Claude Jupiter v1-p vs GPT-5.5 Benchmark: Real API Test on Reasoning and Coding
We tested claude-jupiter-v1-p and gpt-5.5 through https://cn.crazyrouter.com/v1 across reasoning, coding, patching, JSON, long-context recall, agent planning, and math tasks. GPT-5.5 scored slightly higher, while Jupiter was much faster but required a payload compatibility fix.

title: Claude Jupiter v1-p vs GPT-5.5 Benchmark: Real API Test on Reasoning and Coding slug: jupiter-vs-gpt55-benchmark-2026 summary: We tested claude-jupiter-v1-p and gpt-5.5 through https://cn.crazyrouter.com/v1 across reasoning, coding, patching, JSON, long-context recall, agent planning, and math tasks. GPT-5.5 scored slightly higher, while Jupiter was much faster but required a payload compatibility fix. tag: Benchmark language: en cover_image_url: https://raw.githubusercontent.com/xujfcn/images/main/blog/covers/jupiter-vs-gpt55-benchmark-2026.webp meta_title: Claude Jupiter v1-p vs GPT-5.5 Benchmark 2026 | Crazyrouter meta_description: Real API benchmark using https://cn.crazyrouter.com/v1 comparing Claude Jupiter v1-p and GPT-5.5 on reasoning, coding, structured output, long context, and agent planning. meta_keywords: claude jupiter v1-p, gpt-5.5, ai model benchmark, coding benchmark, crazyrouter api#
Claude Jupiter v1-p vs GPT-5.5: Real API Benchmark for Reasoning and Coding#
claude-jupiter-v1-p is an interesting model ID because it looks like a test or pre-release Claude route, while gpt-5.5 is the current high-end GPT route available through Crazyrouter.
Instead of guessing from the names, I ran both models through the same benchmark using the China endpoint:
Base URL: https://cn.crazyrouter.com/v1
Models tested:
- claude-jupiter-v1-p
- gpt-5.5
Date: 2026-05-27
The goal was not to create a massive academic benchmark. The goal was more practical:
If I were routing real developer tasks, which model looks smarter, which model codes better, which one is faster, and what hidden API compatibility issues would matter in production?
Short conclusion#
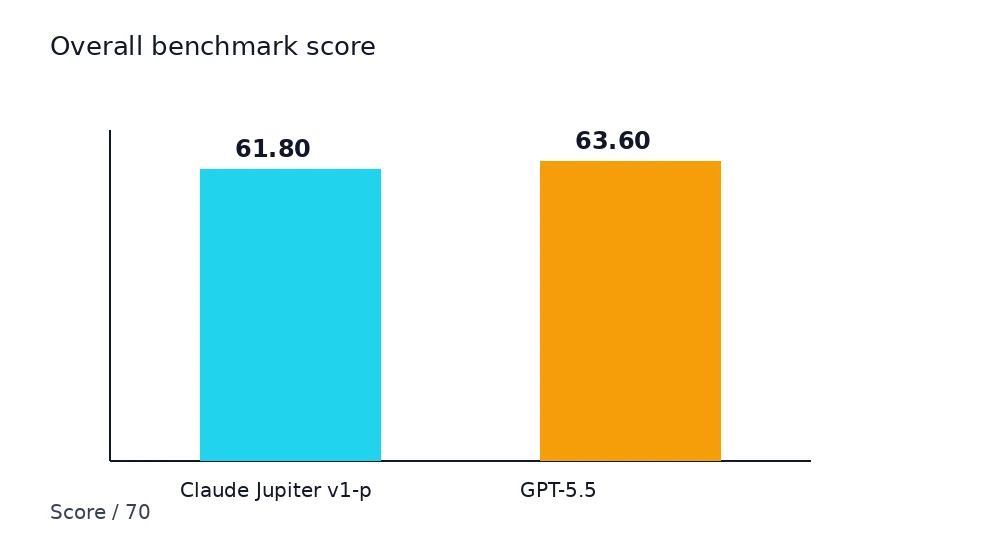
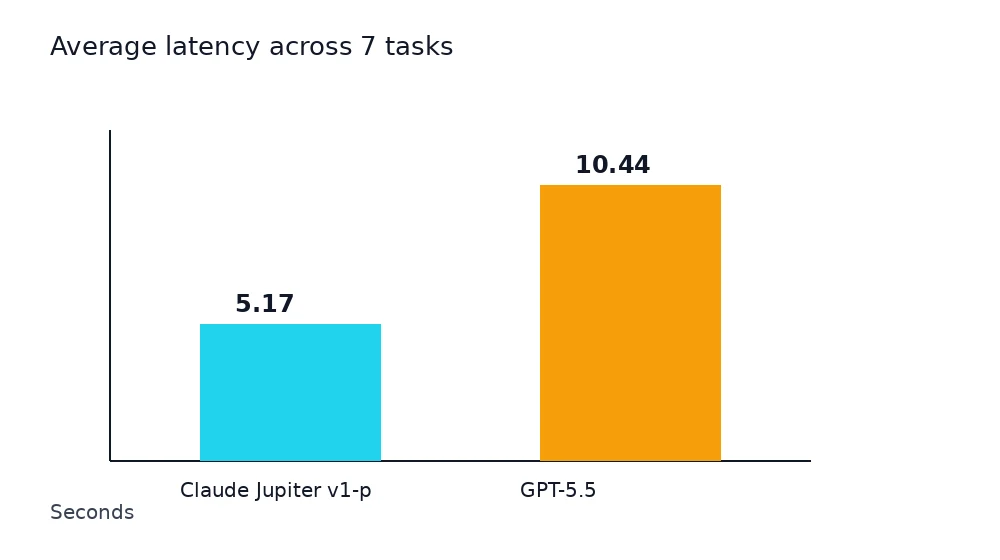
Here is the result from the final runnable test:
| Model | Success rate | Total score | Average score | Average latency | Median latency | Total tokens |
|---|---|---|---|---|---|---|
| claude-jupiter-v1-p | 7/7 | 61.8/70 | 8.83/10 | 5.17s | 3.35s | 6096 |
| gpt-5.5 | 7/7 | 63.6/70 | 9.09/10 | 10.44s | 9.63s | 3802 |
My reading:
- GPT-5.5 won narrowly on quality: 63.6/70 vs 61.8/70.
- Claude Jupiter v1-p was much faster: 5.17s average latency vs 10.44s.
- Both models completed all seven tasks in the fair run.
- Jupiter has an important compatibility caveat: with
temperature: 0included in the OpenAI-compatible payload, it returned400 invalid_requeston every task. Removingtemperaturemade it pass 7/7.
So the practical conclusion is:
GPT-5.5 is the safer quality winner.
Claude Jupiter v1-p is surprisingly competitive and faster, but needs payload compatibility checks before production use.
The most important finding: payload compatibility matters#
The first run used the same OpenAI-compatible payload for both models:
{
"model": "claude-jupiter-v1-p",
"messages": [...],
"temperature": 0,
"max_tokens": 900
}
Result:
| Model | Tasks | Success | Result |
|---|---|---|---|
| claude-jupiter-v1-p | 7 | 0/7 | all returned 400 invalid_request |
| gpt-5.5 | 7 | 7/7 | all completed |
At first glance, that looks like Jupiter failed the benchmark.
But a compatibility probe showed the real issue: Jupiter currently rejects this payload shape when temperature: 0 is included.
I tested several payload variants:
| Jupiter payload variant | Result |
|---|---|
| system + max_tokens + temperature=0 | 0/7 |
| system + max_tokens, no temperature | 7/7 |
| no system, max_tokens, no temperature | 7/7 |
| messages only | 7/7 |
| short minimal prompt | 1/1 |
This matters because production systems often assume OpenAI-compatible parameters are universally accepted. They are not.
For real routing, the correct health check is not just:
Is the model visible in /v1/models?
It should be:
Can the model handle my exact production payload?
Benchmark design#
I used seven tasks designed to reflect practical intelligence and developer usefulness:
| Task | What it tests |
|---|---|
| logic_grid | constraint reasoning and contradiction handling |
| algorithm_design | coding ability, sorting, edge cases |
| bug_fix_patch | patch generation and exception correctness |
| json_schema_extraction | structured output reliability |
| long_context_recall | recall from a long prompt with distractors |
| agent_tool_plan | agent safety policy and workflow design |
| math_word_problem | arithmetic, cost modeling, retry reasoning |
Scoring was heuristic but answer-key based. The raw outputs and scoring JSON are saved with the benchmark so the result can be inspected.
Per-task results#
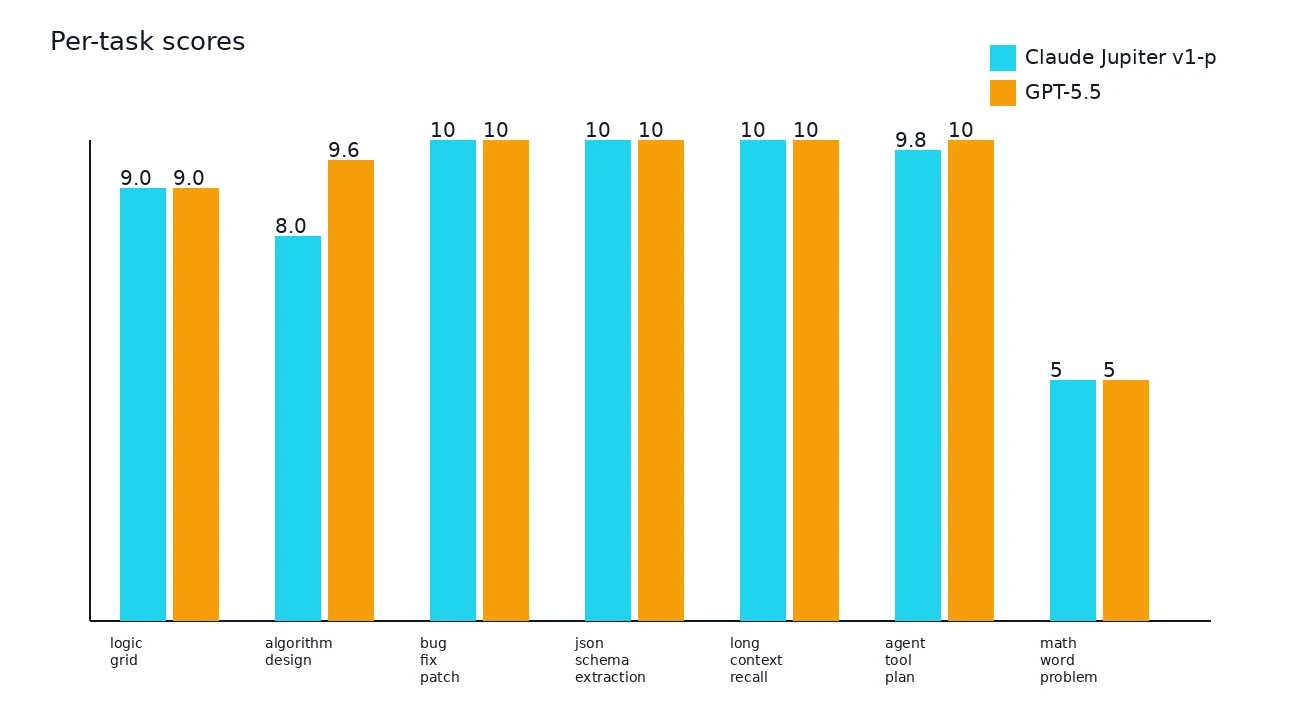
| Task | Jupiter score | GPT-5.5 score | Jupiter latency | GPT-5.5 latency |
|---|---|---|---|---|
| logic_grid | 9.0/10 | 9.0/10 | 5.691s | 11.287s |
| algorithm_design | 8.0/10 | 9.6/10 | 2.411s | 7.045s |
| bug_fix_patch | 10/10 | 10/10 | 3.349s | 9.628s |
| json_schema_extraction | 10/10 | 10/10 | 2.118s | 6.193s |
| long_context_recall | 10/10 | 10/10 | 2.53s | 2.335s |
| agent_tool_plan | 9.8/10 | 10/10 | 13.838s | 14.071s |
| math_word_problem | 5/10 | 5/10 | 6.266s | 22.511s |
A few observations stand out.
1. Reasoning: both solved the logic puzzle#
Both models correctly solved the region/datastore puzzle:
A = Tokyo / Postgres
B = Singapore / S3
C = Frankfurt / Redis
Both scored 9/10. GPT-5.5 gave a more compact answer. Jupiter gave a longer explanation but reached the same result faster.
2. Coding: GPT-5.5 was slightly cleaner on the algorithm task#
The topKFrequent(words, k) task required:
- frequency descending;
- lexicographic tie-break;
- handling
k <= 0and empty input; - better than O(n²).
GPT-5.5 explicitly used localeCompare for tie-breaking and got 9.6/10.
Jupiter also produced a correct implementation, using a direct comparison expression:
entries.sort((a, b) => b[1] - a[1] || (a[0] < b[0] ? -1 : a[0] > b[0] ? 1 : 0));
That is valid, but GPT-5.5's answer was slightly cleaner and easier to read.
3. Patch generation: both were excellent#
Both models fixed the Python retry function correctly:
- initial attempt plus
retriesretries; - preserve and raise the final exception;
- no sleep after the final failed attempt;
- return a unified diff.
Both scored 10/10.
4. JSON extraction: both were perfect#
Both returned valid strict JSON with:
- service;
- severity;
- 27-minute duration;
- connection pool exhaustion root cause;
customer_visible: true;- mitigation actions.
Both scored 10/10.
5. Long-context recall: both passed#
The long-context test buried two important facts among repeated filler:
Jupiter can leave evaluation only after payload stability reaches 99%.
Optimize cost per successful task, not token price.
Both models recalled the key facts correctly.
6. Agent planning: both were strong#
Both models produced an 8-point safe execution policy for an AI coding agent, covering:
- permission boundaries;
- test gates;
- rollback;
- logging;
- model fallback;
- human escalation.
GPT-5.5 was marginally more concise. Jupiter was more detailed.
7. Math/cost reasoning: both got the important answer#
The math problem:
1,200,000 monthly requests
900 input tokens/request
250 output tokens/request
Model X: $0.80/M input, $2.40/M output
Model Y: 35% cheaper but 8% retries
Correct calculation:
Model X = $864 input + $720 output = $1,584.00
Model Y = ($1,584 × 0.65 × 1.08) = $1,111.97
Savings = $472.03/month
Both models produced the correct final conclusion: Model Y is cheaper by about $472.03/month.
What this means for developers#
If you are choosing a default model for coding and agent workflows, I would not make the decision based only on raw score.
I would separate three layers:
Layer 1: Quality#
GPT-5.5 is slightly ahead in this test. It was cleaner on algorithm implementation and more concise in several tasks.
Layer 2: Speed#
Jupiter was much faster in this sample:
Jupiter average latency: 5.17s
GPT-5.5 average latency: 10.44s
That is a big difference if you are building interactive coding tools or agent loops.
Layer 3: Payload stability#
This is where Jupiter needs caution.
The model worked well after removing temperature, but failed completely with temperature: 0 in the payload.
For production, that means you should not simply add it to your model list and route traffic blindly. You should run route-specific health checks:
1. Test /v1/models visibility.
2. Test your exact chat payload.
3. Test streaming if you use streaming.
4. Test tools/function calling if your agent uses tools.
5. Test structured JSON output.
6. Record 400/empty-output/timeout separately.
Recommended routing policy#
Based on this benchmark, I would route like this:
| Use case | Recommended model |
|---|---|
| highest-quality reasoning/coding default | GPT-5.5 |
| latency-sensitive coding helper after compatibility validation | Claude Jupiter v1-p |
| JSON extraction / simple structured tasks | either model |
| agent planning and safety policy | either model, GPT-5.5 slightly safer |
| production routing without custom health checks | GPT-5.5 |
| experimental model lane | Claude Jupiter v1-p |
Reproducibility#
This benchmark used:
Base URL: https://cn.crazyrouter.com/v1
Endpoint: /chat/completions
Models: claude-jupiter-v1-p, gpt-5.5
Tasks: 7
Scoring: answer-key heuristic scoring plus manual inspection of key outputs
Important payload note:
GPT-5.5 used temperature=0.
Claude Jupiter v1-p omitted temperature because compatibility testing showed temperature=0 caused 400 invalid_request.
That is not a minor detail. It is one of the main findings.
Final verdict#
My conclusion:
GPT-5.5 is still the better default if you optimize for quality and production confidence.
Claude Jupiter v1-p is much more capable than a simple test placeholder and was faster in this run, but it must stay behind payload compatibility checks.
If Jupiter's parameter compatibility improves, it could become a very interesting low-latency coding and agent workflow candidate.
But today, I would not replace GPT-5.5 with Jupiter as a default production model.
I would add Jupiter to an evaluation lane, run it against real payloads, and promote it only when route-level stability is proven.