- one agent creates a plan or patch;
- another agent reviews it from a different perspective;
- the developer keeps the final decision;
- the workflow saves evidence instead of relying on vibes.
This article rebuilds that pattern as a reproducible workflow you can use with an OpenAI-compatible API gateway like Crazyrouter.
Why this workflow matters#
Single-agent coding is convenient, but it has a failure mode: the same model that wrote the plan often reviews its own assumptions too gently.
A second reviewer model can catch:
- missing edge cases;
- unsafe refactors;
- unclear rollback paths;
- tests that were claimed but not actually run;
- hidden product assumptions;
- over-complicated patches.
The goal is not to create autonomous chaos. The goal is to make review cheaper and more systematic.
The reproduced workflow#
Instead of depending on a specific plugin, we turned the idea into four packets:
| Packet | Role | Output |
|---|---|---|
01-planner | Convert request into scope, risks, acceptance criteria | plan.md |
02-implementer | Apply the smallest safe patch | code / artifact notes |
03-reviewer | Adversarial review from another model/agent perspective | review_checklist.md |
04-verifier | Run tests or direct inspections | evidence + go/no-go |
This is the core idea behind the local tool we created:
python tools/agent_workflows/agent_packetizer.py \
--title "Codex inside Claude Code two agent review" \
--task "Reproduce a workflow where one AI coding agent implements and a second agent performs adversarial review before commit." \
--out generated/codex_claude_workflow_20260603/agent_packet_demo
It creates:
agent_packet_demo/
├── plan.md
├── packets/
│ ├── 01-planner.md
│ ├── 02-implementer.md
│ ├── 03-reviewer.md
│ └── 04-verifier.md
├── review_checklist.md
└── content_angle.md
OpenAI-compatible API setup#
If model behavior is part of the experiment, keep the client code stable and switch only the model ID.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_CRAZYROUTER_API_KEY",
base_url="https://cn.crazyrouter.com/v1"
)
planner = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Create a minimal implementation plan for this feature..."}],
temperature=0
)
reviewer = client.chat.completions.create(
model="claude-opus-4-8",
messages=[{"role": "user", "content": "Review this plan adversarially. Find risks, missing tests, and rollback issues..."}],
temperature=0
)
Do not add UTM parameters to API base URLs. This is correct:
https://cn.crazyrouter.com/v1
This is wrong:
https://cn.crazyrouter.com/v1?utm_source=twitter
A practical two-agent policy#
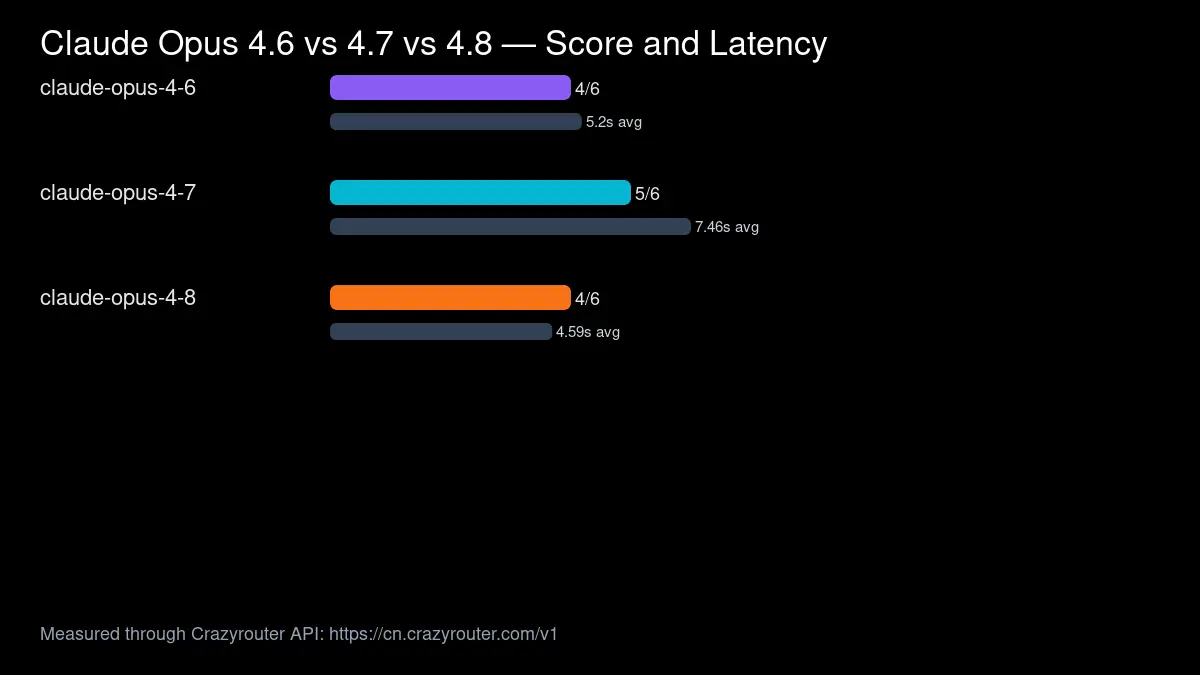
Based on our recent Crazyrouter model tests, a reasonable starting policy is:
| Workflow step | Suggested model pattern | Why |
|---|---|---|
| Planning | stronger reasoning model | catches scope and acceptance criteria |
| Implementation | coding-optimized model | focuses on patch generation |
| Adversarial review | different model from implementer | reduces self-confirmation |
| Verification summary | fast/cheap model if tests already ran | summarizes evidence, does not invent it |
The key is not the exact model name. The key is role separation.
The reviewer prompt template#
Here is a simple reviewer prompt we use as a starting point:
You are the adversarial reviewer for an AI-generated coding plan or patch.
Review for:
1. correctness;
2. security and privacy risks;
3. hidden assumptions;
4. missing tests;
5. rollback path;
6. over-engineering;
7. files that should not be touched.
Return:
- Verdict: approve / request changes / block
- Top risks
- Required fixes
- Verification commands
- Questions for the human owner
Do not rewrite the whole solution unless necessary.
What to log#
If you want this workflow to improve over time, log the trajectory:
| Field | Example |
|---|---|
| task_id | billing-export-2026-06-03 |
| role | planner / implementer / reviewer / verifier |
| model | claude-opus-4-7 |
| latency_sec | 7.46 |
| prompt_tokens | 1200 |
| output_tokens | 600 |
| result | approve / changes / blocked |
| evidence | test command, diff, screenshot, URL |
Without logs, AI coding workflows become anecdotes. With logs, they become operations.

How this becomes content and tooling#
A viral workflow is useful only if it turns into assets. For this case, we created:
- a case library:
growth_ops/twitter_codex_claude_cases.md; - a tool backlog:
growth_ops/skills_tools_backlog.md; - a packetizer script:
tools/agent_workflows/agent_packetizer.py; - a draft skill:
skills/agent-workflow-replicator/SKILL.md; - a reproducible demo folder:
generated/codex_claude_workflow_20260603/agent_packet_demo/.
This is the playbook we will use going forward: find high-signal Twitter/X workflows, reproduce the useful part, then publish the result as an article, demo, skill, or small tool.
Final take#
The best AI coding workflows are not just about using Claude, Codex, Cursor, or any single tool. They are about structure:
- separate planning from implementation;
- separate implementation from review;
- make verification explicit;
- log what happened;
- keep the human in charge.
Crazyrouter helps because you can test multiple models behind one OpenAI-compatible endpoint and route each workflow step to the model that fits best.
Try the API gateway here: Crazyrouter