Claude Jupiter v1-p vs Claude Opus 4.7 vs Sonnet 4.6: Live API Test
A live Crazyrouter API test comparing claude-jupiter-v1-p, claude-opus-4-7, claude-sonnet-4-6, and claude-opus-4-6 for coding and structured output workflows.

Claude Jupiter v1-p vs Claude Opus 4.7 vs Sonnet 4.6: Live API Test of Anthropic's New Claude Models#
Based on live API calls through
https://cn.crazyrouter.com/v1on 2026-05-26. We testedclaude-jupiter-v1-p,claude-opus-4-7,claude-sonnet-4-6, andclaude-opus-4-6with the same coding and structured-output tasks.
Quick answer#
claude-jupiter-v1-p is visible in the Crazyrouter /v1/models list and the core calling paths are now usable in our retest: OpenAI Chat Completions, OpenAI streaming, OpenAI tools/function calling, Claude native Messages, Claude native streaming, count_tokens, native tools, and tool_result round trips all returned 200. One caveat: some requests failed when we added non-essential parameters such as temperature, so production routers should still health-check the exact payload shape they plan to use.
Among the working Claude models:
- Claude Opus 4.7 is the safest premium default for complex coding and agentic workflows.
- Claude Sonnet 4.6 is the best daily-driver option when you want strong coding output with lower latency and better cost discipline.
- Claude Opus 4.6 remains a stable baseline, but in this run it was slower on structured JSON than Opus 4.7 and Sonnet 4.6.
- Claude Jupiter v1-p is now usable on the core Crazyrouter calling chain, but should be routed with payload-level health checks because parameter compatibility can still matter.
The practical production rule is simple:
Health-check every model before routing traffic.
Use Sonnet 4.6 for daily coding.
Use Opus 4.7 for hard coding and high-risk agent tasks.
Keep Opus 4.6 as a baseline fallback.
Use Jupiter v1-p only after health-checking your exact endpoint, stream/tool mode, and payload parameters.
SERP research: what people are searching for#
Before writing this article, we checked current search results for Claude Jupiter, Claude Opus 4.7, Claude Sonnet 4.6, and Claude model benchmarks.
The current pattern is clear:
- There are rumor-style pages about
claude-jupiter-v1-pappearing in testing or red-team contexts. - Official and semi-official pages emphasize Opus 4.7 as a stronger coding and agentic model compared with Opus 4.6.
- Many benchmark pages repeat headline benchmark claims, but fewer pages show real API behavior through an OpenAI-compatible gateway.
That gap matters. A model can appear in a model list before every payload shape is production-safe. For developers, the first question is not “is the model exciting?” It is:
Can I call it successfully across the exact endpoints, streaming modes, tools, and payload parameters my app uses?
That is what this article tests.
Test setup#
All tests used Crazyrouter's OpenAI-compatible API:
Base URL: https://cn.crazyrouter.com/v1
Endpoint: /chat/completions
Date: 2026-05-26
Models:
- claude-jupiter-v1-p
- claude-opus-4-7
- claude-sonnet-4-6
- claude-opus-4-6
We first called /v1/models. All four model IDs appeared in the model list:
claude-jupiter-v1-p
claude-opus-4-7
claude-sonnet-4-6
claude-opus-4-6
We first ran the same four coding tasks against each model. After Jeff confirmed the core Jupiter route had been updated, we also ran a dedicated Jupiter endpoint compatibility retest.
- Retry patch — fix a Python retry helper with correct retry semantics.
- JSON schema — return a valid structured JSON object describing routing role, strengths, risks, and recommended use cases.
- Unified diff patch — generate a JS patch for
topK(words, k)with empty-array handling and tie-breaking. - Cost reasoning — explain when to route coding tasks to premium Claude versus cheaper fallback models.
Live test results#
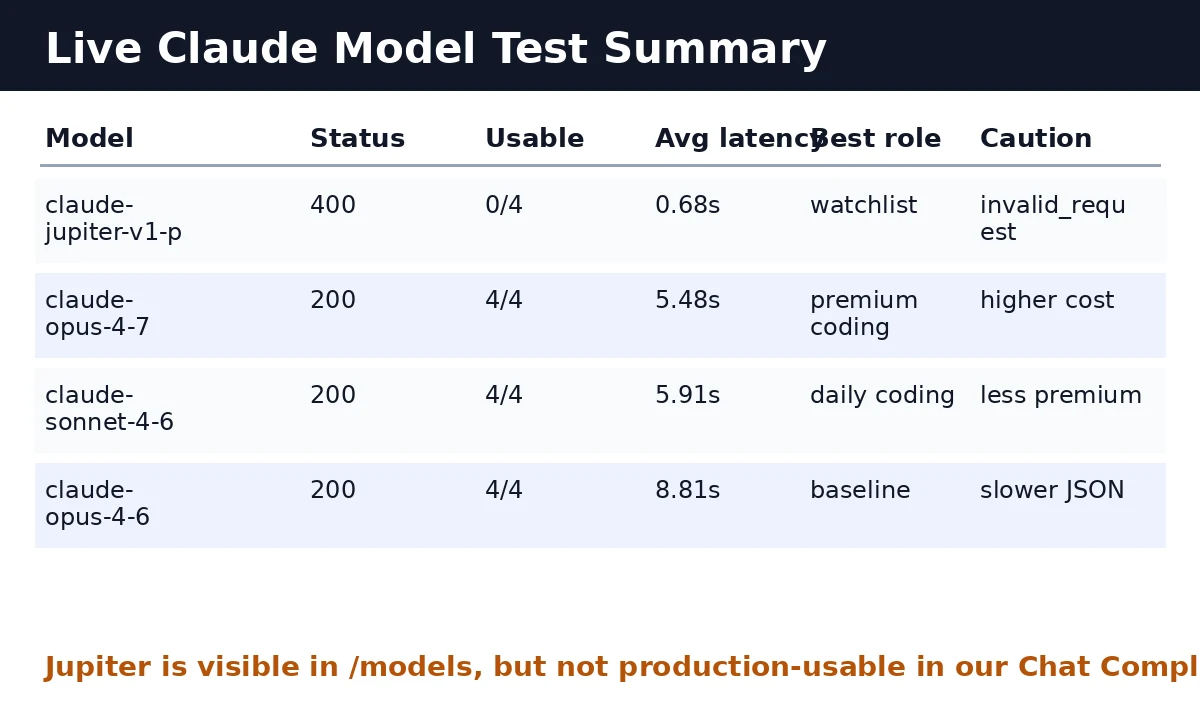
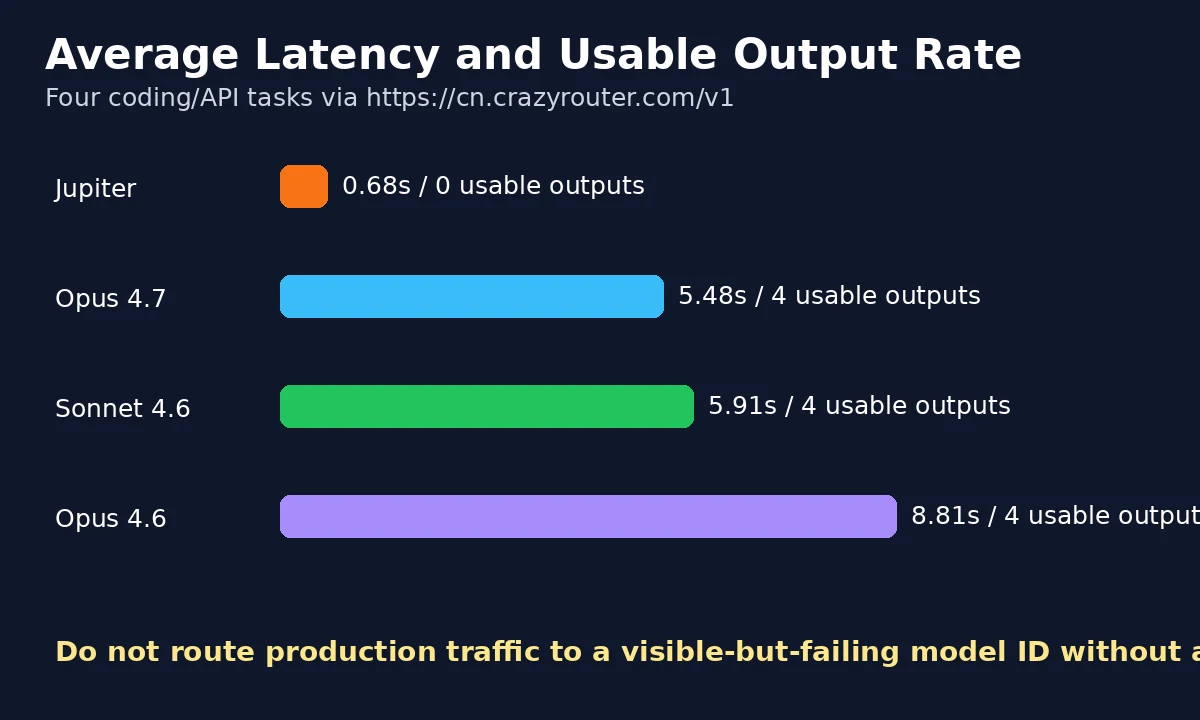
| Model | Endpoint status | Usable outputs | Average latency | Result |
|---|---|---|---|---|
claude-jupiter-v1-p | 200 on core routes | Core chain passed; coding prompts passed without extra params | 1.65s non-stream chat / 2.02s tool call | Supported on core endpoints; health-check exact payloads |
claude-opus-4-7 | 200 | 4 / 4 | 5.48s | Best premium default for hard coding |
claude-sonnet-4-6 | 200 | 4 / 4 | 5.91s | Strong daily coding model |
claude-opus-4-6 | 200 | 4 / 4 | 8.81s | Stable baseline, slower in this run |
The raw result file is saved internally as:
/root/.openclaw/workspace/generated/claude_new_models_comparison_2026/benchmark.json
What happened with Claude Jupiter v1-p?#
claude-jupiter-v1-p was the most interesting result because it changed from visible-but-failing in the first coding run to usable across the core calling chain in the retest.
In the first run, the coding payloads returned HTTP 400. After the route update, the core endpoint retest passed:
{
"error": {
"message": "Invalid request.",
"type": "new_api_error",
"param": "",
"code": "invalid_request"
}
}
That means the correct conclusion is no longer 'Jupiter is unavailable.' The better conclusion is: Jupiter is supported on the core chain, but production apps should still run exact-payload health checks.
The retest passed these routes:
/v1/chat/completionsnon-streaming: 200/v1/chat/completionsstreaming SSE: 200- OpenAI tools/function calling: 200, returned
tool_calls /v1/messagesClaude native non-streaming: 200/v1/messagesClaude native streaming SSE: 200/v1/messages?beta=true: 200/v1/messages/count_tokens: 200- Claude native tools request: 200
- Claude
tool_resultround trip: 200
For model routers and coding agents, the lesson is still important: model discovery is not enough. You need live request health checks on the exact route you plan to use.
Jupiter endpoint retest: core route now passes#
After the first run, Jeff confirmed that the core claude-jupiter-v1-p calling chain had been updated. We retested the model through Crazyrouter and confirmed the following:
| Route | Result | Notes |
|---|---|---|
/v1/models | 200 | claude-jupiter-v1-p visible |
/v1/chat/completions non-streaming | 200 | returned JUPITER_OK |
/v1/chat/completions streaming SSE | 200 | streamed chunks successfully |
| OpenAI tools/function calling | 200 | returned tool_calls |
/v1/messages Claude native | 200 | returned text block |
/v1/messages Claude native streaming | 200 | streamed events successfully |
/v1/messages?beta=true | 200 | returned text block |
/v1/messages/count_tokens | 200 | returned token count |
| Claude native tools | 200 | returned tool_use |
Claude tool_result round trip | 200 | completed final assistant response |
We also confirmed simple coding prompts work when sent with the minimal required payload. The previous 400s appear tied to payload compatibility rather than the model being unavailable.
Claude Opus 4.7: best premium default#
Claude Opus 4.7 completed all four tasks successfully.
In this run:
- retry patch: 3.24s
- JSON schema: 6.91s
- unified diff patch: 4.09s
- cost reasoning: 7.69s
- usable outputs: 4 / 4
- average latency: 5.48s
The outputs were concise and production-friendly. It fixed the retry helper correctly, generated a usable diff, and produced structured planning output without empty-content failure.
This matches the role we would expect from a premium Claude model:
- complex coding
- production patch generation
- high-risk agent steps
- structured output
- tasks where failure is expensive
The downside is cost. Premium models should not be used for every trivial task. They should be reserved for tasks where success rate matters more than raw token price.
Claude Sonnet 4.6: best daily coding model#
Claude Sonnet 4.6 also completed all four tasks successfully.
In this run:
- retry patch: 2.20s
- JSON schema: 8.23s
- unified diff patch: 3.73s
- cost reasoning: 9.49s
- usable outputs: 4 / 4
- average latency: 5.91s
Sonnet 4.6 was especially fast on the retry patch and unified diff tasks. It is the model I would use as the default for daily coding workflows where you still want Claude-level reliability but do not want to send everything to the most premium Opus model.
Recommended use cases:
- routine bug fixing
- unit test generation
- code explanation
- medium-risk refactors
- CI helper tasks after validation
- IDE assistant workflows
For many teams, Sonnet 4.6 is the practical default, with Opus 4.7 reserved for harder tasks.
Claude Opus 4.6: stable baseline, but slower here#
Claude Opus 4.6 also completed every task successfully.
In this run:
- retry patch: 2.66s
- JSON schema: 17.81s
- unified diff patch: 4.20s
- cost reasoning: 10.58s
- usable outputs: 4 / 4
- average latency: 8.81s
The main issue was the structured JSON task, where it took much longer than Opus 4.7 and Sonnet 4.6. That does not make Opus 4.6 bad. It remains a useful baseline and fallback model. But if Opus 4.7 is available at the same integration layer, Opus 4.7 looks like the better premium routing target.
Recommended routing policy#
For a production AI coding stack, I would not hard-code one Claude model everywhere.
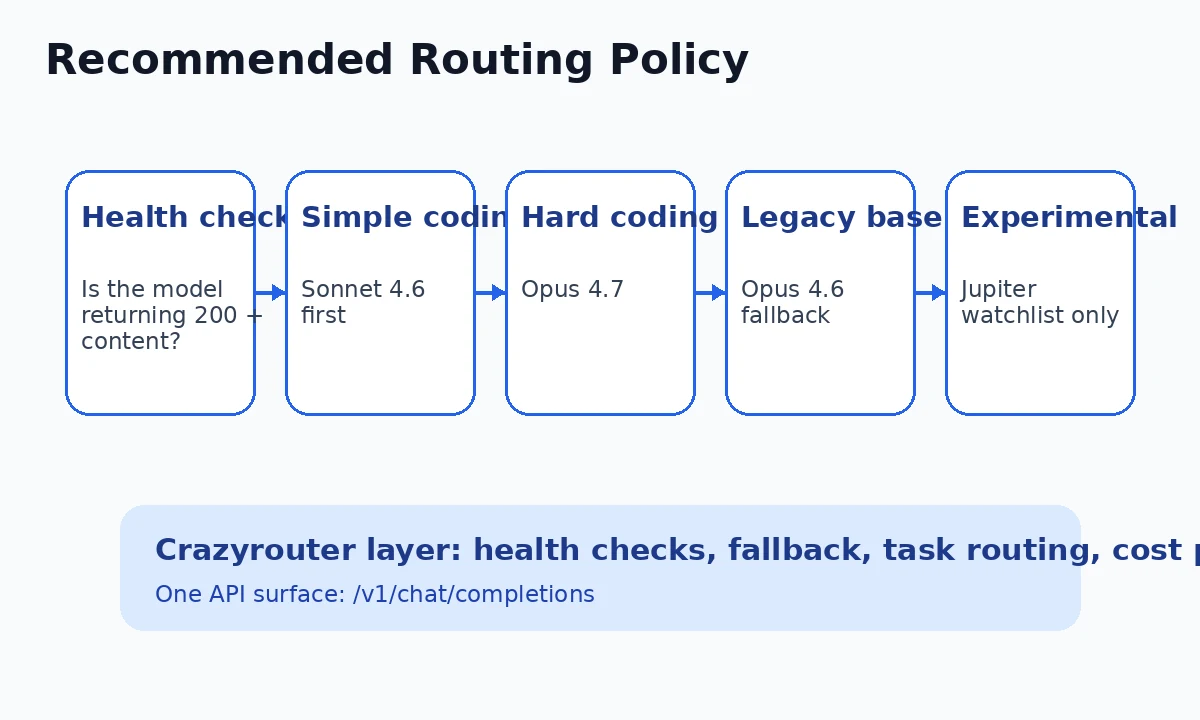
A better policy is:
| Task type | Recommended model | Why |
|---|---|---|
| Model health check | all candidates | catch visible-but-failing IDs like Jupiter |
| Daily coding | Claude Sonnet 4.6 | strong quality and practical latency |
| Complex bug fix | Claude Opus 4.7 | better premium default |
| High-risk agent step | Claude Opus 4.7 | success matters more than token cost |
| Baseline fallback | Claude Opus 4.6 | stable backup path |
| New Claude route testing | Claude Jupiter v1-p | core route supported; health-check exact payloads |
Why this matters for Crazyrouter users#
Crazyrouter makes this kind of test useful because all calls go through the same OpenAI-compatible API surface:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_CRAZYROUTER_KEY",
base_url="https://cn.crazyrouter.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Generate a unified diff patch for this bug."}
],
max_tokens=1200,
)
print(response.choices[0].message.content)
The same code can test:
claude-jupiter-v1-p
claude-opus-4-7
claude-sonnet-4-6
claude-opus-4-6
That lets you build a real routing layer:
- discover available models
- run health checks
- measure latency
- validate output quality
- fallback when a model fails
- avoid sending production traffic to a model that only appears available
Final verdict#
Here is the practical conclusion from this live test:
Claude Jupiter v1-p: core Crazyrouter calling chain is usable; exact payload health checks still required
Claude Opus 4.7: best premium default for hard coding and agents
Claude Sonnet 4.6: best daily-driver Claude model
Claude Opus 4.6: stable baseline fallback
Crazyrouter: the API layer that makes live comparison and routing practical
The headline is not “Jupiter beats Opus” or “Opus beats Sonnet.”
The real lesson is:
For production AI coding, always combine model discovery with live health checks, output validation, and fallback routing.
That is how you safely adopt new Claude models without breaking your coding agent or CI workflow.
FAQ#
Is claude-jupiter-v1-p available?#
Yes. In the latest retest, it appeared in /v1/models and passed the core Crazyrouter calling chain: OpenAI chat, streaming, tools/function calling, Claude native Messages, native streaming, beta Messages, count_tokens, native tools, and tool_result round trip. Still health-check the exact payload shape your app will use.
Is Claude Opus 4.7 better than Opus 4.6?#
In our test, Opus 4.7 completed all tasks and had lower average latency than Opus 4.6. It is the better premium default based on this run.
Is Claude Sonnet 4.6 still worth using?#
Yes. Sonnet 4.6 completed all tasks and was especially fast on patch and diff tasks. It is a strong default for daily coding.
Which Claude model should coding agents use?#
Use Sonnet 4.6 for routine tasks, Opus 4.7 for difficult or high-risk steps, and keep Opus 4.6 as a fallback. Route to Jupiter only after your exact payload passes health checks.
Why use Crazyrouter for Claude model testing?#
Crazyrouter lets you compare and route multiple models through one OpenAI-compatible API endpoint. That makes it easier to test availability, latency, output quality, and fallback behavior before production deployment.



