Dimensi text-embedding-3-small Dijelaskan: Cara Memilih Saiz yang Tepat untuk Kualiti dan Kos
Panduan praktis untuk dimensi text-embedding-3-small, cara memilih antara 256, 512, 1024, dan 1536 dimensi.

text-embedding-3-small Penjelasan Dimensi: Cara Memilih Ukuran yang Tepat untuk Kualitas, Kecepatan, dan Biaya#
Pada 1536 dimensi, satu vektor text-embedding-3-small yang disimpan sebagai float32 menggunakan 6,144 bita, jadi 10 juta vektor membutuhkan sekitar 61 GB sebelum overhead indeks. Angka itu mengejutkan tim ketika pengambilan tampak murah dalam skala kecil, kemudian tagihan memori meningkat dan waktu kueri bertambah setelah korporus berkembang. Bagian yang sulit adalah bahwa dimensi yang lebih tinggi dapat meningkatkan peringkat pada satu dataset, namun pengaturan yang sama dapat membuang-buang penyimpanan dan menambah latensi pada dataset lain.
Itulah inti dari text-embedding-3-small Penjelasan Dimensi: tidak ada pengaturan universal yang menang di setiap beban kerja. Anda perlu memilih ukuran dimensi dengan menguji target relevansi Anda sendiri, batas latensi p95, dan anggaran penyimpanan vektor bersama-sama, bukan satu per satu. Jika Anda hanya menyetel untuk kualitas, biaya meningkat dengan cepat. Jika Anda hanya mengurangi ukuran, kualitas pencarian dapat menurun dengan cara yang pengguna perhatikan.
Anda akan melihat metode pemilihan praktis: buat kumpulan eval kecil, bandingkan relevansi pada dua atau tiga ukuran dimensi, ukur waktu respons end-to-end, dan ubah jumlah dimensi menjadi biaya penyimpanan nyata per juta vektor. Dari sana, ukuran yang tepat menjadi pilihan teknik yang terukur, bukan dugaan.
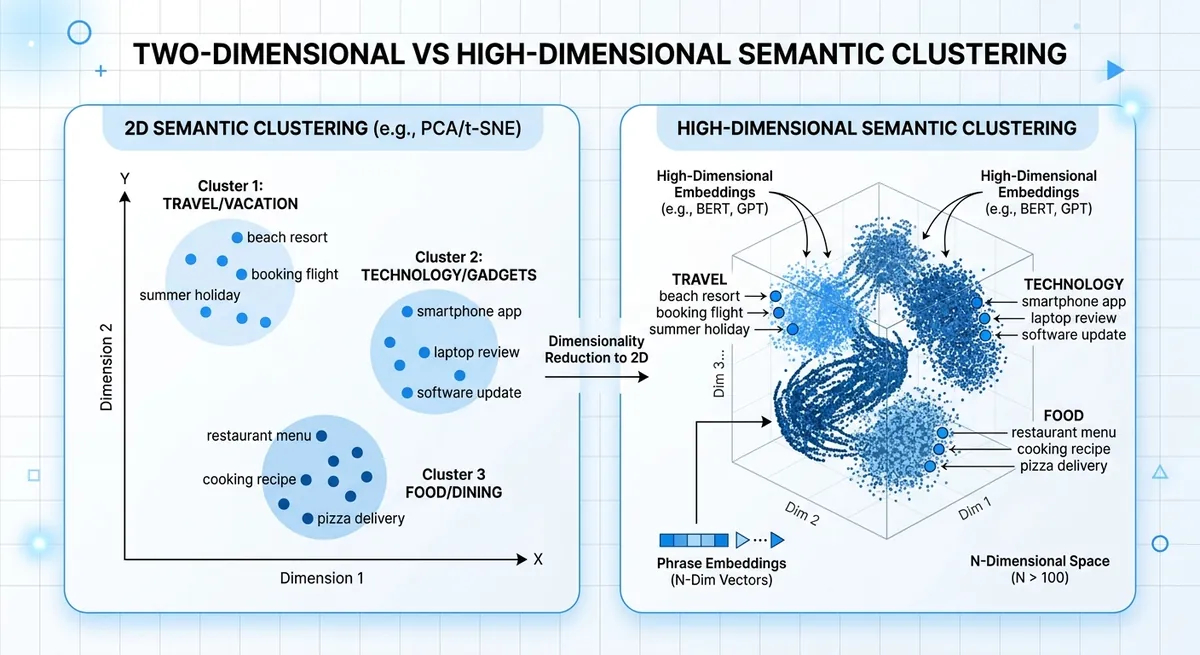
Apa Arti "Dimensi" di text-embedding-3-small (dan Mengapa Ini Mengubah Hasil)#
Dalam istilah sederhana, Penjelasan Dimensi text-embedding-3-small berarti satu hal: berapa banyak makna yang Anda simpan di setiap vektor. Jumlah dimensi adalah tombol kompresi, bukan saklar kualitas. text-embedding-3-small memiliki ukuran maksimal 1536 dimensi (dari spesifikasi model dalam basis pengetahuan). Ukuran yang lebih rendah mengompresi lebih keras.
Penjelasan dimensi text-embedding-3-small: makna semantik ke vektor numerik#
Embedding mengubah teks menjadi angka sehingga frasa serupa duduk berdekatan dalam ruang vektor. "Reset kata sandi saya" dan "Saya tidak bisa masuk" harus mendarat berdekatan. Setiap dimensi tambahan memberi model lebih banyak ruang untuk menyimpan nuansa seperti niat, nada, atau istilah domain. Jika Anda mengecilkan vektor, Anda menyimpan makna inti tetapi menghilangkan detail yang lebih halus.
Penjelasan perubahan kualitas peringkat dimensi text-embedding-3-small#
Dimensi yang lebih rendah dapat mempercepat pencarian dan mengurangi penyimpanan, tetapi peringkat tetangga terdekat dapat bergeser. Pergeseran itu muncul ketika dua niat terlihat serupa di permukaan tetapi berbeda dalam tindakan, seperti "batalkan rencana" vs "jeda rencana."
| Pilihan ukuran vektor | Kesetiaan semantik | Kecepatan runtime | Penyimpanan per 1M vektor (float32) |
|---|---|---|---|
| 1536 (text-embedding-3-small penuh) | Retensi detail tertinggi | Lebih lambat dari vektor yang lebih kecil | ~6,1 GB |
| 768 (terkompresi) | Beberapa kehilangan detail | Lebih cepat | ~3,1 GB |
| 512 (terkompresi) | Risiko kerugian lebih pada niat yang dekat | Bahkan lebih cepat | ~2,0 GB |
Sumber: dimensi maksimal text-embedding-3-small dari basis pengetahuan yang disediakan; matematika penyimpanan dari dimensi × 4 bita.
Itulah inti praktis dari Penjelasan Dimensi text-embedding-3-small: sesuaikan dimensi dengan tes relevansi, latensi p95, dan penyimpanan vektor bersama-sama.
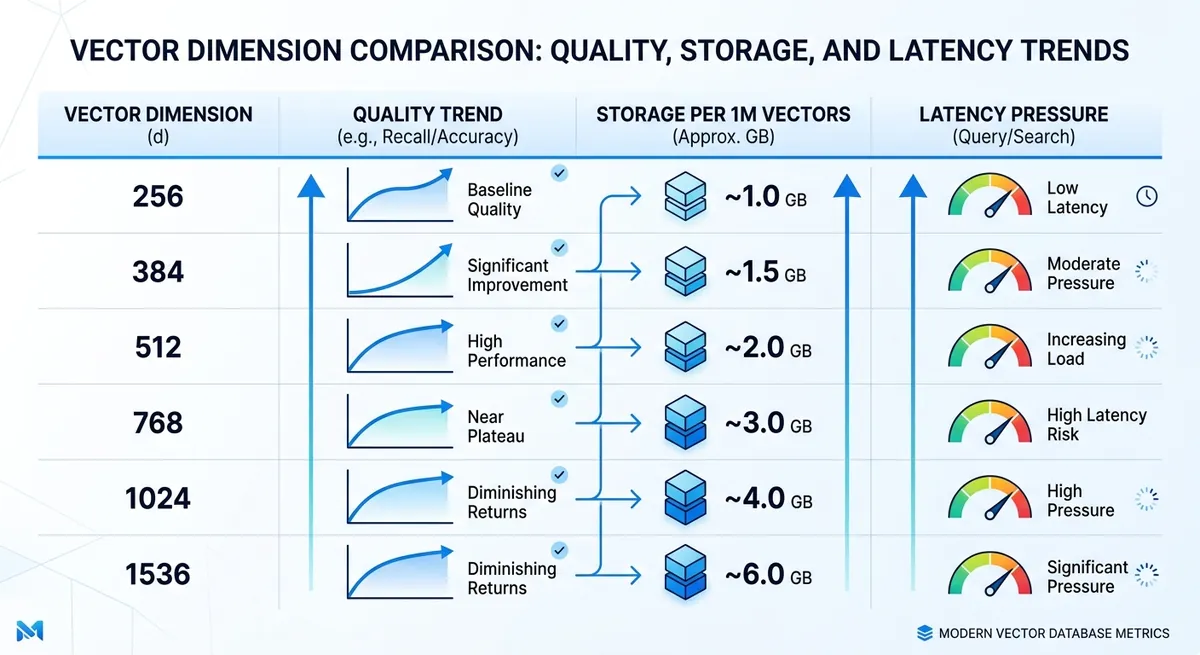
Opsi Dimensi text-embedding-3-small: Rentang Praktis dan Tradeoff#
Untuk text-embedding-3-small, ukuran vektor asli adalah 1536 dimensi. Dalam sistem nyata, tim sering mempersingkat vektor untuk mengurangi RAM, disk, dan beban indeks ANN. Penyimpanan bertambah secara linier dengan jumlah dimensi, jadi setiap pilihan ukuran adalah pilihan biaya dan latensi langsung. Ini adalah inti praktis dari Penjelasan Dimensi text-embedding-3-small.
Penjelasan Dimensi text-embedding-3-small: pengaturan umum dan kasus penggunaan yang paling cocok#
Jika Anda membutuhkan default kasar, tabel ini adalah peta awal yang baik untuk tes A/B.
| Dimensi | Penyimpanan mentah per 1M vektor (float32) | Cocok terbaik | Risiko tipikal |
|---|---|---|---|
| 256 | ~0,95 GB | Batas latensi atau anggaran ketat, pencocokan niat sederhana | Lebih banyak kemiss pada kueri bernuansa |
| 384 | ~1,43 GB | Pencarian semantik fokus biaya dengan teks pendek | Recall lebih rendah pada kasus tepi |
| 512 | ~1,91 GB | Pencarian seimbang untuk dokumen dukungan, bantuan produk, FAQ | Beberapa kehilangan makna ekor panjang |
| 768 | ~2,86 GB | Pengambilan seimbang-plus, gaya kueri campuran | Pertumbuhan biaya infrastruktur sedang |
| 1024 | ~3,81 GB | Recall tinggi RAG atas dokumen padat | Memori indeks lebih tinggi dan waktu kueri |
| 1536 | ~5,72 GB | Pengambilan kesetiaan penuh, kesamaan bernuansa | Tekanan penyimpanan dan latensi tertinggi |
Sumber: rentang dimensi dari garis besar yang disediakan dan informasi model (text-embedding-3-small = 1536). Penyimpanan dihitung sebagai dimensi × 4 bita × 1.000.000 vektor.
Penjelasan tradeoff kualitas text-embedding-3-small: di mana degradasi dimulai#
Kehilangan kualitas biasanya muncul lebih awal pada tugas yang berat presisi. Pengambilan FAQ dapat tetap dapat digunakan pada 384 atau 512, sementara pencarian hukum atau medis sering membutuhkan 1024 atau 1536 untuk mempertahankan perbedaan makna halus.
Campuran bahasa juga mengubah lantai yang aman. Beban kerja bahasa Inggris monoling dapat bertahan pada ukuran yang lebih rendah. Lalu lintas multibahasa, code-switching, dan skrip campuran cenderung menurun lebih cepat ketika vektor menjadi pendek.
Anda dapat menjalankan tes ini dengan cepat melalui Crazyrouter dengan satu kunci API dan membandingkan kualitas pengambilan pada 512, 768, dan 1536 pada kumpulan eval yang sama. Itu memberikan titik cutoff yang terukur daripada dugaan.
Kualitas, Latensi, dan Biaya: Benchmark Tiga Arah yang Benar-benar Anda Butuhkan#
Anda sudah melihat mengapa satu metrik dapat menyesatkan. Untuk Penjelasan Dimensi text-embedding-3-small, langkah praktis adalah menguji satu target relevansi, satu anggaran latensi, dan satu anggaran penyimpanan pada waktu yang sama. Pilih dimensi terkecil yang masih melewati batang kualitas Anda di bawah batas latensi p95 Anda.
Penjelasan kumpulan tes dimensi text-embedding-3-small: bangun relevansi offline yang Anda percayai#
Gunakan log pencarian nyata, tiket dukungan, dan cepat chat. Bangun 200–500 contoh kueri jika Anda bisa. Ukuran itu cukup untuk mengungkap titik lemah tanpa memperlambat tim Anda.
Beri label apa arti "baik" untuk setiap kueri. Jaga label tetap sederhana: relevan, sebagian relevan, tidak relevan. Tambahkan kasus sulit dengan sengaja: kueri pendek, kueri ketik salah, istilah domain, dan kueri multibahasa. Jika aplikasi Anda melayani bahasa campuran, sertakan kueri bahasa campuran dalam kumpulan yang sama.
Jangan biarkan hanya satu orang memberi label hasil. Dua peninjau mengurangi bias dengan cepat.
Penjelasan metrik benchmark dimensi text-embedding-3-small: kualitas dan latensi bersama-sama#
Lacak kualitas peringkat dan kecepatan dalam satu run. Recall@k memberi tahu Anda jika item yang tepat muncul dalam k teratas. MRR dan nDCG memberi tahu Anda jika item itu muncul di dekat atas, di mana pengguna mengklik.
Untuk latensi, pisahkan jalurnya: waktu embedding dan waktu pengambilan. Tonton p95 dan p99, bukan hanya latensi rata-rata. Permintaan ekor lambat membentuk pengalaman pengguna.
| Kandidat dimensi | Ukuran yang diketahui per vektor (float32) | Memori indeks relatif | Metrik kualitas untuk dilacak | Metrik latensi untuk dilacak |
|---|---|---|---|---|
| 1536 (text-embedding-3-small) | 6,144 bita | 1x baseline | Recall@k, MRR, nDCG | Latensi embedding, pengambilan p95/p99 |
| 3072 (text-embedding-3-large) | 12,288 bita | ~2x vs 1536 | Recall@k, MRR, nDCG | Latensi embedding, pengambilan p95/p99 |
| Kandidat dimensi yang lebih rendah di tumpukan Anda | dims × 4 bita | dims / 1536 | Recall@k, MRR, nDCG | Latensi embedding, pengambilan p95/p99 |
Sumber: dimensi model dari daftar model Crazyrouter (text-embedding-3-small: 1536, text-embedding-3-large: 3072). Matematika bita menggunakan vektor float32.
Penjelasan model biaya dimensi text-embedding-3-small: penyimpanan hingga dampak bisnis#
Ubah dimensi menjadi uang sebelum rollout.
Penyimpanan per juta vektor = dimensi × 4 bita × 1.000.000, kemudian kalikan dengan hitungan replika. Tambahkan overhead indeks dari database vektor Anda.
<.-- GAMBAR: Infografis gaya formula untuk memperkirakan penyimpanan vektor dan biaya tahunan berdasarkan dimensi dan ukuran korporus. -->
Sekarang ikat kualitas lift ke sinyal bisnis yang sudah Anda lacak, seperti CTR, penghilangan tiket, atau konversi. Jika dimensi yang lebih besar meningkatkan nDCG sedikit tetapi menggandakan memori dan melewatkan p95, pertahankan pengaturan yang lebih kecil. Jika ini meningkatkan relevansi peringkat cukup untuk menggerakkan konversi, Anda memiliki kasus bisnis yang bersih.
Cara Memilih Dimensi yang Tepat Berdasarkan Kasus Penggunaan#
Jika Anda masih menebak ukuran dimensi, bagian dari Penjelasan Dimensi text-embedding-3-small ini adalah pintasan: petakan dimensi ke beban kerja, kemudian verifikasi dengan kumpulan eval kecil sebelum rollout.
Penjelasan Dimensi text-embedding-3-small untuk RAG dan pencarian perusahaan#
RAG dan pencarian internal gagal cepat ketika recall turun. Pengguna mengajukan satu pertanyaan, kemudian pergi jika hasil teratas melewatkan fakta kunci. Jadi titik awal Anda harus kualitas, bukan penyimpanan.
Gunakan 1536 sebagai baseline untuk text-embedding-3-small, kemudian uji satu ukuran yang lebih rendah hanya setelah Anda mengkonfirmasi recall pada kueri yang sulit. Kueri sulit berarti pertanyaan panjang, istilah langka, dan niat campuran.
Chunking mengubah hasil lebih dari yang orang harapkan. Chunk kecil ditambah dimensi rendah dapat kehilangan konteks dua kali: sekali dalam pemisahan, sekali dalam embedding. Jika chunk Anda pendek, pertahankan dimensi yang lebih tinggi. Jika chunk Anda panjang dan bersih, Anda dapat menguji ukuran yang lebih rendah tanpa risiko buta.
Penjelasan dimensi text-embedding-3-small untuk rekomendasi, pengelompokan, dan perutean semantik#
Sistem ini biasanya peduli dengan kecepatan dan pengelompokan yang stabil, bukan recall top-1 yang sempurna. Pengaturan sedang sering memberikan tradeoff terbaik.
Untuk perutean, kesamaan perkiraan sering cukup karena model tahap kedua dapat me-rerank atau memverifikasi. Itu berarti Anda dapat menguji dimensi yang lebih rendah lebih awal daripada yang Anda lakukan di RAG. Untuk pengelompokan, nilai kemurnian cluster dan drift di seluruh data mingguan, bukan hanya satu run offline.
Pilih dimensi terkecil yang masih menjaga metrik downstream Anda stabil selama dua siklus lalu lintas penuh.
Penjelasan Dimensi text-embedding-3-small untuk beban kerja multibahasa dan khusus domain#
Bahasa domain mengubah permainan. Istilah hukum, medis, atau perangkat keras dapat duduk dekat dalam bahasa biasa tetapi jauh dalam makna. Dimensi yang lebih rendah dapat mengaburkan perbatasan ini.
Lalu lintas multibahasa membutuhkan pemeriksaan per-bahasa. Jangan rata-ratakan semuanya menjadi satu skor. Jalankan kumpulan niat yang sama di seluruh segmen bahasa utama, kemudian bandingkan pola miss. Ukuran yang berfungsi dalam bahasa Inggris dapat gagal pada kueri bahasa campuran atau istilah transliterasi.
| Kasus penggunaan | Dimensi awal yang disarankan | Apa yang diukur sebelum menurunkan | Tanda kegagalan umum |
|---|---|---|---|
| RAG / pencarian perusahaan | 1536 | Recall pada kueri yang sulit, grounding jawaban | Dokumen yang benar tidak dalam hasil teratas |
| Rekomendasi | Sedang (tes di bawah 1536) | Stabilitas CTR atau konversi | Item serupa tetapi tidak relevan naik |
| Perutean semantik | Sedang ke lebih rendah | Akurasi rute + tingkat fallback | Rute yang salah, fallback lebih tinggi |
| Multibahasa / berat domain | 1536 | Recall per-bahasa, kesalahan tingkat istilah | Istilah langka dipetakan ke makna generik |
Sumber: informasi dimensi model dari daftar model Crazyrouter (text-embedding-3-small: 1536, text-embedding-3-large: 3072). <.-- GAMBAR: Matriks keputusan berdasarkan kasus penggunaan (RAG, recsys, routing, multibahasa) dengan dimensi awal yang disarankan. -->
Panduan Implementasi: API, Skema Vektor, dan Langkah Migrasi#
Penjelasan dimensi text-embedding-3-small dalam permintaan API#
Baseline aman untuk text-embedding-3-small adalah 1536 dimensi. Anda dapat meminta ukuran yang lebih kecil dengan bidang dimensions, tetapi jaga ukuran itu tetap di indeks. Jika vektor dokumen menggunakan 1024 dan vektor kueri menggunakan 1536, kualitas pengambilan akan drift bahkan jika kedua panggilan berhasil.
Gunakan satu nilai konfigurasi untuk jalur tulis dan baca, kemudian validasi pada setiap permintaan: teks input tidak kosong, panjang vektor sama dengan dimensi yang dikonfigurasi, dan setiap nilai adalah angka nyata (tidak NaN, tidak Inf). Jika validasi gagal, arahkan item ke antrian percobaan ulang dan re-embed dengan ukuran default Anda.
Anda dapat menggunakan SDK OpenAI dengan endpoint yang kompatibel seperti https://crazyrouter.com/v1, kemudian pin model dan dimensi dalam satu file konfigurasi bersama yang digunakan oleh semua layanan.
Penjelasan kontrol dimensi text-embedding-3-small dalam skema vektor dan desain indeks#
Jaga satu dimensi per indeks, dan jaga vektor kueri dan dokumen di ukuran yang sama.
Gunakan nama koleksi yang terkunci dimensi seperti kb_d1536_v1 dan kb_d1024_v1. Penamaan ini menjaga migrasi dapat dibaca dan mencegah pencampuran diam.
<.-- GAMBAR: Diagram arsitektur yang menunjukkan penyerapan, layanan embedding, indeks vektor ganda, dan router kueri. -->
Ketika dimensionalitas berubah, bangun ulang pengaturan indeks dengan vektor baru. Untuk HNSW, sesuaikan ulang pengaturan grafik dan pencarian setelah pembangunan ulang. Untuk IVF, latih ulang centroid pada vektor dari ukuran dimensi baru. Menggunakan kembali data pelatihan indeks lama dapat merusak recall.
Penjelasan dimensi text-embedding-3-small untuk migrasi dari model yang lebih lama#
Jalankan migrasi dalam fase:
| Fase | Jalur tulis | Jalur baca | Apa yang diperiksa |
|---|---|---|---|
| Dual-write | Embedding lama + baru | Indeks lama | Tingkat keberhasilan tulis dan kesalahan validasi vektor |
| Shadow-read | Embedding lama + baru | Pengguna melihat lama, log baru | Tumpang tindih k teratas, latensi, kasus kueri buruk |
| Cutover | Embedding lama + baru | Indeks baru | Lulus relevansi dan target latensi p95 |
| Rollback | Jaga dual-write aktif | Beralih kembali ke lama | Pemicu pada spike kesalahan atau penurunan relevansi |
Sumber: basis pengetahuan Crazyrouter (text-embedding-3-small pada 1536 dimensi; API kompatibel OpenAI; 300+ model yang didukung).
Ini adalah inti praktis dari Penjelasan Dimensi text-embedding-3-small: kunci dimensi, uji dengan lalu lintas bayangan, dan cutover hanya setelah paritas terukur.
Operasi Produksi: Memonitor Drift, Regresi Kualitas, dan Alur Kerja Tim#
Anda memilih ukuran dimensi dengan tes offline. Awal yang baik. Risiko nyata muncul nanti, setelah konten baru, campuran kueri baru, dan pergeseran peringkat menimpa produksi. Dalam Penjelasan Dimensi text-embedding-3-small, kualitas jangka panjang berasal dari loop yang ketat: data eval yang diperbaiki, pemeriksaan perilaku langsung, dan langkah rollout yang terkontrol.
Siapkan memonitor drift dimensi text-embedding-3-small#
Kunci kumpulan eval dan metrik Anda sebelum setiap perubahan dimensi. Simpan kumpulan kueri emas yang cocok dengan niat pengguna nyata, kemudian beri skor mingguan dengan rubrik yang sama. Pasangkan itu dengan sinyal langsung sehingga Anda menangkap drift lebih awal, bukan setelah tiket dukungan menumpuk.
| Sinyal | Apa drift terlihat seperti | Frekuensi peninjauan | Pemicu tindakan |
|---|---|---|---|
| Skor relevansi kumpulan emas | Hasil teratas berhenti mencocokkan jawaban yang diketahui-baik | Kartu skor mingguan | Jatuh vs run stabil terakhir |
| CTR pada blok pengambilan | Pengguna mengklik lebih sedikit pada dokumen yang disarankan | Setiap hari | Penurunan yang berkelanjutan |
| Tingkat keberhasilan tugas | Lebih banyak sesi gagal menyelesaikan tugas target | Setiap hari | Downtrend menurut segmen |
| Tingkat tanpa hasil | Respons pengambilan kosong meningkat | Setiap hari | Spike setelah deploy |
Sumber tabel: pola runbook operasional yang digunakan dalam bagian ini (kumpulan emas + metrik online dari garis besar yang disediakan).
<.-- GAMBAR: mock dashboard menunjukkan skor kumpulan emas mingguan, tren CTR, tingkat tanpa hasil, dan ambang batas peringatan -->
Jalankan eksperimen dimensi text-embedding-3-small dengan aman di staging dan produksi#
Mulai di staging dengan kueri yang diputar ulang dari 7 hingga 14 hari terakhir. Pindah ke produksi dengan irisan kanari, kemudian perluas menurut segmen pengguna dan wilayah. Jaga rollback siap. Jika kualitas turun, jeda pertumbuhan lalu lintas, beralih ke dimensi stabil terakhir, dan catat jenis kueri mana yang gagal. Ini membuat insiden tetap pendek dan memberikan data bersih untuk tes berikutnya.
Alur kerja tim untuk eksperimen Penjelasan Dimensi text-embedding-3-small#
Evaluasi lintas tim sering rusak karena orang menguji dalam sesi browser campuran. SEO, produk, dan ML dapat menimpa status satu sama lain, kemudian tidak ada yang mempercayai hasilnya. Anda dapat menggunakan profil terisolasi DICloak sehingga setiap peran menguji build yang sama tanpa konflik sesi atau crossover akun.
Alat seperti DICloak memungkinkan Anda menetapkan aturan proxy dan sesi tetap per profil. Itu berarti tes "akun AS-Inggris" dan "akun UE" Anda berjalan dalam kondisi jaringan yang stabil setiap kali. Pengaturan yang dapat direproduksi membuat pemeriksaan peringkat berbasis dimensi lebih mudah untuk dibandingkan di seluruh rekan satu tim, dan itu memberi Anda jalur aman dan dapat diulang untuk pekerjaan Penjelasan Dimensi text-embedding-3-small yang berkelanjutan.
Kesalahan Umum dan Daftar Periksa Pemilihan Dimensi Final#
Jika Anda membaca sejauh ini, Penjelasan Dimensi text-embedding-3-small harus berakhir dalam keputusan peluncuran, bukan tebakan.
Penjelasan kesalahan dimensi text-embedding-3-small yang merusak produksi#
| Kesalahan | Apa yang salah | Apa yang harus dilakukan |
|---|---|---|
| Anda hanya mempercayai skor benchmark vendor | Pencarian terlihat baik dalam tes, tetapi kueri nyata Anda melewatkan niat | Bangun kumpulan eval internal dari kueri pengguna nyata, kemudian beri skor setiap pengaturan dimensi pada kumpulan itu |
| Anda memotong biaya penyimpanan dan melewati pemeriksaan kualitas | Ukuran vektor yang lebih rendah menghemat uang, tetapi kualitas klik turun dan tiket dukungan naik | Lacak kualitas pengambilan dan perilaku pengguna bersama-sama sebelum rollout |
| Anda hanya menguji relevansi | Pengaturan indeks cepat masih bisa gagal target p95 Anda | Ukur latensi end-to-end: embed + pencarian indeks + rerank |
Daftar periksa 10 poin final untuk peluncuran go-live Penjelasan Dimensi text-embedding-3-small#
- Bersihkan duplikat dan teks yang rusak dalam data sumber.
- Tutup kueri kepala, tengah, dan ekor dalam benchmark Anda.
- Bandingkan setidaknya dua ukuran: 1536 (text-embedding-3-small) dan 3072 (text-embedding-3-large).
- Catat relevansi k-teratas untuk setiap ukuran pada kumpulan kueri yang sama.
- Catat latensi p95 dari panggilan API hingga hasil terperingkat final.
- Ubah jumlah dimensi menjadi biaya penyimpanan per juta vektor.
- Jalankan kanari dengan lalu lintas nyata dan metrik keberhasilan.
- Siapkan langkah rollback sebelum rollout penuh.
- Tetapkan satu pemilik untuk pemantauan dan respons peringatan.
- Atur frekuensi review pelatihan ulang atau re-embedding.
Kapal hanya ketika relevansi, latensi p95, dan biaya penyimpanan melewati bersama-sama.
<.-- GAMBAR: Grafik daftar periksa satu halaman untuk keputusan dimensi embedding. -->
Pertanyaan yang Sering Diajukan#
Dalam Penjelasan Dimensi text-embedding-3-small, apa dimensi default terbaik untuk memulai?#
Titik awal praktis adalah 512 untuk sebagian besar tim, atau 1024 jika konten Anda kompleks (hukum, teknis, dokumen bentuk panjang). Dalam Penjelasan Dimensi text-embedding-3-small, ini memberikan keseimbangan kuat antara kualitas, kecepatan, dan biaya tanpa berkomitmen lebih awal. Kemudian jalankan benchmark kecil menggunakan kueri pengguna nyata dan filter yang diharapkan. Pilih dimensi terkecil yang masih memenuhi target relevansi Anda, bukan hanya yang terlihat terbaik dalam tes mainan.
Apakah menurunkan dimensi dalam Penjelasan Dimensi text-embedding-3-small selalu mengurangi kualitas pengambilan?#
Dimensi yang lebih rendah tidak selalu melukai hasil dengan cara yang berarti. Untuk pencarian FAQ pendek atau domain sempit, penurunannya dapat kecil. Untuk katalog luas, konten multibahasa, atau pencocokan semantik bernuansa, kualitas dapat jatuh lebih cepat. Dalam Penjelasan Dimensi text-embedding-3-small, perlakukan dimensi sebagai tombol tuning: bandingkan 256, 512, dan 1024 pada kumpulan kueri yang sama. Jaga ukuran terkecil yang mempertahankan Recall@k yang dapat diterima dan kualitas peringkat untuk pengguna nyata Anda.
Bagaimana dimensi text-embedding-3-small mempengaruhi biaya database vektor?#
Biaya skala kira-kira linier dengan jumlah dimensi. Jika Anda memotong vektor dari 1024 menjadi 512, penyimpanan vektor mentah sekitar setengah. Tren yang sama berlaku untuk penggunaan RAM dan sering menghitung kueri. Tetapi sertakan overhead indeks: struktur ANN menambah memori untuk tautan grafik, metadata, dan pembukuan internal. Jadi total penghematan kuat, tetapi bukan hanya bita vektor. Dalam praktik, perkirakan ukuran indeks penuh, bukan hanya ukuran embedding, sebelum Anda menetapkan dimensi final.
Apakah saya perlu re-embed semua dokumen saat mengubah dimensi?#
Ya. Vektor yang dibangun pada satu dimensi tidak dapat dicampur dengan vektor dari dimensi lain dalam satu indeks yang konsisten. Ketika Anda mengubah dimensi, re-embed semua dokumen dan bangun ulang indeks. Untuk sistem produksi, gunakan migrasi yang lebih aman: jalankan rollout indeks ganda. Bangun indeks baru secara paralel, kirim irisan lalu lintas ke indeks itu, bandingkan kualitas dan latensi, kemudian alihkan sepenuhnya. Ini menghindari waktu henti dan menjaga perilaku pencarian stabil selama transisi.
Metrik mana yang harus saya lacak saat membandingkan dimensi?#
Lacak tiga grup: relevansi, kecepatan, dan biaya. Untuk relevansi, gunakan Recall@k, nDCG, dan MRR pada kumpulan kueri berlabel. Untuk kecepatan, tonton latensi p50/p95/p99, karena latensi ekor mempengaruhi pengalaman pengguna. Untuk biaya, ukur penyimpanan per sejuta dokumen, jejak RAM, dan biaya per 1.000 kueri. Dalam Penjelasan Dimensi text-embedding-3-small, kartu skor ini membantu Anda menghindari pilihan satu sisi di mana Anda menghemat penyimpanan tetapi terlalu banyak melukai kualitas peringkat.
Apakah text-embedding-3-small cocok untuk pencarian multibahasa pada dimensi yang lebih rendah?#
Bisa bekerja, tetapi pencarian multibahasa membutuhkan pengujian yang lebih ketat daripada pencarian satu bahasa. Dimensi yang lebih rendah dapat menggabungkan makna halus di seluruh bahasa, terutama untuk kueri pendek dan skrip campuran. Mulai pada 512 atau 1024, kemudian uji per pasangan bahasa, panjang kueri, dan istilah domain. Dalam Penjelasan Dimensi text-embedding-3-small, pengaturan multibahasa sering mendapat manfaat dari dimensi yang lebih besar ketika presisi penting. Pilih pengaturan terkecil yang masih memenuhi target relevansi untuk setiap segmen bahasa kunci.
Pengambilan inti adalah bahwa dimensi text-embedding-3-small adalah tuas tuning praktis: dimensi yang lebih tinggi dapat meningkatkan kesetiaan semantik, sementara dimensi yang lebih rendah mengurangi penyimpanan, latensi, dan biaya, jadi pilihan yang tepat tergantung pada target kualitas pengambilan Anda dan batasan sistem. Perlakukan ukuran dimensi sebagai keputusan empiris dengan melakukan benchmark recall, kualitas peringkat, dan kinerja end-to-end pada data Anda sendiri daripada mengandalkan default. Uji beberapa dimensi dalam pipeline Anda minggu ini, kemudian kunci pengaturan produksi Anda dengan bukti—bukan dugaan.
Implementation Guides
Available in other languages:





