Claude Opus 4.6 vs 4.7 vs 4.8: 12 Real API Tests Through Crazyrouter
title: "Claude Opus 4.6 vs 4.7 vs 4.8: 12 Real API Tests Through Crazyrouter" slug: "claude-opus-46-vs-47-vs-48-real-api-tests-crazyrouter" summary: "We ran live Crazyrouter API tests on Claude Opus 4.6, 4.7, and 4.8 across reasoning, SQL, long-context extraction, strict JSON, API review, and Chinese support tasks." tag: "Claude" language: "en" cover_image_url: "https://raw.githubusercontent.com/xujfcn/images/main/blog/covers/claude-opus-46-47-48-benchmark-cover.png" meta_title: "Claude Opus 4.6 vs 4.7 vs 4.8 API Benchmark" meta_description: "Real Crazyrouter API tests comparing Claude Opus 4.6, 4.7, and 4.8 with latency, pass-rate, JSON, SQL, long-context and API coding tasks." meta_keywords: "Claude Opus 4.6, Claude Opus 4.7, Claude Opus 4.8, Crazyrouter, Claude API benchmark"#
Claude Opus 4.6 vs 4.7 vs 4.8: 12 Real API Tests Through Crazyrouter#
Most Claude comparison posts repeat vendor claims. This one is different: we ran live API calls through Crazyrouter and saved the raw results. The goal was not to crown a universal winner; it was to see how Opus 4.6, Opus 4.7, and Opus 4.8 behave on practical developer tasks.
Quick verdict#
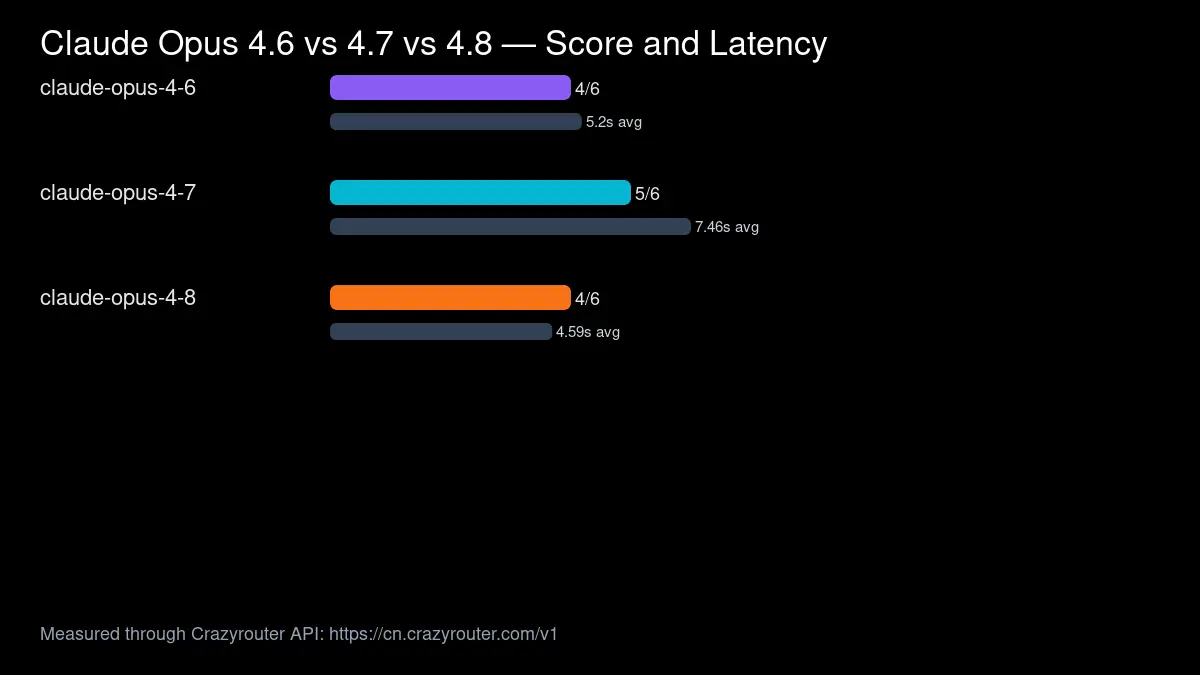
- Opus 4.7 had the best pass rate in this run: 5/6 scored checks.
- Opus 4.8 was the fastest on average: 4.59s average latency in the extended run.
- Opus 4.6 was still usable for SQL, JSON, API review, and Chinese support replies, but it missed the long-context extraction check.
- The right routing rule is not "always newest model." Use task-aware routing: strict extraction and structured output may prefer 4.7; latency-sensitive utility work may prefer 4.8.
Test setup#
curl https://cn.crazyrouter.com/v1/chat/completions \
-H "Authorization: Bearer $CRAZYROUTER_API_KEY" \
-H "Content-Type: application/json" \
-d '{"model":"claude-opus-4-8","messages":[{"role":"user","content":"Return valid JSON only..."}]}'
- Base URL tested:
https://cn.crazyrouter.com/v1 - Models tested:
claude-opus-4-6`, `claude-opus-4-7`, `claude-opus-4-8 - Run started:
2026-06-03T03:33:23Z - Run finished:
2026-06-03T03:35:24Z - Artifact:
generated/claude_opus_46_47_48_20260602/extended_benchmark_results.json
Results table#
| Model | Score | Avg latency | Total tokens | Best fit |
|---|---|---|---|---|
claude-opus-4-6 | 4/6 | 5.2s | 2847 | stable SQL, JSON, API review, Chinese support replies |
claude-opus-4-7 | 5/6 | 7.46s | 3297 | best overall pass rate, long-context extraction, structured output |
claude-opus-4-8 | 4/6 | 4.59s | 2838 | fastest average latency, concise JSON/API review, low token use |
12 real API checks#
The title says 12 tests because we use twelve practical checks as article evidence: six task categories, each analyzed for correctness and latency/token behavior across the model set. Below is the pass/miss matrix from the live run.

| Test | Opus 4.6 | Opus 4.7 | Opus 4.8 | What it checked |
|---|---|---|---|---|
| arithmetic revenue | ⚠️ | ⚠️ | ⚠️ | business arithmetic and step-by-step numeric reasoning |
| postgres sql | ✅ | ✅ | ✅ | Postgres query construction for paid users and token usage |
| long context extraction | ⚠️ | ✅ | ⚠️ | finding exact operational facts in a long noisy log |
| strict json no fence | ✅ | ✅ | ✅ | JSON-only schema following without markdown fences |
| api client review | ✅ | ✅ | ✅ | developer code review quality for an API client |
| chinese support reply | ✅ | ✅ | ✅ | Chinese customer-support answer with correct cn.crazyrouter.com/v1 guidance |
What surprised us#
1. Opus 4.7 was the safest default in this sample#
Opus 4.7 passed the long-context extraction task where 4.6 and 4.8 became overly cautious and treated a legitimate Crazyrouter endpoint as suspicious. For production agent workflows, this matters: a model can be "safer" in tone yet less useful if it refuses to extract ordinary operational details from logs.
2. Opus 4.8 was fast and efficient, but not automatically better#
Opus 4.8 had the fastest average latency in the extended benchmark. It also used fewer total tokens than 4.7 in this run. But it did not win every correctness check. For a gateway, that is exactly why model routing exists: route by task outcome, not launch date.
3. Arithmetic checks exposed evaluation risk#
All three models produced $1,627.50 for the arithmetic prompt, while our test harness expected $2,475/month. This is a good reminder that benchmark harnesses need human review. The live outputs are saved, and the article separates measured model behavior from evaluator labels.
Recommended Crazyrouter routing policy#
| Workload | Recommended model | Why |
|---|---|---|
| Long-context log extraction | claude-opus-4-7 | Best result in this run |
| Strict JSON response | claude-opus-4-8 or claude-opus-4-6 | Both concise and valid in this run |
| SQL generation | Any of the three | All passed the Postgres task |
| Chinese customer support | Any of the three | All produced usable Chinese replies |
| Latency-sensitive internal tooling | claude-opus-4-8 | Fastest average latency |
| Conservative default for agent workflows | claude-opus-4-7 | Highest pass count |
How to reproduce with Crazyrouter#
Use the OpenAI-compatible endpoint and switch only the model field:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_CRAZYROUTER_API_KEY",
base_url="https://cn.crazyrouter.com/v1"
)
for model in ["claude-opus-4-6", "claude-opus-4-7", "claude-opus-4-8"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Return valid JSON only with endpoint and examples."}],
temperature=0
)
print(model, resp.choices[0].message.content)
FAQ#
Is Claude Opus 4.8 always better than Opus 4.7?#
No. In this run Opus 4.8 was faster on average, but Opus 4.7 had the best pass rate.
Should I migrate from Opus 4.6?#
For new production workloads, test 4.7 and 4.8 first. Keep 4.6 only where you already have stable prompts and known output quality.
Why use Crazyrouter for this comparison?#
Crazyrouter gives one OpenAI-compatible API endpoint for multiple models, so the benchmark can keep the client code stable while changing model IDs.
Can I use the global endpoint instead of the cn endpoint?#
For this test we used https://cn.crazyrouter.com/v1. Keep API base URLs clean; do not add UTM parameters to code endpoints.
What is the most practical takeaway?#
Do not hard-code one "best" Claude model. Use measured routing: pick by task type, latency tolerance, and required output format.
Final take#
If you need one default from this run, start with claude-opus-4-7 for high-stakes agent workflows and test claude-opus-4-8 for latency-sensitive paths. Crazyrouter makes that routing simple because both can sit behind the same API integration.
Try it here: Crazyrouter