text-embedding-3-small Dimensionen erklärt: Wie man die richtige Größe für Qualität und Kosten wählt
Ein praktischer Leitfaden zu text-embedding-3-small Dimensionen, wie man zwischen 256, 512, 1024 und 1536 Dimensionen wählt.

text-embedding-3-small Dimensionen erklärt: Wie man die richtige Größe für Qualität, Geschwindigkeit und Kosten wählt#
Bei 1536 Dimensionen benötigt ein text-embedding-3-small-Vektor, der als float32 gespeichert wird, 6.144 Bytes, sodass 10 Millionen Vektoren etwa 61 GB vor Index-Overhead benötigen. Diese Zahl überrascht Teams, wenn Abruf bei kleinem Maßstab kostengünstig aussieht, dann aber Speicherrechnungen steigen und die Abfragezeit wächst, nachdem der Korpus expandiert. Das Schwierige ist, dass höhere Dimensionen die Rangfolge bei einem Datensatz verbessern können, doch dieselbe Einstellung kann Speicher verschwenden und Latenz auf einem anderen Datensatz hinzufügen.
Das ist der Kern von text-embedding-3-small Dimensionen erklärt: Es gibt keine universelle Einstellung, die bei jedem Workload gewinnt. Sie müssen die Dimensionsgröße wählen, indem Sie Ihr eigenes Relevanzziel, p95-Latenz-Limit und Vector-Storage-Budget zusammen testen, nicht einzeln. Wenn Sie nur auf Qualität abstimmen, steigen die Kosten schnell. Wenn Sie nur die Größe reduzieren, kann die Suchqualität auf Weise sinken, die Nutzer bemerken.
Sie werden eine praktische Auswahlmethode sehen: Erstellen Sie einen kleinen Evaluierungssatz, vergleichen Sie die Relevanz bei zwei oder drei Dimensionsgrößen, messen Sie die End-to-End-Antwortzeit und konvertieren Sie die Dimensionszahl in echte Speicherkosten pro Million Vektoren. Danach wird die richtige Größe zu einer messbaren technischen Entscheidung, nicht zu Raterei.
Was „Dimensionen" in text-embedding-3-small bedeutet (und warum es Ergebnisse verändert)#
In einfachen Worten bedeutet text-embedding-3-small Dimensionen erklärt eines: Wie viel Bedeutung Sie in jedem Vektor behalten. Dimensionszahl ist ein Kompressionsschieber, kein Qualitätsschalter. text-embedding-3-small hat eine maximale Größe von 1536 Dimensionen (aus der Modellspezifikation in der Knowledge Base). Niedrigere Größen komprimieren stärker.
text-embedding-3-small Dimensionen erklärt: semantische Bedeutung für numerische Vektoren#
Ein Embedding konvertiert Text in Zahlen, sodass ähnliche Phrasen nebeneinander im Vektorraum sitzen. „Passwort zurücksetzen" und „Ich kann mich nicht anmelden" sollten sich in der Nähe befinden. Jede zusätzliche Dimension gibt dem Modell mehr Platz zum Speichern von Nuancen wie Absicht, Ton oder Domain-Begriffe. Wenn Sie den Vektor verkleinern, behalten Sie die Kernbedeutung, aber lassen Sie feinere Details fallen.
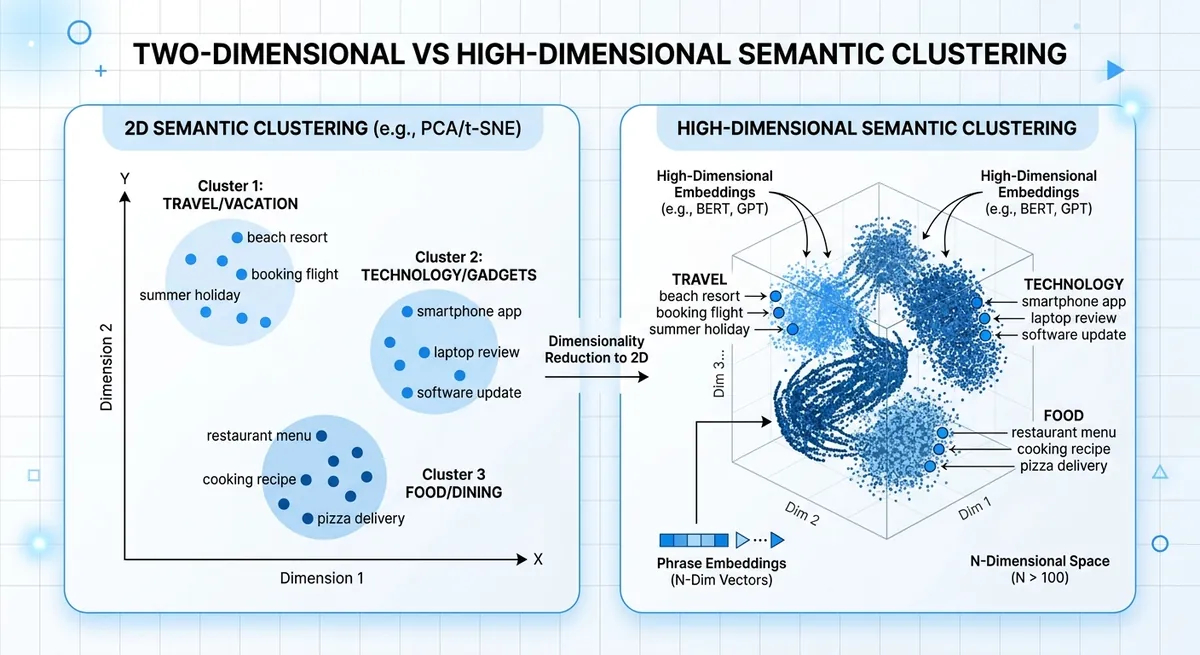
text-embedding-3-small Dimensionsgröße und Änderungen der Rangfolgequalität#
Niedrigere Dimensionen können Suche beschleunigen und Speicher sparen, aber die Nachbar-Rangfolge kann sich verschieben. Diese Verschiebung tritt auf, wenn zwei Absichten oberflächlich ähnlich aussehen, aber sich in der Aktion unterscheiden, wie „Plan kündigen" vs. „Plan pausieren".
| Vektorgröße-Wahl | Semantische Treue | Laufzeit-Geschwindigkeit | Speicher pro 1M Vektoren (float32) |
|---|---|---|---|
| 1536 (vollständiges text-embedding-3-small) | Höchste Detailbeibehaltung | Langsamer als kleinere Vektoren | ~6,1 GB |
| 768 (komprimiert) | Etwas Detailverlust | Schneller | ~3,1 GB |
| 512 (komprimiert) | Höheres Verlustrisiko bei ähnlichen Absichten | Noch schneller | ~2,0 GB |
Quelle: text-embedding-3-small maximale Dimension aus bereitgestellter Knowledge Base; Speicherberechnung aus Dimensionen × 4 Bytes.
Das ist der praktische Kern von text-embedding-3-small Dimensionen erklärt: Stimmen Sie Dimensionen mit Relevanztests, p95-Latenz und Vector-Storage zusammen ab.
text-embedding-3-small Dimensionsoptionen: Praktische Bereiche und Kompromisse#
Für text-embedding-3-small beträgt die native Vektorgröße 1536 Dimensionen. In echten Systemen verkürzen Teams oft Vektoren, um RAM, Festplatte und ANN-Index-Last zu reduzieren. Der Speicher wächst linear mit der Dimensionszahl, daher ist jede Größenwahl eine direkte Kosten- und Latenz-Wahl. Dies ist der praktische Kern von text-embedding-3-small Dimensionen erklärt.
text-embedding-3-small Dimensionen erklärt: gängige Einstellungen und bestgeeignete Anwendungsfälle#
Wenn Sie grobe Standards benötigen, ist diese Tabelle eine gute Startkarte für A/B-Tests.
| Dimension | Rohspeicher pro 1M Vektoren (float32) | Bestgeeignet für | Typisches Risiko |
|---|---|---|---|
| 256 | ~0,95 GB | Enge Latenz- oder Budget-Grenzen, einfaches Absicht-Matching | Mehr Fehler bei nuancierten Abfragen |
| 384 | ~1,43 GB | Kostenfokussierte semantische Suche mit kurzen Texten | Niedrigere Trefferquote bei Sonderfällen |
| 512 | ~1,91 GB | Ausgewogene Suche für Support-Dokumente, Produkthilfe, FAQ | Etwas Bedeutungsverlust für Long-Tail |
| 768 | ~2,86 GB | Ausgewogene Plus-Abfrage, gemischte Abfragestile | Moderater Infrastruktur-Kostenzuwachs |
| 1024 | ~3,81 GB | Hohe Trefferquote RAG über dichte Dokumente | Höhere Index-Memory und Abfragezeit |
| 1536 | ~5,72 GB | Vollständige Abfrage-Treue, nuancierte Ähnlichkeit | Höchster Speicher- und Latenz-Druck |
Quelle: Dimensionsbereiche aus der bereitgestellten Gliederung und Modellinformationen (text-embedding-3-small = 1536). Speicher wird berechnet als Dimensionen × 4 Bytes × 1.000.000 Vektoren.
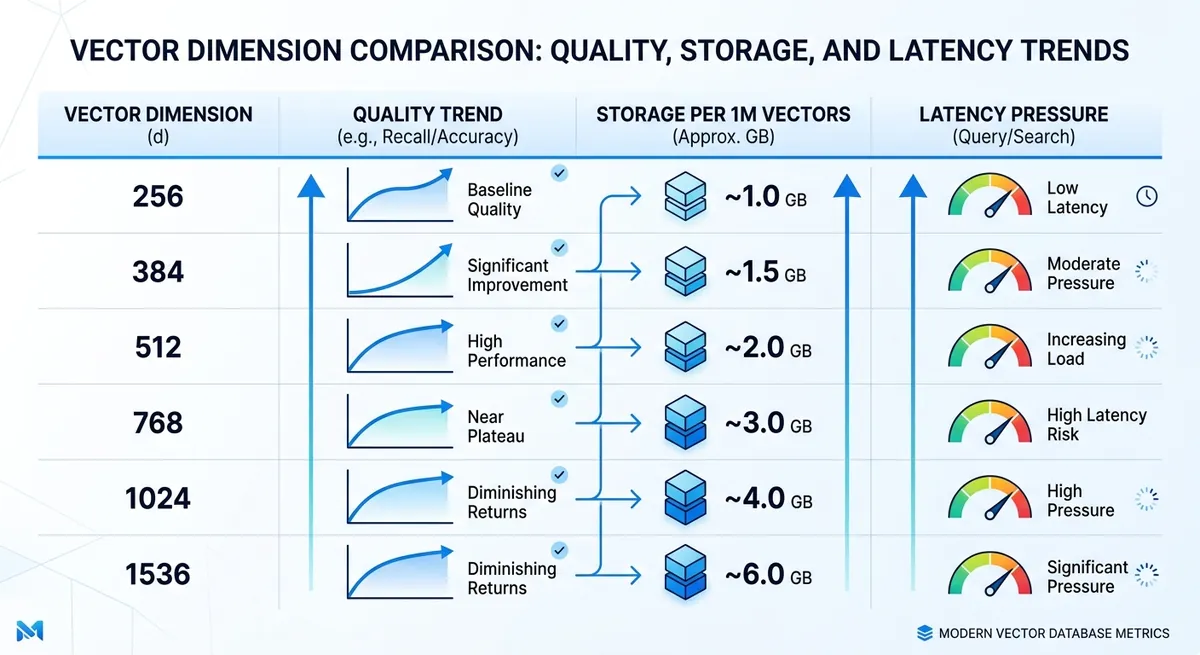
text-embedding-3-small Qualitätskompromisse: wo Abbau beginnt#
Qualitätsverlust tritt normalerweise früher bei präzisionslastigen Aufgaben auf. FAQ-Abfrage kann bei 384 oder 512 brauchbar bleiben, während juristische oder medizinische Suche oft 1024 oder 1536 benötigt, um feine Bedeutungsunterschiede zu bewahren.
Die Sprachmischung ändert auch den sicheren Mindestwert. Einsprachige englische Workloads können bei niedrigeren Größen standhalten. Mehrsprachiger Traffic, Code-Switching und gemischte Schriftsysteme neigen dazu, schneller zu degradieren, wenn Vektoren kurz werden.
Sie können diesen Test schnell durch Crazyrouter mit einem API-Schlüssel durchführen und die Abrufqualität bei 512, 768 und 1536 auf demselben Evaluierungssatz vergleichen. Das gibt einen messbaren Grenzpunkt statt Raterei.
Qualität, Latenz und Kosten: Der dreigliedrige Benchmark, den Sie wirklich brauchen#
Sie haben bereits gesehen, warum eine Metrik täuschen kann. Für text-embedding-3-small Dimensionen erklärt ist der praktische Schritt, ein Relevanzziel, ein Latenz-Budget und ein Speicher-Budget gleichzeitig zu testen. Wählen Sie die kleinste Dimension, die Ihren Qualitätsrichtlinie unter Ihrem p95-Latenz-Limit noch erfüllt.
text-embedding-3-small Dimensionstestsatz: bauen Sie Offline-Relevanz auf, der Sie vertrauen#
Verwenden Sie echte Suchlogs, Support-Tickets und Chat-Prompts. Bauen Sie 200–500 Abfragebeispiele, wenn Sie können. Diese Größe ist ausreichend, um schwache Punkte offenzulegen, ohne Ihr Team zu verlangsamen.
Kennzeichnen Sie, was „gut" für jede Abfrage bedeutet. Halten Sie Etiketten einfach: relevant, teilweise relevant, nicht relevant. Fügen Sie absichtlich schwierige Fälle hinzu: kurze Abfragen, Tippfehler-Abfragen, Domain-Begriffe und mehrsprachige Abfragen. Wenn Ihre App gemischte Sprachen bedient, beziehen Sie mehrsprachige Abfragen in dieselbe Menge ein.
Lassen Sie nicht nur eine Person Ergebnisse kennzeichnen. Zwei Rezensenten reduzieren Verzerrung schnell.
text-embedding-3-small Dimensionen Benchmark-Metriken: Qualität und Latenz zusammen#
Verfolgen Sie Rangfolgequalität und Geschwindigkeit in einer Ausführung. Recall@k teilt Ihnen mit, ob das richtige Element in den Top-k erscheint. MRR und nDCG teilen Ihnen mit, ob es in der Nähe der Spitze erscheint, wo Nutzer klicken.
Für Latenz teilen Sie den Pfad auf: Embedding-Zeit und Abrufzeit. Beobachten Sie p95 und p99, nicht nur durchschnittliche Latenz. Langsame Tail-Anfragen prägen die Nutzererfahrung.
| Dimensions-Kandidat | Bekannte Größe pro Vektor (float32) | Relative Index-Memory | Qualitätsmetriken zum Verfolgen | Latenz-Metriken zum Verfolgen |
|---|---|---|---|---|
| 1536 (text-embedding-3-small) | 6.144 Bytes | 1x Baseline | Recall@k, MRR, nDCG | Embedding-Latenz, Abruf-p95/p99 |
| 3072 (text-embedding-3-large) | 12.288 Bytes | ~2x vs 1536 | Recall@k, MRR, nDCG | Embedding-Latenz, Abruf-p95/p99 |
| Niedrigere-Dimensions-Kandidat in Ihrem Stack | dims × 4 Bytes | dims / 1536 | Recall@k, MRR, nDCG | Embedding-Latenz, Abruf-p95/p99 |
Quelle: Modell-Dimensionen aus Crazyrouter-Modelllist (text-embedding-3-small: 1536, text-embedding-3-large: 3072). Byte-Mathematik verwendet float32-Vektoren.
text-embedding-3-small Dimensions-Kostenmodell: Speicher zu Geschäftsauswirkung#
Konvertieren Sie Dimensionen in Geld vor dem Rollout.
Speicher pro Million Vektoren = Dimension × 4 Bytes × 1.000.000, dann multipliziert mit Replikat-Zahl. Addieren Sie Index-Overhead aus Ihrer Vektordatenbank.
<.-- BILD: Formel-ähnliche Infografik zur Schätzung von Vektor-Speicher und jährlichen Kosten nach Dimension und Korpus-Größe. -->
Verbinden Sie nun Qualitätshub mit Geschäftssignalen, die Sie bereits verfolgen, wie CTR, Ticket-Deflection oder Konversion. Wenn eine größere Dimension nDCG etwas anhebt, aber Speicher verdoppelt und p95 verfehlt, behalten Sie die kleinere Einstellung. Wenn es die rangierte Relevanz genug anhebt, um Konversion zu bewegen, haben Sie einen sauberen Geschäftsfall.
Wie man die richtige Dimension nach Anwendungsfall wählt#
Wenn Sie immer noch die Dimensionsgröße erraten, ist dieser Teil von text-embedding-3-small Dimensionen erklärt der Abkürzung: Ordnen Sie Dimension dem Workload zu, dann überprüfen Sie mit einem kleinen Evaluierungssatz vor dem Rollout.
text-embedding-3-small Dimensionen erklärt für RAG und Enterprise-Suche#
RAG und interne Suche fallen schnell aus, wenn die Trefferquote sinkt. Nutzer stellen eine Frage, dann prellen ab, wenn Top-Ergebnisse wichtige Fakten verfehlen. Daher sollte Ihr Ausgangspunkt Qualität sein, nicht Speicher.
Verwenden Sie 1536 als Baseline für text-embedding-3-small, dann testen Sie nur eine niedrigere Größe, nachdem Sie die Trefferquote bei schwierigen Abfragen bestätigt haben. Schwierige Abfragen bedeuten lange Fragen, seltene Begriffe und gemischte Absicht.
Chunking verändert das Ergebnis mehr als die Leute erwarten. Kleine Chunks plus niedrige Dimensionen können Kontext zweimal verlieren: einmal beim Aufteilen, einmal beim Embedding. Wenn Ihre Chunks kurz sind, behalten Sie höhere Dimensionen. Wenn Ihre Chunks lang und sauber sind, können Sie eine niedrigere Größe ohne blindes Risiko testen.
text-embedding-3-small Dimensionen für Empfehlungen, Clustering und semantisches Routing#
Diese Systeme kümmern sich normalerweise um Geschwindigkeit und stabile Gruppierung, nicht um perfekte Top-1-Trefferquote. Eine mittlere Einstellung bietet oft den besten Kompromiss.
Für Routing ist ungefähre Ähnlichkeit oft ausreichend, da ein Second-Stage-Modell erneut rangieren oder überprüfen kann. Das bedeutet, dass Sie früher als in RAG niedrigere Dimensionen testen können. Für Clustering bewerten Sie Cluster-Reinheit und Drift über wöchentliche Daten, nicht nur eine Offline-Ausführung.
Wählen Sie die kleinste Dimension, die Ihre Downstream-Metrik über zwei vollständige Traffic-Zyklen stabil hält.
text-embedding-3-small Dimensionen erklärt für mehrsprachige und domänenspezifische Workloads#
Domain-Sprache verändert das Spiel. Juristische, medizinische oder Hardware-Begriffe können in Plaintext in der Nähe sitzen, aber weit in der Bedeutung. Niedrigere Dimensionen können diese Grenzen verschwimmen lassen.
Mehrsprachiger Traffic benötigt Pro-Sprache-Überprüfungen. Mitteln Sie nicht alles in einen Wert. Führen Sie denselben Absichtssatz über jedes wichtigste Sprachsegment aus, vergleichen Sie dann Fehlermuster. Eine Größe, die auf Englisch funktioniert, kann bei mehrsprachigen Abfragen oder transliterierten Begriffen fehlschlagen.
| Anwendungsfall | Empfohlene Startdimension | Was vor dem Verringern zu messen ist | Häufiges Fehlerzeichen |
|---|---|---|---|
| RAG / Enterprise-Suche | 1536 | Trefferquote bei schwierigen Abfragen, Antwort-Grundlage | Korrektes Dokument nicht in Top-Ergebnissen |
| Empfehlungen | Mittlere (unterhalb von 1536 testen) | CTR- oder Konversionsstabilität | Ähnliche, aber irrelevante Elemente steigen auf |
| Semantisches Routing | Mittler bis niedriger | Route-Genauigkeit + Fallback-Rate | Falsche Route, höhere Fallback |
| Mehrsprachig / Domain-schwer | 1536 | Pro-Sprache-Trefferquote, Term-Level-Fehler | Seltene Begriffe auf generische Bedeutung abgebildet |
Quelle: Modelldimensionsinformationen aus Crazyrouter-Modelllist (text-embedding-3-small: 1536, text-embedding-3-large: 3072). <.-- BILD: Entscheidungsmatrix nach Anwendungsfall (RAG, Recsys, Routing, Mehrsprachig) mit empfohlenen Startdimensionen. -->
Implementierungsleitfaden: API, Vektorschema und Migrationschritte#
text-embedding-3-small Dimensionen erklärt in API-Anfragen#
Die sichere Baseline für text-embedding-3-small ist 1536 Dimensionen. Sie können eine kleinere Größe mit dem dimensions-Feld anfordern, aber halten Sie diese Größe pro Index fest. Wenn Dokumentvektoren 1024 verwenden und Abfragevektoren 1536 verwenden, wird die Abrufqualität driften, selbst wenn beide Aufrufe erfolgreich sind.
Verwenden Sie einen Konfigurationswert für Schreib- und Lesepfade, dann validieren Sie bei jedem Anfrage: Eingabetext ist nicht leer, Vektorlänge entspricht konfigurierter Dimension und jeder Wert ist eine reelle Zahl (keine NaN, keine Inf). Wenn die Validierung fehlschlägt, leiten Sie das Element an eine Wiederholungs-Warteschlange weiter und embedden Sie erneut mit Ihrer Standard-Größe.
Sie können das OpenAI SDK mit einem kompatiblen Endpunkt wie https://crazyrouter.com/v1 verwenden, dann Model und Dimensionen in einer gemeinsamen Konfigurationsdatei fixieren, die von allen Services verwendet wird.
text-embedding-3-small Dimensions-Kontrolle in Vektorschema und Index-Design#
Halten Sie eine Dimension pro Index und halten Sie Abfrage- und Dokumentvektoren auf diese gleiche Größe.
Verwenden Sie dimensions-gesperrte Sammlungsnamen wie kb_d1536_v1 und kb_d1024_v1. Diese Benennung hält Migrationen lesbar und verhindert stille Vermischung.
<.-- BILD: Architektur-Diagramm mit Aufnahme, Embedding-Service, dualen Vektor-Indexen und Abfrage-Router. -->
Wenn sich die Dimensionalität ändert, bauen Sie Index-Einstellungen mit den neuen Vektoren neu auf. Für HNSW stimmen Sie Graph- und Sucheinstellungen nach dem Neuaufbau neu ab. Für IVF trainieren Sie Zentroide auf Vektoren aus der neuen Dimensionsgröße neu. Die Wiederverwendung alter Index-Trainingsmittel kann die Trefferquote beeinträchtigen.
text-embedding-3-small Dimensionen erklärt für Migration aus älteren Modellen#
Führen Sie die Migration in Phasen aus:
| Phase | Schreibpfad | Lesepfad | Was zu überprüfen ist |
|---|---|---|---|
| Dual-Write | Alte + neue Embeddings | Alter Index | Schreib-Erfolgsrate und Vektor-Validierungsfehler |
| Shadow-Read | Alte + neue Embeddings | Nutzer sieht Alt, protokolliert Neu | Top-k Überlappung, Latenz, schlechte Abfragefälle |
| Cutover | Alte + neue Embeddings | Neuer Index | Relevanz-Erfolgsrate und p95-Latenz-Target |
| Rollback | Dual-Write bleiben aktiv | Zurück zum Alten wechseln | Auslöser bei Fehler-Spitze oder Relevanz-Tropfen |
Quelle: Crazyrouter Knowledge Base (text-embedding-3-small bei 1536 Dimensionen; OpenAI-kompatible API; 300+ unterstützte Modelle).
Dies ist der praktische Kern von text-embedding-3-small Dimensionen erklärt: Sperren Sie Dimensionen, testen Sie mit Shadow-Traffic und schneiden Sie nur über, nachdem gemessene Parität erfolgt.
Produktionsbetrieb: Überwachung von Drift, Qualitätsrückgängen und Team-Workflow#
Sie haben eine Dimensionsgröße mit Offline-Tests ausgewählt. Guter Start. Das echte Risiko taucht später auf, nachdem neuer Inhalt, neue Abfragemischung und Ranking-Verschiebungen die Produktion treffen. In text-embedding-3-small Dimensionen erklärt kommt Langzeitqualität aus einer strammen Schleife: feste Evaluierungsdaten, Live-Verhaltens-Überprüfungen und kontrollierte Rollout-Schritte.
Richten Sie text-embedding-3-small Dimensions-Drift-Überwachung ein#
Sperren Sie Ihren Evaluierungssatz und Metriken vor jeder Dimensionsänderung. Halten Sie einen goldenen Abfragesatz, der echte Benutzerabsicht entspricht, dann punkten Sie ihn wöchentlich mit der gleichen Rubrik. Koppeln Sie das mit Live-Signalen, sodass Sie Drift früh erkennen, nicht nachdem Support-Tickets sich ansammeln.
| Signal | Wie Drift aussieht | Überprüfungs-Kadenz | Aktions-Auslöser |
|---|---|---|---|
| Goldene Set-Relevanzscore | Top-Ergebnisse stoppen, bekannt gute Antworten zu entsprechen | Wöchentliche Scorecard | Tropfen vs letzter stabiler Ausführung |
| CTR auf Abruf-Blöcken | Nutzer klicken weniger auf vorgeschlagene Dokumente | Täglich | Anhaltender Rückgang |
| Task-Erfolgsrate | Mehr Sessions scheitern, Ziel-Task zu beenden | Täglich | Abwärtstrend nach Segment |
| No-Result-Rate | Leere Abruf-Antworten steigen | Täglich | Spitze nach Deploy |
Tabellen-Quelle: Betriebsleitfaden-Muster, das in diesem Abschnitt verwendet wird (golden set + Online-Metriken aus der bereitgestellten Gliederung).
<.-- BILD: Dashboard-Mock mit wöchentlichem Golden-Set-Score, CTR-Trend, No-Result-Rate und Alert-Schwellwertlinien -->
Führen Sie text-embedding-3-small Dimensions-Experimente sicher in Staging und Produktion durch#
Beginnen Sie in Staging mit wiedergegebenen Abfragen aus den letzten 7 bis 14 Tagen. Wechseln Sie zu Produktion mit einem Canary-Slice, dann expandieren Sie nach Benutzer-Segment und Region. Halten Sie Rollback bereit. Wenn die Qualität sinkt, pausieren Sie Traffic-Wachstum, schalten Sie auf die letzte stabile Dimension um und protokollieren Sie, welche Abfragetypen fehlgeschlagen sind. Dies hält Vorfälle kurz und gibt saubere Daten für den nächsten Test.
Team-Workflow für text-embedding-3-small Dimensionen erklärt Experimente#
Cross-Team-Evaluierung bricht oft, weil Menschen in gemischten Browser-Sessions testen. SEO, Produkt und ML können sich gegenseitig Zustand überschreiben, dann vertraut niemand dem Ergebnis. Sie können DICloak isolierte Profile verwenden, sodass jede Rolle denselben Build ohne Session-Konflikte oder Account-Crossover testet.
Tools wie DICloak lassen Sie pro Profil feste Proxy- und Session-Regeln einstellen. Das bedeutet, dass Ihre „US-English-Account" und „EU-Account"-Tests unter stabilen Netzwerkbedingungen jedes Mal laufen. Reproduzierbare Einrichtung macht Dimensionen-basierte Rangfolge-Überprüfungen einfacher, um über Teamkollegen zu vergleichen, und gibt Ihnen einen wiederholbaren, sicheren Pfad für fortlaufende text-embedding-3-small Dimensionen erklärt-Arbeit.
Häufige Fehler und eine abschließende Dimensions-Auswahlcheckliste#
Wenn Sie bis hierhin gelesen haben, sollte text-embedding-3-small Dimensionen erklärt in einer Launch-Entscheidung enden, nicht in einer Vermutung.
text-embedding-3-small Dimensions-Fehler, die Produktion unterbrechen#
| Fehler | Was schiefgeht | Was zu tun ist |
|---|---|---|
| Sie verlassen sich nur auf Anbieter-Benchmark-Werte | Suche sieht in Tests gut aus, aber Ihre echten Abfragen verfehlen Absicht | Bauen Sie einen internen Evaluierungssatz aus echten Benutzerabfragen auf, dann punkten Sie jede Dimensions-Einstellung auf diesem Satz |
| Sie schneiden Speicherkosten und überspringen Qualitäts-Überprüfungen | Kleinere Vektorgröße spart Geld, aber Click-Qualität sinkt und Support-Tickets steigen | Verfolgen Sie Abruf-Qualität und Nutzerverhalten zusammen vor dem Rollout |
| Sie testen nur Relevanz | Fast Index-Einstellungen können immer noch Ihr p95-Target verfehlen | Messen Sie End-to-End-Latenz: Embed + Index-Suche + Rerank |
Abschließende 10-Punkt-Checkliste für text-embedding-3-small Dimensionen erklärt Go-Live#
- Bereinigen Sie Duplikate und fehlerhafte Texte in Quelldaten.
- Decken Sie Head-, Mid- und Tail-Abfragen in Ihrer Benchmark ab.
- Vergleichen Sie mindestens zwei Größen: 1536 (text-embedding-3-small) und 3072 (text-embedding-3-large).
- Zeichnen Sie Top-k-Relevanz für jede Größe auf demselben Abfragesatz auf.
- Zeichnen Sie p95-Latenz vom API-Aufruf bis zum endgültigen rankierten Ergebnis auf.
- Konvertieren Sie Dimensionszahl in Speicherkosten pro Million Vektoren.
- Führen Sie eine Canary mit echtem Traffic und Erfolgsmetriken aus.
- Bereiten Sie Rollback-Schritte vor vollständigem Rollout vor.
- Weisen Sie einen Besitzer für Überwachung und Alert-Antwort zu.
- Stellen Sie eine Neutrainings- oder Neu-Embeddings-Überprüfungs-Kadenz ein.
Versenden Sie nur, wenn Relevanz, p95-Latenz und Speicherkosten zusammen bestanden sind.
<.-- BILD: Einseitige Launch-Checklisten-Grafik für Embedding-Dimensionsentscheidungen. -->
Häufig gestellte Fragen#
In text-embedding-3-small Dimensionen erklärt, welche ist die beste Standard-Dimension zum Starten?#
Ein praktischer Ausgangspunkt ist 512 für die meisten Teams oder 1024, wenn Ihr Inhalt komplex ist (juristische, technische, Long-Form-Dokumente). In text-embedding-3-small Dimensionen erklärt ergibt dies ein starkes Gleichgewicht aus Qualität, Geschwindigkeit und Kosten, ohne früh zu viel zu investieren. Führen Sie dann einen kleinen Benchmark unter Verwendung Ihrer echten Benutzerabfragen und erwarteten Filter aus. Wählen Sie die kleinste Dimension, die Ihr Relevanzziel immer noch erfüllt, nicht nur diejenige, die in einem Spielzeug-Test am besten aussieht.
Reduziert das Senken von Dimensionen in text-embedding-3-small Dimensionen erklärt immer die Abruf-Qualität?#
Niedrigere Dimensionen schaden den Ergebnissen nicht immer auf aussagekräftige Weise. Für kurze FAQ-Suche oder enge Domänen kann der Tropfen klein sein. Für breite Kataloge, mehrsprachigen Inhalt oder nuancierte semantische Übereinstimmung kann die Qualität schneller fallen. In text-embedding-3-small Dimensionen erklärt behandeln Sie Dimension als Abstimmungsknopf: Vergleichen Sie 256, 512 und 1024 auf demselben Abfragesatz. Behalten Sie die kleinste Größe, die akzeptable Recall@k und Ranking-Qualität für Ihre echten Nutzer bewahrt.
Wie beeinflussen text-embedding-3-small Dimensionen die Vektordatenbank-Kosten?#
Die Kosten skalieren ungefähr linear mit der Dimensionszahl. Wenn Sie Vektoren von 1024 auf 512 reduzieren, ist der Rohvektor-Speicher etwa halb so groß. Der gleiche Trend gilt für RAM-Nutzung und oft Abfrage-Compute. Aber beziehen Sie Index-Overhead ein: ANN-Strukturen addieren Memory für Graph-Links, Metadaten und interne Buchführung. Daher sind Gesamteinsparungen stark, aber nicht nur die Vektor-Bytes. Schätzen Sie in der Praxis die Gesamtindex-Größe, nicht nur die Embedding-Größe, bevor Sie eine endgültige Dimension festlegen.
Muss ich alle Dokumente erneut embedden, wenn ich Dimensionen ändere?#
Ja. Ein Vektor, der mit einer Dimension gebaut wurde, kann nicht mit Vektoren aus einer anderen Dimension in einem konsistenten Index gemischt werden. Wenn Sie Dimensionen ändern, embedden Sie alle Dokumente neu und bauen den Index neu auf. Für Produktionssysteme verwenden Sie eine sichere Migration: Führen Sie einen Dual-Index-Rollout durch. Bauen Sie den neuen Index parallel auf, senden Sie einen Traffic-Slice dorthin, vergleichen Sie Qualität und Latenz, dann schalten Sie vollständig um. Dies vermeidet Downtime und hält Such-Verhalten während des Übergangs stabil.
Welche Metriken sollte ich verfolgen, wenn ich Dimensionen vergleiche?#
Verfolgen Sie drei Gruppen: Relevanz, Geschwindigkeit und Kosten. Für Relevanz verwenden Sie Recall@k, nDCG und MRR auf einem kennzeichneten Abfragesatz. Für Geschwindigkeit beobachten Sie p50/p95/p99-Latenz, da Tail-Latenz die Nutzererfahrung prägt. Für Kosten messen Sie Speicher pro Million Dokumente, RAM-Fußabdruck und Kosten pro 1.000 Abfragen. In text-embedding-3-small Dimensionen erklärt hilft Ihnen diese Scorecard, einseitige Wahlmöglichkeiten zu vermeiden, bei denen Sie Speicher sparen, aber Ranking-Qualität zu sehr verletzen.
Eignet sich text-embedding-3-small für mehrsprachige Suche bei niedrigeren Dimensionen?#
Es kann funktionieren, aber mehrsprachige Suche benötigt strengere Tests als einsprachige Suche. Niedrigere Dimensionen können subtile Bedeutung über Sprachen hinweg verschmelzen, besonders bei kurzen Abfragen und gemischten Schriftsystemen. Beginnen Sie bei 512 oder 1024, dann testen Sie nach Sprachenpaar, Abfragelänge und Domain-Begriffen. In text-embedding-3-small Dimensionen erklärt profitieren mehrsprachige Setups oft von größeren Dimensionen, wenn Präzision wichtig ist. Wählen Sie die kleinste Einstellung, die immer noch Relevanzziele für jedes wichtigste Sprachsegment erfüllt.
Die Kernaussage ist, dass text-embedding-3-small-Dimensionen ein praktischer Abstimmungs-Hebel sind: Höhere Dimensionen können semantische Treue verbessern, während niedrigere Dimensionen Speicher, Latenz und Kosten reduzieren, daher hängt die richtige Wahl von Ihren Abruf-Qualitätszielen und System-Einschränkungen ab. Behandeln Sie die Dimensionsgröße als empirische Entscheidung durch Benchmarking von Trefferquote, Ranking-Qualität und End-to-End-Leistung auf Ihren eigenen Daten statt auf Standards zu verlassen. Testen Sie diese Woche mehrere Dimensionen in Ihrer eigenen Pipeline, sperren Sie dann Ihre Produktions-Einstellung mit Evidenz – nicht mit Raterei.
Implementation Guides
Available in other languages:





