Opus 4.8 vs Opus 4.7 for Agents: JSON, Tool Use, and Structured Output
Our real API test found Opus 4.7 cleaner than Opus 4.8 for strict JSON-style output, while Opus 4.8 remained strong for reasoning and explanation.

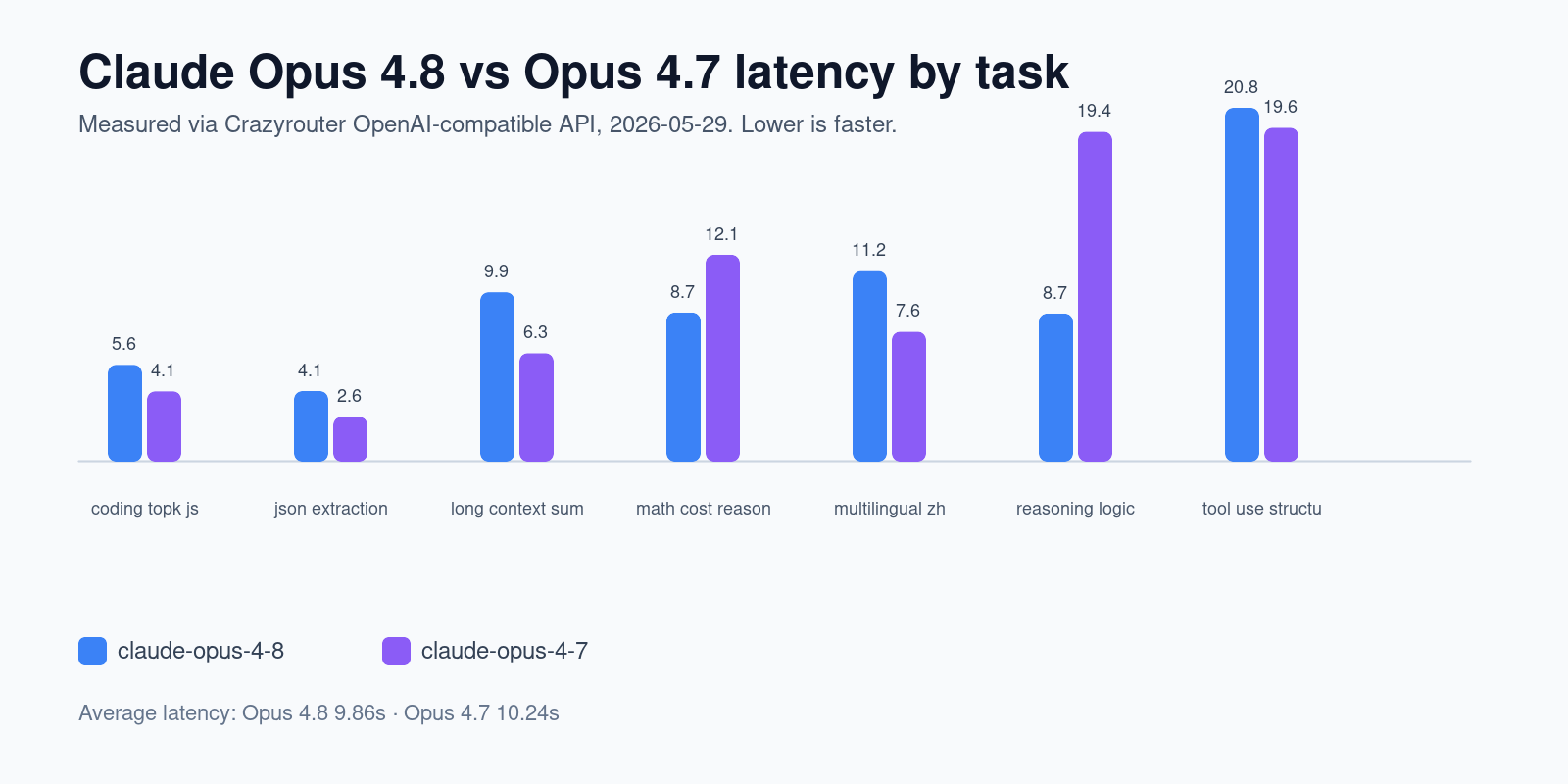
Agent workflows are not only about intelligence. They are about whether a model follows exact output contracts.
In our Opus 4.8 vs Opus 4.7 API benchmark, both models succeeded semantically. But the structured-output tests showed an important difference.
Result snapshot#
| Task | Opus 4.8 | Opus 4.7 |
|---|---|---|
| JSON extraction/schema following | Valid JSON, correct duration | Valid JSON, correct duration |
| Tool-use structured plan | Useful answer, but invalid JSON or extra text | Valid JSON, 14 steps |
| Chinese/Japanese structured output | Useful answer, but invalid JSON or extra text | Valid JSON with zh/ja |
Why this matters#
For agents, invalid JSON is not a cosmetic problem. It can break a workflow, trigger retries, or cause a tool call to fail.
That is why production systems should not judge models only by reasoning quality. They should measure:
- valid JSON rate,
- schema compliance,
- retry rate,
- tool-call success rate,
- and cost per successful task.

Routing recommendation#
Use Opus 4.8 when the task needs complex analysis or reasoning. But for strict schema output, either validate Opus 4.8 aggressively or route the task to Opus 4.7 when it shows better compliance on your prompts.
A gateway pattern works well:
request -> model route -> JSON validation -> accept or retry/fallback
This is the practical difference between a demo and production AI infrastructure.


