Same Agent Workflow, Three Model Routes: A Real Crazyrouter Benchmark
We ran the same four-step AI coding workflow through three routing policies: all Claude Opus 4.7, all Claude Opus 4.8, and a mixed 4.7/4.8 route. The result shows why dynamic workflows need model routing and trace logs, not vibes.

Same Agent Workflow, Three Model Routes: A Real Crazyrouter Benchmark#
Dynamic workflows are exciting, but they introduce a practical question: which model should run each step?
If a workflow has a planner, implementer, adversarial reviewer, and verifier, you can route all steps to one strong model. Or you can route different steps to different models.
The wrong answer is to guess.
So we ran a small real benchmark through Crazyrouter.
Test setup#
We used the Crazyrouter OpenAI-compatible endpoint:
https://cn.crazyrouter.com/v1
The workflow task was:
Add a CSV export for account billing history with user-level authorization, timezone-safe timestamps, CSV escaping, tests, and rollback notes.
The workflow had four steps:
- planner
- implementer
- adversarial reviewer
- verifier
We tested three routing policies:
| Policy | Planner | Implementer | Reviewer | Verifier |
|---|---|---|---|---|
| all_opus_47 | claude-opus-4-7 | claude-opus-4-7 | claude-opus-4-7 | claude-opus-4-7 |
| all_opus_48 | claude-opus-4-8 | claude-opus-4-8 | claude-opus-4-8 | claude-opus-4-8 |
| routed_47_48 | claude-opus-4-7 | claude-opus-4-8 | claude-opus-4-7 | claude-opus-4-8 |
Raw benchmark artifact:
generated/dynamic_workflow_routing_20260603/benchmark_results.json
Results#
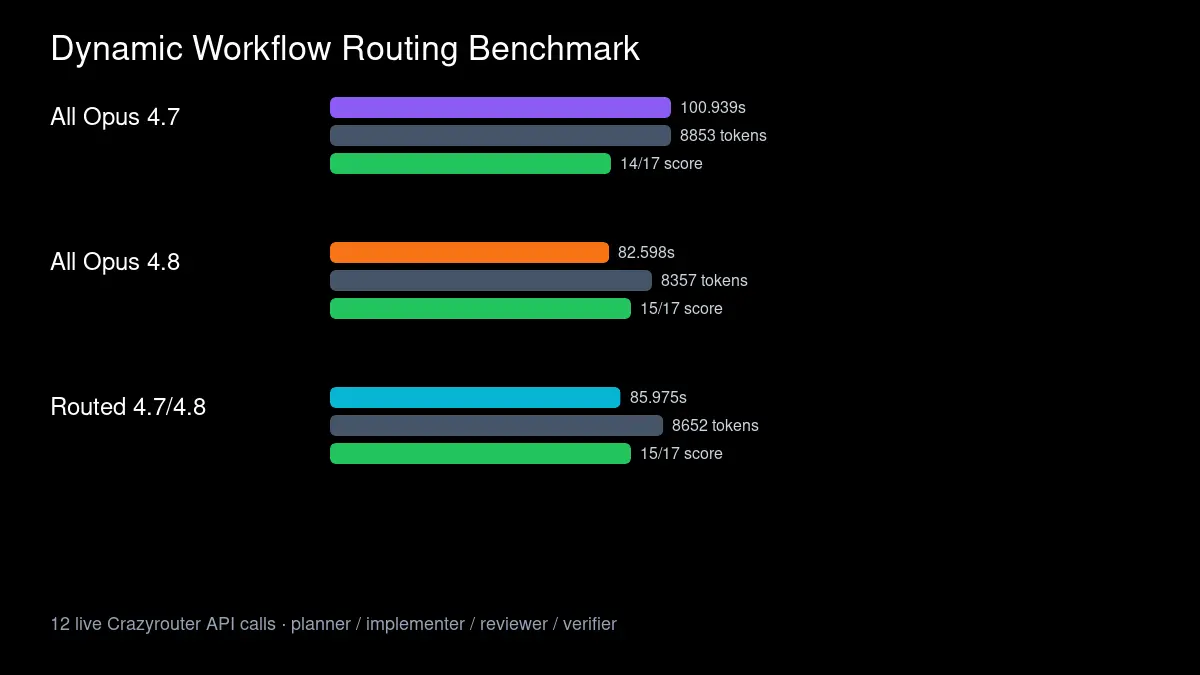
| Route | Calls | Total latency | Total tokens | Output tokens | Score |
|---|---|---|---|---|---|
| all Opus 4.7 | 4 | 100.939s | 8,853 | 5,977 | 14/17 |
| all Opus 4.8 | 4 | 82.598s | 8,357 | 5,782 | 15/17 |
| routed 4.7/4.8 | 4 | 85.975s | 8,652 | 5,873 | 15/17 |
In this run, all_opus_48 won on latency, total tokens, and score.
That does not mean every workflow should use Opus 4.8 everywhere. It means routing needs evidence.
What the score measured#
This was not a generic benchmark. Each workflow step had step-specific checks.
For example:
- planner needed affected files, risks, acceptance criteria, tests, rollback;
- implementer needed CSV handling, authorization, timestamps, tests;
- reviewer needed security, privacy, tests, rollback;
- verifier needed commands, tests, evidence, inspection.
The score was a simple keyword-based quality gate. It is not a perfect human evaluation, but it catches whether the output covered required workflow concerns.
Why this matters#
Dynamic workflows can multiply model calls.
A simple AI coding request might become:
planner call
+ implementer call
+ reviewer call
+ verifier call
+ retry calls
+ patch-fix calls
+ final summary call
If you always use the most expensive model, cost can grow quickly. If you always use the cheapest model, failures and retries can grow quickly.
The useful metric is not token price.
The useful metric is:
cost and latency per successful workflow
What we learned#
1. Opus 4.8 was faster in this workflow#
The all-4.8 route finished in 82.598 seconds. The all-4.7 route took 100.939 seconds.
That is an 18.341 second difference for the same four-step workflow.
In a single call, that may not matter. In a background agent system with many workflow steps, it does.
2. Mixed routing was close, but not better here#
The mixed route used 4.7 for planning/review and 4.8 for implementation/verification.
It scored 15/17, same as all-4.8, but took 85.975 seconds and used 8,652 tokens.
That is still good. But in this run, all-4.8 was simpler and slightly better.
3. A static rule is risky#
A different task might favor a different route. Security review, legal summarization, long-context extraction, frontend implementation, and test generation are not the same workload.
The point is not “always use model X.”
The point is to create a workflow trace and compare model routes on your actual task types.
Minimal reproduction code#
from openai import OpenAI
client = OpenAI(
api_key="YOUR_CRAZYROUTER_API_KEY",
base_url="https://cn.crazyrouter.com/v1"
)
steps = {
"planner": "Create a concise implementation plan with risks, tests, and rollback.",
"implementer": "Write a minimal pseudo-patch plan and code sketch.",
"reviewer": "Adversarially review security, correctness, privacy, tests, and rollback.",
"verifier": "Create a verification checklist with concrete commands and evidence."
}
route = {
"planner": "claude-opus-4-8",
"implementer": "claude-opus-4-8",
"reviewer": "claude-opus-4-8",
"verifier": "claude-opus-4-8"
}
for role, instruction in steps.items():
response = client.chat.completions.create(
model=route[role],
messages=[{"role": "user", "content": instruction}],
temperature=0
)
print(role, response.choices[0].message.content)
Keep the API base URL clean. Do not add UTM parameters to code endpoints.
Recommended workflow routing practice#
Start with this loop:
- define workflow steps;
- define success checks per step;
- run the same task across 2-3 routing policies;
- log model, latency, tokens, and score;
- choose the route based on successful workflow outcome, not model hype.
A gateway makes this practical because the application code can keep the same client and base URL while changing model IDs.
Why Crazyrouter fits this pattern#
Dynamic workflows need three things:
- model variety;
- centralized routing;
- traceable usage.
Crazyrouter gives one OpenAI-compatible API surface for multiple models. That makes it easier to test planner/reviewer/verifier routes without rewriting the product around each provider.
This matters more as AI coding moves from single-agent chats to orchestrated workflows.
Final take#
Dynamic workflows are not just a Claude Code or Codex feature. They are an engineering pattern.
Once you split work into planner, implementer, reviewer, and verifier, model choice becomes a routing problem.
In this run, all Opus 4.8 was the best route. In your workflow, it might be a mixed route. The only way to know is to measure.
Try model routing here: Crazyrouter

