Claude Opus 4.8 vs Opus 4.7: Real API Benchmark Results for Developers
We tested claude-opus-4-8 and claude-opus-4-7 through the Crazyrouter OpenAI-compatible API across reasoning, coding, JSON extraction, long context, tool-use planning, multilingual output, and cost reasoning.

Claude Opus 4.8 is now available on Crazyrouter, and the obvious question for developers is simple: is Opus 4.8 actually better than Opus 4.7 in real API usage?
We ran a practical benchmark through the Crazyrouter OpenAI-compatible endpoint using the exact model IDs:
claude-opus-4-8claude-opus-4-7
This article is based on measured API responses, not vendor claims. Every prompt was saved, and every result includes latency, success/failure, token usage where available, and qualitative notes.
API endpoint used for testing:
https://crazyrouter.com/v1
Human link: Try both Claude Opus models on Crazyrouter
Executive summary#
- Both models completed all 7 benchmark tasks successfully.
- Opus 4.8 averaged 9.86s latency across successful calls.
- Opus 4.7 averaged 10.24s latency across successful calls.
- Opus 4.8 was notably faster on the logic-grid reasoning task: 8.67s vs 19.37s.
- Opus 4.7 was cleaner on strict JSON-style tasks, especially tool-use planning and multilingual structured output.
- The practical recommendation: use Opus 4.8 for reasoning-heavy analysis, and keep Opus 4.7 in the routing pool for strict schema/JSON reliability.
Test setup#
The benchmark used the Crazyrouter OpenAI-compatible API, which lets developers call different models with one base URL and one API key.
curl https://crazyrouter.com/v1/chat/completions \
-H "Authorization: Bearer $CRAZYROUTER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-opus-4-8",
"messages": [{"role": "user", "content": "Say ok"}]
}'
Validation calls confirmed both models were available and responding:
| Model | Status | Latency | Output |
|---|---|---|---|
claude-opus-4-8 | 200 | 3.69s | ok |
claude-opus-4-7 | 200 | 3.96s | ok |
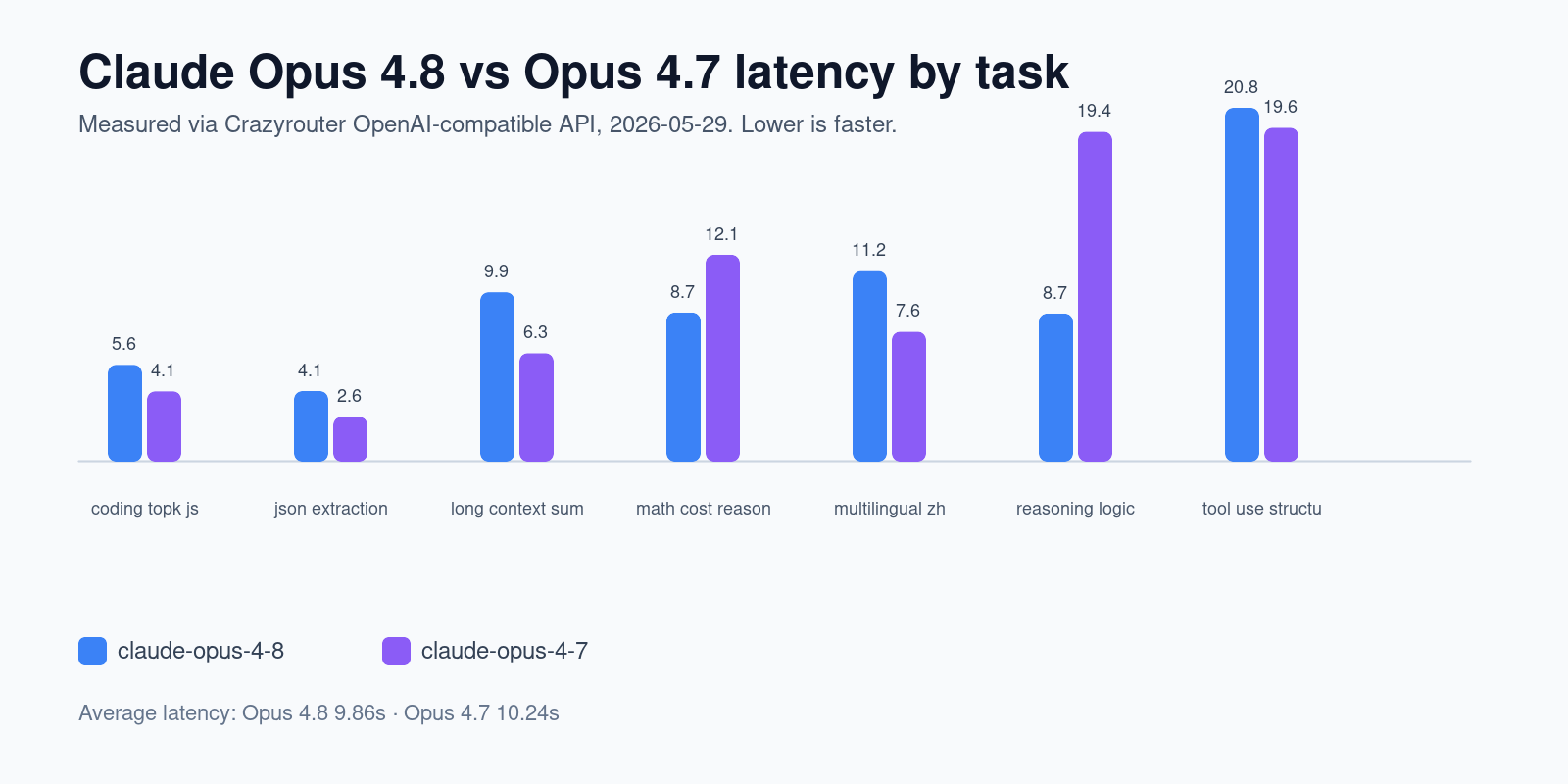
Benchmark task results#
| Task | Category | Opus 4.8 latency | Opus 4.7 latency | Winner | Key observation |
|---|---|---|---|---|---|
coding_topk_js | coding | 5.65s | 4.09s | Opus 4.7 | Uses Map/counting; Tie sort likely present |
json_extraction_schema | JSON extraction/schema following | 4.10s | 2.58s | Opus 4.7 | Valid JSON; Duration correct |
long_context_summarization_recall | long_context_summarization | 9.92s | 6.33s | Opus 4.7 | Mentions 99% stability; Mentions cost per successful task |
math_cost_reasoning | reasoning | 8.72s | 12.13s | Opus 4.8 | Contains expected X total; Contains expected delta |
multilingual_zh_ja | multilingual Chinese/Japanese | 11.17s | 7.60s | Opus 4.7 | Opus 4.7 produced cleaner strict JSON; Opus 4.8 added extra text or invalid JSON. |
reasoning_logic_grid | reasoning | 8.66s | 19.37s | Opus 4.8 | Identifies inconsistency |
tool_use_structured_plan | tool-use style structured output | 20.78s | 19.61s | Opus 4.7 | Opus 4.7 produced cleaner strict JSON; Opus 4.8 added extra text or invalid JSON. |
What Opus 4.8 does better#
1. Faster reasoning in complex constraint tasks#
The biggest latency difference appeared in the logic-grid reasoning test. Both models correctly identified the inconsistency, but Opus 4.8 returned in 8.67s, while Opus 4.7 took 19.37s.
For developer workflows like architectural review, incident analysis, planning, and multi-constraint reasoning, this matters. If a model can produce the same correct conclusion with lower latency, it is easier to use inside interactive products.
2. More expansive explanations#
Across several tasks, Opus 4.8 tended to produce longer and more explanatory answers. Total output tokens were:
| Model | Successful tasks | Total output tokens |
|---|---|---|
claude-opus-4-8 | 7/7 | 2599 |
claude-opus-4-7 | 7/7 | 2239 |
This is useful when you want analysis depth, but it also means you should control output length if you are optimizing cost.
Where Opus 4.7 still looks stronger#
Strict JSON and schema-style output#
In our tool-use structured planning test, Opus 4.7 produced valid JSON with 14 steps. Opus 4.8 completed the task semantically, but added extra text or produced invalid strict JSON.
The same pattern appeared in the multilingual Chinese/Japanese test: Opus 4.7 returned clean JSON with both zh and ja; Opus 4.8 was useful but less strict about the JSON-only instruction.
That does not mean Opus 4.8 is bad at structure. It means production teams should still validate outputs and route schema-critical tasks carefully.

Recommended routing strategy#
A practical production routing policy could look like this:
If task is reasoning-heavy, analysis-heavy, or explanation-heavy:
prefer claude-opus-4-8
If task requires strict JSON, exact schema, or tool-call-style structured output:
try claude-opus-4-7 or validate Opus 4.8 output before accepting
If output validation fails:
retry with stricter system instructions or fallback to the more schema-stable route
This is exactly why model routing matters. The best model is not always one static choice. It depends on the task.
Developer takeaway#
Claude Opus 4.8 looks like a meaningful upgrade for reasoning speed and explanatory analysis. But Opus 4.7 remains valuable in workflows where strict structured output matters more than raw reasoning speed.
For production AI apps, the best approach is not to replace every route blindly. Instead:
- test both models with your real prompts,
- measure success per task, not just token price,
- validate schema-critical responses,
- keep fallbacks available,
- and route by workflow.
Crazyrouter makes this easier because you can test and route both models behind one OpenAI-compatible API layer.
Start testing Claude Opus 4.8 and Opus 4.7 on Crazyrouter
Raw benchmark artifacts#
The benchmark recorded model IDs, prompts, latency, usage, success/failure, and qualitative notes. The most important point is that the conclusions above are tied to actual API responses, not marketing copy.