text-embedding-3-small Wymiary Wyjaśnione: Jak Wybrać Odpowiedni Rozmiar dla Jakości i Kosztów
Praktyczny przewodnik dotyczący wymiarów text-embedding-3-small, jak wybrać między 256, 512, 1024 i 1536 wymiarami.

Wymiary text-embedding-3-small Wyjaśnione: Jak wybrać odpowiedni rozmiar dla jakości, szybkości i kosztów#
Na 1536 wymiarach jeden wektor text-embedding-3-small przechowywany jako float32 zajmuje 6 144 bajty, więc 10 milionów wektorów potrzebuje około 61 GB przed narzutem indeksu. Ta liczba zaskakuje zespoły, gdy wyszukiwanie wydaje się tanie na małą skalę, ale rachunki za pamięć rosną i czas zapytania wzrasta po rozszerzeniu korpusu. Trudna część polega na tym, że wyższe wymiary mogą poprawiać ranking na jednym zestawie danych, ale te same ustawienia mogą marnotrawić pamięć masową i dodać opóźnienie na innym.
To jest sedno Wymiary text-embedding-3-small Wyjaśnione: nie ma uniwersalnego ustawienia, które wygrywa dla każdego obciążenia. Musisz wybrać rozmiar wymiaru, testując razem swój cel relevancji, limit opóźnienia p95 i budżet magazynu wektorów, a nie jeden po drugim. Jeśli tylko dostrojisz jakość, koszt szybko wzrasta. Jeśli tylko zmniejszysz rozmiar, jakość wyszukiwania może się pogorszyć w sposób zauważalny dla użytkowników.
Zobaczysz praktyczną metodę selekcji: zbuduj mały zestaw ewaluacji, porównaj relevancję przy dwóch lub trzech rozmiarach wymiarów, zmierz całkowity czas odpowiedzi oraz przelicz liczbę wymiarów na rzeczywisty koszt magazynowania na milion wektorów. Stąd prawidłowy rozmiar staje się mierzalnym wyborem inżynierskim, a nie zgadywaniem.
Co oznacza "Wymiary" w text-embedding-3-small (i dlaczego to zmienia wyniki)#
Mówiąc jasno, text-embedding-3-small Wymiary Wyjaśnione oznacza jedną rzecz: ile znaczenia zachowujesz w każdym wektorze. Liczba wymiarów to gałka kompresji, a nie przełącznik jakości. text-embedding-3-small ma maksymalny rozmiar 1536 wymiarów (ze specyfikacji modelu w bazie wiedzy). Niższe rozmiary kompresują się bardziej.
text-embedding-3-small wymiary wyjaśnione: znaczenie semantyczne na liczby#
Osadzenie zamienia tekst na liczby, dzięki czemu podobne frazy znajdują się blisko siebie w przestrzeni wektorowej. "Zresetuj moim hasło" i "Nie mogę się zalogować" powinni lądować blisko. Każdy dodatkowy wymiar daje modelowi więcej miejsca do przechowywania niuansów, takich jak intencja, ton lub terminy z domeny. Jeśli zmniejszysz wektor, zachowasz główne znaczenie, ale upuścisz drobniejsze szczegóły.
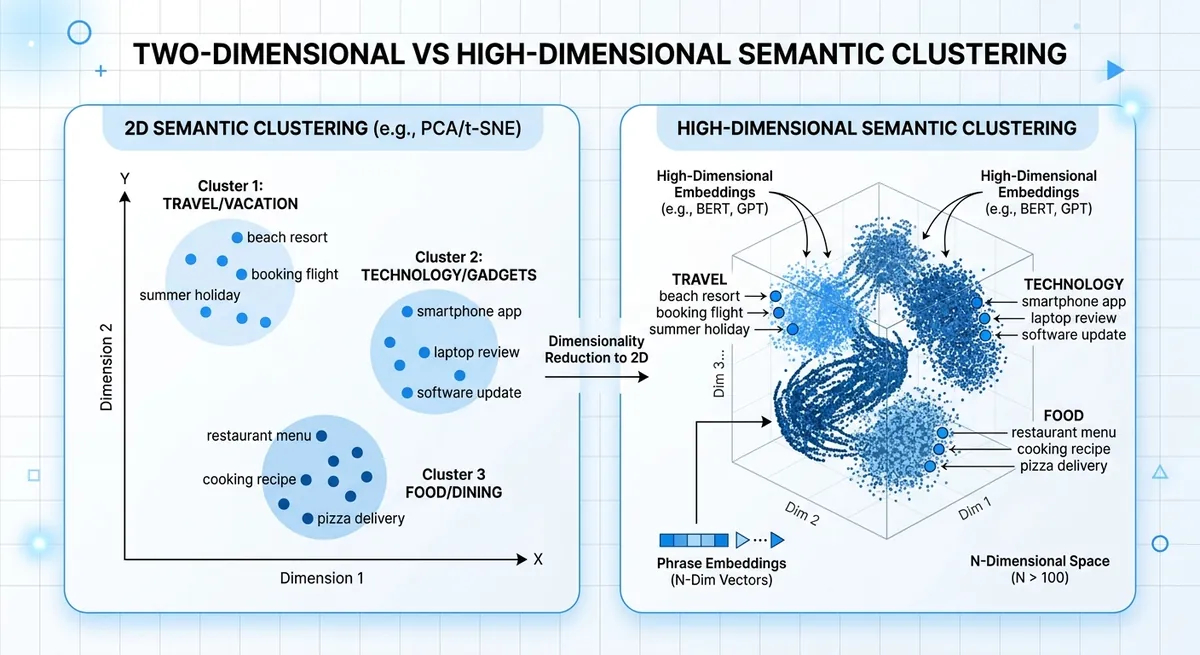
text-embedding-3-small rozmiar wymiaru i zmiany jakości rankingu#
Niższe wymiary mogą przyspieszać wyszukiwanie i zmniejszać pamięć masową, ale ranking najbliższych sąsiadów może się zmienić. Ta zmiana pojawia się, gdy dwie intencje wyglądają podobnie na pierwszy rzut oka, ale różnią się działaniem, takie jak "anuluj plan" vs "wznów plan".
| Wybór rozmiaru wektora | Wierność semantyczna | Szybkość wykonania | Pamięć masowa na 1M wektorów (float32) |
|---|---|---|---|
| 1536 (pełny text-embedding-3-small) | Najwyższa zachowanie szczegółów | Wolniej niż mniejsze wektory | ~6,1 GB |
| 768 (skompresowany) | Pewna strata szczegółów | Szybciej | ~3,1 GB |
| 512 (skompresowany) | Większe ryzyko straty przy zbliżonych intencjach | Jeszcze szybciej | ~2,0 GB |
Źródło: text-embedding-3-small maksymalny wymiar z dostarczonej bazy wiedzy; matematyka magazynu z wymiarów × 4 bajtów.
To jest praktyczne sedno text-embedding-3-small Wymiary Wyjaśnione: dostrojenie wymiarów za pomocą testów relevancji, opóźnienia p95 i magazynu wektorów razem.
Opcje wymiarów text-embedding-3-small: praktyczne zakresy i kompromisy#
W przypadku text-embedding-3-small natywny rozmiar wektora wynosi 1536 wymiarów. W rzeczywistych systemach zespoły często skracają wektory, aby zmniejszyć RAM, dysk i obciążenie indeksu ANN. Pamięć masowa rośnie liniowo z liczbą wymiarów, więc każdy wybór rozmiaru jest bezpośrednim wyborem kosztów i opóźnień. To jest praktyczne sedno text-embedding-3-small Wymiary Wyjaśnione.
text-embedding-3-small Wymiary Wyjaśnione: wspólne ustawienia i przypadki użycia najlepiej dopasowane#
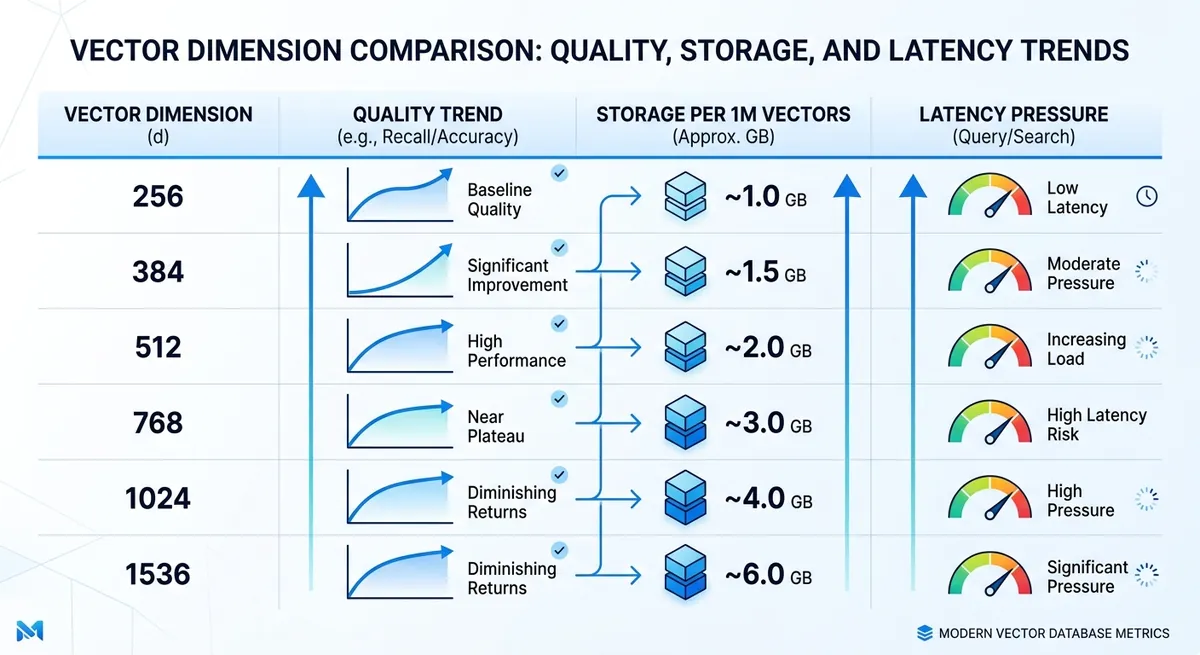
Jeśli potrzebujesz przybliżonych wartości domyślnych, ta tabela jest dobrą mapą startową dla testów A/B.
| Wymiar | Surowa pamięć masowa na 1M wektorów (float32) | Najlepiej dopasowany do | Typowe ryzyko |
|---|---|---|---|
| 256 | ~0,95 GB | Ścisłe limity opóźnień lub budżetu, proste dopasowanie intencji | Więcej braków na zniuansowanych zapytaniach |
| 384 | ~1,43 GB | Wyszukiwanie semantyczne skoncentrowane na kosztach z krótkimi tekstami | Niższy recall na przypadkach granicznych |
| 512 | ~1,91 GB | Zrównoważone wyszukiwanie dokumentów pomocowych, pomocy produktu, FAQ | Pewna strata znaczenia na długim ogonie |
| 768 | ~2,86 GB | Wyszukiwanie zrównoważone plus, mieszane style zapytań | Umiarkowany wzrost kosztów infrastruktury |
| 1024 | ~3,81 GB | Wysoki recall RAG na gęstych dokumentach | Większa pamięć indeksu i czas zapytania |
| 1536 | ~5,72 GB | Wyszukiwanie o pełnej wierności, zniuansowana podobieństwo | Największe ciśnienie magazynu i opóźnień |
Źródło: zakresy wymiarów z dostarczonego szkicu i informacji o modelu (text-embedding-3-small = 1536). Pamięć masowa jest obliczana jako wymiary × 4 bajtów × 1 000 000 wektorów.
text-embedding-3-small kompromisy jakości: gdzie zaczyna się degradacja#
Strata jakości zwykle pojawia się wcześniej w zadaniach wymagających dużej precyzji. Wyszukiwanie FAQ może pozostać przydatne przy 384 lub 512, podczas gdy wyszukiwanie prawne lub medyczne często potrzebuje 1024 lub 1536, aby zachować drobne różnice znaczenia.
Mieszanka języków również zmienia bezpieczną dolną granicę. Monojęzyczne obciążenia w języku angielskim mogą wytrzymać niższe rozmiary. Ruch wielojęzyczny, przełączanie kodu i mieszane skrypty zwykle degradują się szybciej, gdy wektory się skracają.
Możesz uruchomić ten test szybko przez Crazyrouter z jednym kluczem API i porównać jakość wyszukiwania na 512, 768 i 1536 na tym samym zestawie ewaluacji. Daje to mierzalny punkt odcięcia zamiast zgadywania.
Jakość, opóźnienie i koszt: trzystronny benchmark, którego faktycznie potrzebujesz#
Już widziałeś, dlaczego jedna metryka może wprowadzić w błąd. W przypadku text-embedding-3-small Wymiary Wyjaśnione, praktycznym rozwiązaniem jest testowanie jednego celu relevancji, jednego budżetu opóźnienia i jednego budżetu magazynu w tym samym czasie. Wybierz najmniejszy wymiar, który wciąż pokonuje Twój próg jakości w ramach limitu opóźnienia p95.
text-embedding-3-small zestaw testowy wymiarów: offline relevancja, której możesz ufać#
Użyj rzeczywistych dzienników wyszukiwania, zgłoszeń wsparcia i monitów czatu. Zbuduj 200–500 przykładów zapytań, jeśli możesz. Ten rozmiar wystarczy do ujawnienia słabych punktów bez spowolnienia Twojego zespołu.
Oznacz, co "dobre" oznacza dla każdego zapytania. Zachowaj etykiety proste: istotne, częściowo istotne, nieistotne. Dodaj trudne przypadki celowo: krótkie zapytania, zapytania z błędami, terminy z domeny i zapytania wielojęzyczne. Jeśli Twoja aplikacja obsługuje mieszane języki, uwzględnij wielojęzyczne zapytania w tym samym zestawie.
Nie pozwól tylko jednej osobie na etykietowanie wyników. Dwaj recenzenci szybko zmniejszają stronniczość.
text-embedding-3-small wymiary benchmark metryki: jakość i szybkość razem#
Śledź jakość rankingu i szybkość w jednym uruchomieniu. Recall@k mówi Ci, czy prawidłowy element pojawia się w top-k. MRR i nDCG mówią Ci, czy pojawia się blisko szczytu, gdzie użytkownicy klikają.
Na opóźnienie podziel ścieżkę: czas osadzenia i czas wyszukiwania. Obserwuj p95 i p99, a nie tylko przeciętne opóźnienie. Powolne żądania na ogonie kształtują doświadczenie użytkownika.
| Kandydat wymiaru | Znany rozmiar na wektor (float32) | Względna pamięć indeksu | Metryki jakości do śledzenia | Metryki opóźnienia do śledzenia |
|---|---|---|---|---|
| 1536 (text-embedding-3-small) | 6 144 bajtów | 1x linia bazowa | Recall@k, MRR, nDCG | Opóźnienie osadzenia, wyszukiwania p95/p99 |
| 3072 (text-embedding-3-large) | 12 288 bajtów | ~2x vs 1536 | Recall@k, MRR, nDCG | Opóźnienie osadzenia, wyszukiwania p95/p99 |
| Kandydat na niższy wymiar w Twoim stosie | dims × 4 bajty | dims / 1536 | Recall@k, MRR, nDCG | Opóźnienie osadzenia, wyszukiwania p95/p99 |
Źródło: wymiary modelu z listy modeli Crazyrouter (text-embedding-3-small: 1536, text-embedding-3-large: 3072). Matematyka bajtów korzysta z wektorów float32.
text-embedding-3-small model kosztów wymiarów: magazyn do wpływu na biznes#
Przelicz wymiary na pieniądze przed wdrażaniem.
Pamięć masowa na milion wektorów = wymiar × 4 bajty × 1 000 000, a następnie pomnóż przez liczbę replik. Dodaj narzut indeksu z bazy danych wektorów.
<.-- IMAGE: Infografika w stylu formuły do szacowania magazynu wektorów i rocznego kosztu według wymiaru i rozmiaru korpusu. -->
Teraz połącz wzrost jakości z sygnałami biznesowymi, które już śledzisz, takie jak CTR, odrzucanie zgłoszeń lub konwersja. Jeśli większy wymiar podnosi nDCG trochę, ale podwaja pamięć i chybia p95, zachowaj mniejsze ustawienie. Jeśli podnosi ranking relevancji wystarczająco, aby przesunąć konwersję, masz czysty przypadek biznesowy.
Jak wybrać właściwy wymiar według przypadku użycia#
Jeśli wciąż zgadujesz rozmiar wymiaru, ta część text-embedding-3-small Wymiary Wyjaśnione to skrót: mapuj wymiar na obciążenie, a następnie sprawdź za pomocą małego zestawu ewaluacji przed wdrażaniem.
text-embedding-3-small Wymiary Wyjaśnione dla RAG i wyszukiwania przedsiębiorstwa#
RAG i wewnętrzne wyszukiwanie szybko się nie powodzą, gdy recall spada. Użytkownicy zadają jedno pytanie, a następnie się wycofują, jeśli najlepsze wyniki nie uwzględniają kluczowych faktów. Twój punkt wyjścia powinien być jakością, a nie pamięcią masową.
Użyj 1536 jako linii bazowej dla text-embedding-3-small, a następnie testuj tylko jeden niższy rozmiar po potwierdzeniu recall na trudnych zapytaniach. Trudne zapytania oznaczają długie pytania, rzadkie terminy i mieszaną intencję.
Fragmentacja zmienia wynik bardziej niż się ludzie spodziewają. Małe fragmenty plus niskie wymiary mogą tracić kontekst dwukrotnie: raz przy dzieleniu, raz przy osadzeniu. Jeśli Twoje fragmenty są krótkie, zachowaj wyższe wymiary. Jeśli Twoje fragmenty są długie i czyste, możesz testować mniejszy rozmiar bez ślepego ryzyka.
text-embedding-3-small wymiary do rekomendacji, grupowania i semantycznego routingu#
Te systemy zwykle dbają o szybkość i stabilne grupowanie, a nie doskonały recall top-1. Średnie ustawienie często daje najlepszy kompromis.
W przypadku routingu przybliżona podobieństwo jest często wystarczająca, ponieważ model drugiego etapu może zmienić ranking lub zweryfikować. To oznacza, że możesz testować niższe wymiary wcześniej niż w RAG. W przypadku grupowania oceniaj czystość klastra i dryf w ciągu pełnych tygodni danych, a nie tylko jednego offline run.
Wybierz najmniejszy wymiar, który wciąż utrzymuje Twoją metrykę downstream stabilną przez dwa pełne cykle ruchu.
text-embedding-3-small Wymiary Wyjaśnione dla obciążeń wielojęzycznych i specyficznych dla domeny#
Język domeny zmienia grę. Terminy prawne, medyczne lub sprzętowe mogą siedzieć blisko w zwykłym języku, ale daleko w znaczeniu. Niższe wymiary mogą zamazać te granice.
Ruch wielojęzyczny potrzebuje kontroli dla każdego języka. Nie uśredniaj wszystkiego w jeden wynik. Uruchom ten sam zestaw intencji przez każdy główny segment języka, a następnie porównaj wzorce braków. Rozmiar, który działa w angielskim, może nie działać w zapytaniach wielojęzycznych lub transliterowanych terminach.
| Przypadek użycia | Rekomendowany wymiar startowy | Co zmierzyć przed obniżeniem | Typowy znak niepowodzenia |
|---|---|---|---|
| RAG / wyszukiwanie przedsiębiorstwa | 1536 | Recall na trudnych zapytaniach, ugruntowanie odpowiedzi | Właściwy dokument nie w najlepszych wynikach |
| Rekomendacje | Średni (testuj poniżej 1536) | Stabilność CTR lub konwersji | Podobne, ale nieistotne elementy wzrastają |
| Routing semantyczny | Średni do niższy | Dokładność routingu + szybkość fallback | Nieprawidłowy routing, wyższy fallback |
| Wielojęzyczne / obciążone domeną | 1536 | Recall dla każdego języka, błędy na poziomie terminu | Rzadkie terminy mapowane na generyczne znaczenie |
Źródło: informacje o wymiarach modelu z listy modeli Crazyrouter (text-embedding-3-small: 1536, text-embedding-3-large: 3072). <.-- IMAGE: Macierz decyzji według przypadku użycia (RAG, recsys, routing, wielojęzyczne) z rekomendowanymi wymiarami startowymi. -->
Przewodnik wdrażania: API, schemat wektora i kroki migracji#
text-embedding-3-small wymiary wyjaśnione w żądaniach API#
Bezpieczną linią bazową dla text-embedding-3-small jest 1536 wymiarów. Możesz zażądać mniejszego rozmiaru za pomocą pola dimensions, ale zachowaj ten rozmiar stały na indeks. Jeśli wektory dokumentów używają 1024, a wektory zapytań używają 1536, jakość wyszukiwania będzie dryfować nawet jeśli oba połączenia się powodzą.
Użyj jednej wartości konfiguracyjnej dla ścieżek zapisu i odczytu, a następnie sprawdzaj na każdym żądaniu: tekst wejściowy nie jest pusty, długość wektora równa się skonfigurowanemu wymiarowi i każda wartość jest liczbą rzeczywistą (bez NaN, bez Inf). Jeśli weryfikacja się nie powiedzie, skieruj element do kolejki ponownych prób i ponownie osadź z domyślnym rozmiarem.
Możesz użyć SDK OpenAI z kompatybilnym punktem końcowym, takim jak https://crazyrouter.com/v1, a następnie przypinać model i wymiary w jednym udostępnionym pliku konfiguracyjnym używanym przez wszystkie usługi.
text-embedding-3-small kontrola wymiarów w schemacie wektora i projekcie indeksu#
Zachowaj jeden wymiar na indeks i przechowuj wektory zapytań i dokumentów w tym samym rozmiarze.
Użyj zablokowanych wymiarami nazw kolekcji, takich jak kb_d1536_v1 i kb_d1024_v1. Ta nomenklatura utrzymuje migracje czytelne i zapobiega cichemu mieszaniu.
<.-- IMAGE: Diagram architektury pokazujący ingestię, usługę osadzania, podwójne indeksy wektorów i router zapytań. -->
Gdy wymiarowość się zmienia, przebuduj ustawienia indeksu z nowymi wektorami. W przypadku HNSW, dostrajaj ustawienia wykresu i wyszukiwania po przebudowie. W przypadku IVF, przeuczaj centroidy na wektorach z nowego rozmiaru wymiaru. Ponowne użycie starych danych szkoleniowych indeksu może pogorszyć recall.
text-embedding-3-small wymiary wyjaśnione dla migracji ze starszych modeli#
Uruchom migrację w fazach:
| Faza | Ścieżka zapisu | Ścieżka odczytu | Co sprawdzić |
|---|---|---|---|
| Podwójny zapis | Stare + nowe osadzenia | Stary indeks | Wskaźnik sukcesu zapisu i błędy weryfikacji wektorów |
| Odczyt w tle | Stare + nowe osadzenia | Użytkownik widzi stare, dzienniki nowe | Nakładanie się top-k, opóźnienie, złe przypadki zapytań |
| Przejście | Stare + nowe osadzenia | Nowy indeks | Przepustowość relevancji i cel opóźnienia p95 |
| Wycofywanie | Zachowaj aktywny podwójny zapis | Przełącz z powrotem na stare | Wyzwolenie na spike błędu lub spadek relevancji |
Źródło: baza wiedzy Crazyrouter (text-embedding-3-small na 1536 wymiarach; API kompatybilne z OpenAI; 300+ obsługiwanych modeli).
To jest praktyczne sedno text-embedding-3-small Wymiary Wyjaśnione: zablokuj wymiary, testuj ruchem w tle i przejdź tylko po potwierdzonym parytetcie.
Operacje produkcyjne: monitorowanie dryfu, regresji jakości i przepływu pracy zespołu#
Wybrałeś rozmiar wymiaru za pomocą testów offline. Dobry początek. Prawdziwe ryzyko pojawia się później, po nowej zawartości, nowej mieszance zapytań i zmianach rankingu w produkcji. W text-embedding-3-small Wymiary Wyjaśnione, długoterminowa jakość pochodzi z ciasnej pętli: stałe dane ewaluacji, kontrole zachowania na żywo i kontrolowane kroki wdrażania.
Ustaw monitorowanie dryu wymiarów text-embedding-3-small#
Zablokuj swój zestaw ewaluacji i metryki przed każdą zmianą wymiaru. Zachowaj złoty zestaw zapytań, który odpowiada rzeczywistej intencji użytkownika, a następnie oceniaj go co tydzień za pomocą tego samego rubryku. Połącz to z sygnałami na żywo, abyś mógł złapać dryf wcześnie, a nie po piętrze biletów wsparcia.
| Sygnał | Jak wygląda dryf | Kadencja przeglądu | Wyzwolenie akcji |
|---|---|---|---|
| Wynik relevancji złotego zestawu | Najlepsze wyniki przestają pasować do znanych dobrych odpowiedzi | Tygodniowa karta wyników | Spadek vs ostatni stabilny run |
| CTR na blokach wyszukiwania | Użytkownicy rzadziej klikają na sugerowane dokumenty | Codziennie | Utrzymywany spadek |
| Wskaźnik sukcesu zadania | Więcej sesji nie kończy się z celem zadania | Codziennie | Spadek trendu według segmentu |
| Wskaźnik bez wyniku | Odpowiedzi przy pustym wyszukiwaniu wzrastają | Codziennie | Spike po wdrażaniu |
Źródło tabeli: wzorzec podręcznika operacyjnego używany w tej sekcji (złoty zestaw + metryki online z dostarczonego zarysu).
<.-- IMAGE: makieta pulpitu pokazująca tygodniowy wynik złotego zestawu, trend CTR, wskaźnik bez wyniku i progi alertów -->
Uruchom eksperymenty wymiarów text-embedding-3-small bezpiecznie w środowisku przejściowym i produkcyjnym#
Zacznij w środowisku przejściowym ze wznowionymi zapytaniami z ostatnich 7 do 14 dni. Przejdź do produkcji ze wstępnym wycinkiem, a następnie rozwinął się przez segment użytkownika i region. Przygotuj wycofywanie. Jeśli jakość spada, wstrzymaj wzrost ruchu, przełącz na ostatni stabilny wymiar i zaloguj które typy zapytań nie powiodły się. Utrzymuje to incydenty krótkie i daje czyste dane dla następnego testu.
Przepływ pracy zespołu dla eksperymentów text-embedding-3-small Wymiary Wyjaśnione#
Ewaluacja międzydzielowa często się robi, ponieważ ludzie testują w mieszanych sesjach przeglądarki. SEO, produkt i ML mogą zastąpić stan drugiego drugiego, a następnie nikt nie ufa wynikowi. Możesz użyć izolowanych profili DICloak, dzięki czemu każda rola testuje tę samą kompilację bez konfliktów sesji lub krzyżowania kont.
Narzędzia takie jak DICloak pozwalają ustawić reguły stałego serwera proxy i sesji dla każdego profilu. Oznacza to, że testy "konta US-English" i "konta EU" działają w stabilnych warunkach sieciowych za każdym razem. Powtarzalna konfiguracja ułatwia porównywanie kontroli rankingu opartej na wymiarach między współpracownikami i daje powtarzalną, bezpieczną ścieżkę do bieżącej pracy text-embedding-3-small Wymiary Wyjaśnione.
Typowe błędy i ostateczna lista kontrolna wyboru wymiarów#
Jeśli doszedłeś tutaj, text-embedding-3-small Wymiary Wyjaśnione powinno skończyć się decyzją uruchomienia, a nie zgadywaniem.
text-embedding-3-small błędy wymiarów, które łamią produkcję#
| Błąd | Co pójdzie nie tak | Co robić |
|---|---|---|
| Ufasz tylko wynikom benchmarku dostawcy | Wyszukiwanie wygląda dobrze w testach, ale Twoje rzeczywiste zapytania brakuje intencji | Zbuduj wewnętrzny zestaw ewaluacji ze rzeczywistych zapytań użytkowników, a następnie oceń każde ustawienie wymiaru na tym zestawie |
| Obniżasz koszt pamięci masowej i pomijasz kontrole jakości | Niższy rozmiar wektora oszczędza pieniądze, ale jakość kliknięć spada i wzrastają bilety wsparcia | Śledź jakość wyszukiwania i zachowanie użytkownika razem przed wdrażaniem |
| Testujesz tylko relevancję | Szybkie ustawienia indeksu mogą nie mieć celu p95 | Zmierz całkowite opóźnienie: osadź + wyszukiwanie indeksu + zmień kolejność |
Ostateczna lista kontrolna 10 punktów dla wdrażania text-embedding-3-small Wymiary Wyjaśnione#
- Wyczyść duplikaty i zepsięty tekst w danych źródłowych.
- Obejmij zapytania head, mid i tail w swoim benchmark.
- Porównaj co najmniej dwa rozmiary: 1536 (text-embedding-3-small) i 3072 (text-embedding-3-large).
- Zapisz relevancję top-k dla każdego rozmiaru na tym samym zestawie zapytań.
- Zapisz opóźnienie p95 od API call do ostatecznego rankingowego wyniku.
- Przelicz liczbę wymiarów na koszt magazynu na milion wektorów.
- Uruchom kanary ze rzeczywistym ruchem i metrykami sukcesu.
- Przygotuj kroki wycofywania przed pełnym wdrażaniem.
- Przydziel jednego właściciela do monitorowania i reagowania na alerty.
- Ustaw recykl przeszkolenia lub ponownego osadzenia.
Wysyłaj tylko wtedy, gdy relevancja, opóźnienie p95 i koszt magazynu razem przejdą.
<.-- IMAGE: Grafika jednowstecznej listy kontrolnej uruchomienia do podejmowania decyzji dotyczących wymiarów osadzenia. -->
Najczęściej zadawane pytania#
W text-embedding-3-small Wymiary Wyjaśnione, jaki jest najlepszy domyślny wymiar na początek?#
Praktycznym punktem wyjścia jest 512 dla większości zespołów, lub 1024 jeśli Twoja zawartość jest złożona (prawnicza, techniczna, dokumenty długoformowe). W text-embedding-3-small Wymiary Wyjaśnione, daje to silną równowagę jakości, szybkości i kosztów bez zbyt wcześnie zawiązywania się. Następnie uruchom mały benchmark używając rzeczywistych zapytań użytkowników i oczekiwanych filtrów. Wybierz najmniejszy wymiar, który wciąż spełnia Twój cel relevancji, a nie tylko ten, który wygląda najlepiej w teście zabawki.
Czy obniżenie wymiarów w text-embedding-3-small Wymiary Wyjaśnione zawsze zmniejsza jakość wyszukiwania?#
Niższe wymiary niekoniecznie szkodzą wynikom w znaczący sposób. W przypadku wyszukiwania krótkich FAQ lub wąskich domen, spadek może być mały. W szerokich katalogach, wielojęzycznej zawartości lub zniuansowanym dopasowaniu semantycznym, jakość może spaść szybciej. W text-embedding-3-small Wymiary Wyjaśnione, traktuj wymiar jako gałkę dostrajającą: porównaj 256, 512 i 1024 na tym samym zestawie zapytań. Zachowaj najmniejszy rozmiar, który zachowuje akceptowalny Recall@k i jakość rankingu dla Twoich rzeczywistych użytkowników.
Jak wymiary text-embedding-3-small wpływają na koszt bazy danych wektorów?#
Koszt skaluje się mniej więcej liniowo z liczbą wymiarów. Jeśli obetniesz wektory z 1024 na 512, surowy magazyn wektorów to około połowy. Ten sam trend ma zastosowanie do użycia pamięci RAM i często obliczenia zapytań. Ale uwzględnij narzut indeksu: struktury ANN dodają pamięć dla łączy wykresu, metadanych i wewnętrznej księgowości. Zatem całkowite oszczędności są silne, ale nie tylko bajtów wektora. W praktyce szacuj pełny rozmiar indeksu, a nie tylko rozmiar osadzenia, zanim ustawisz ostateczny wymiar.
Czy muszę ponownie osadzić wszystkie dokumenty podczas zmieniania wymiarów?#
Tak. Wektor zbudowany w jednym wymiarze nie może być mieszany z wektorami z innego wymiaru w jednym spójnym indeksie. Po zmianie wymiarów, ponownie osadź wszystkie dokumenty i przebuduj indeks. W systemach produkcyjnych użyj bezpieczniejszej migracji: uruchom wdrażanie podwójnego indeksu. Zbuduj nowy indeks równolegle, wyślij plasterek ruchu do niego, porównaj jakość i opóźnienie, a następnie w pełni przełącz. Pozwala to uniknąć przestojów i utrzymać zachowanie wyszukiwania stabilnym podczas przejścia.
Które metryki powinienem śledzić porównując wymiary?#
Śledź trzy grupy: relevancję, szybkość i koszt. Na relevancję, użyj Recall@k, nDCG i MRR na oznaczonym zestawie zapytań. Na szybkość, obserwuj opóźnienie p50/p95/p99, ponieważ opóźnienie ogona wpływa na doświadczenie użytkownika. Na koszt, zmierz pamięć na milion dokumentów, zajętość RAM i koszt na 1000 zapytań. W text-embedding-3-small Wymiary Wyjaśnione, ta karta wyników pomaga Ci uniknąć jednostronnych wyborów, gdzie oszczędzasz pamięć masową, ale zbyt dużo szkodzisz jakości rankingu.
Czy text-embedding-3-small jest odpowiedni dla wyszukiwania wielojęzycznego na niższych wymiarach?#
Może działać, ale wyszukiwanie wielojęzyczne potrzebuje ściślejszego testowania niż wyszukiwanie w jednym języku. Niższe wymiary mogą łączyć subtelne znaczenie między językami, szczególnie w krótkich zapytaniach i mieszanych skryptach. Zacznij od 512 lub 1024, a następnie testuj według pary językowej, długości zapytania i terminów z domeny. W text-embedding-3-small Wymiary Wyjaśnione, ustawienia wielojęzyczne często korzystają z większych wymiarów, gdy precyzja ma znaczenie. Wybierz najmniejszy rozmiar, który wciąż spełnia cele relevancji dla każdego głównego segmentu języka.
Podstawowym wnioskiem jest, że wymiary text-embedding-3-small to praktyczna dźwignia dostrajania: wyższe wymiary mogą poprawiać wierność semantyczną, podczas gdy niższe wymiary zmniejszają pamięć masową, opóźnienie i koszt, więc właściwy wybór zależy od Twoich celów jakości wyszukiwania i ograniczeń systemu. Traktuj rozmiar wymiaru jako decyzję empiryczną poprzez testowanie recall, jakości rankingu i wydajności end-to-end na Twoich własnych danych zamiast polegać na wartościach domyślnych. Testuj wiele wymiarów w Twoim własnym potoku tego tygodnia, a następnie zablokuj ustawienie produkcyjne z dowodami — nie zgadywaniem.
Implementation Guides
Available in other languages:





