Dimensões do text-embedding-3-small Explicadas: Como Escolher o Tamanho Certo para Qualidade e Custo
Um guia prático sobre dimensões do text-embedding-3-small, como escolher entre 256, 512, 1024 e 1536 dimensões.

text-embedding-3-small Dimensões Explicadas: Como Escolher o Tamanho Certo para Qualidade, Velocidade e Custo#
Com 1536 dimensões, um vetor text-embedding-3-small armazenado como float32 usa 6.144 bytes, então 10 milhões de vetores precisam de cerca de 61 GB antes da sobrecarga do índice. Esse número surpreende as equipes quando a recuperação parece barata em pequena escala, mas as contas de memória aumentam e o tempo de consulta cresce após a expansão do corpus. A parte difícil é que dimensões maiores podem melhorar a classificação em um conjunto de dados, mas a mesma configuração pode desperdiçar armazenamento e adicionar latência em outro.
Esse é o cerne de text-embedding-3-small Dimensões Explicadas: não existe uma configuração universal que funcione em todas as cargas de trabalho. Você precisa escolher o tamanho da dimensão testando seu próprio alvo de relevância, limite de latência p95 e orçamento de armazenamento de vetores juntos, não um por um. Se você apenas otimizar para qualidade, o custo sobe rapidamente. Se você apenas reduzir o tamanho, a qualidade da busca pode cair de formas que os usuários notam.
Você verá um método prático de seleção: construir um pequeno conjunto de avaliação, comparar relevância em dois ou três tamanhos de dimensão, medir o tempo de resposta de ponta a ponta e converter a contagem de dimensões em custo real de armazenamento por milhão de vetores. A partir daí, o tamanho certo se torna uma escolha de engenharia mensurável, não adivinhação.
O Que "Dimensões" Significa em text-embedding-3-small (e Por Que Muda os Resultados)#
Em termos simples, text-embedding-3-small Dimensões Explicadas significa uma coisa: quanto significado você mantém em cada vetor. A contagem de dimensões é um botão de compressão, não um interruptor de qualidade. text-embedding-3-small tem um tamanho máximo de 1536 dimensões (da especificação do modelo na base de conhecimento). Tamanhos menores comprimem mais.
text-embedding-3-small dimensões explicadas: significado semântico para vetores numéricos#
Um embedding transforma texto em números para que frases similares fiquem próximas no espaço vetorial. "Redefinir minha senha" e "Não consigo fazer login" devem ficar perto. Cada dimensão extra dá ao modelo mais espaço para armazenar nuances como intenção, tom ou termos de domínio. Se você encolher o vetor, mantém o significado central mas perde detalhes mais finos.
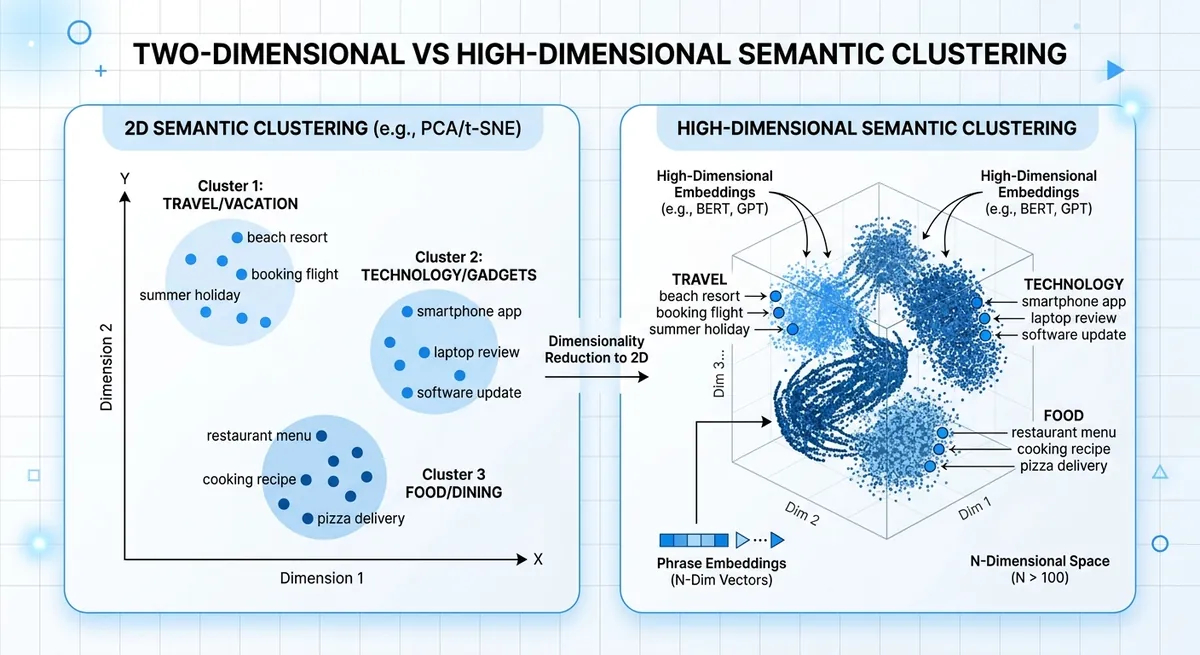
text-embedding-3-small tamanho de dimensão e mudanças na qualidade de classificação#
Dimensões menores podem acelerar a busca e reduzir o armazenamento, mas a classificação de vizinhos mais próximos pode mudar. Essa mudança aparece quando duas intenções parecem similares na superfície mas diferem na ação, como "cancelar plano" vs "pausar plano".
| Escolha de tamanho de vetor | Fidelidade semântica | Velocidade de execução | Armazenamento por 1M vetores (float32) |
|---|---|---|---|
| 1536 (text-embedding-3-small completo) | Retenção de detalhes mais alta | Mais lento que vetores menores | ~6,1 GB |
| 768 (comprimido) | Alguma perda de detalhes | Mais rápido | ~3,1 GB |
| 512 (comprimido) | Mais risco de perda em intenções próximas | Ainda mais rápido | ~2,0 GB |
Fonte: dimensão máxima text-embedding-3-small da base de conhecimento fornecida; matemática de armazenamento de dimensões × 4 bytes.
Esse é o cerne prático de text-embedding-3-small Dimensões Explicadas: ajuste dimensões com testes de relevância, latência p95 e armazenamento de vetores juntos.
Opções de Dimensão text-embedding-3-small: Intervalos Práticos e Tradeoffs#
Para text-embedding-3-small, o tamanho de vetor nativo é 1536 dimensões. Em sistemas reais, as equipes frequentemente encurtam vetores para reduzir RAM, disco e carga de índice ANN. O armazenamento cresce linearmente com a contagem de dimensões, então cada escolha de tamanho é uma escolha direta de custo e latência. Esse é o cerne prático de text-embedding-3-small Dimensões Explicadas.
text-embedding-3-small Dimensões Explicadas: configurações comuns e casos de uso mais adequados#
Se você precisa de padrões aproximados, essa tabela é um bom mapa inicial para testes A/B.
| Dimensão | Armazenamento bruto por 1M vetores (float32) | Melhor para | Risco típico |
|---|---|---|---|
| 256 | ~0,95 GB | Limites de latência ou orçamento apertados, correspondência de intenção simples | Mais falhas em consultas nuançadas |
| 384 | ~1,43 GB | Busca semântica focada em custo com textos curtos | Recall mais baixo em casos extremos |
| 512 | ~1,91 GB | Busca equilibrada para docs de suporte, ajuda de produto, FAQ | Alguma perda de significado de cauda longa |
| 768 | ~2,86 GB | Recuperação equilibrada-plus, estilos de consulta mistos | Crescimento moderado de custo de infraestrutura |
| 1024 | ~3,81 GB | RAG de alto recall sobre docs densos | Maior memória de índice e tempo de consulta |
| 1536 | ~5,72 GB | Recuperação de fidelidade total, similaridade nuançada | Maior pressão de armazenamento e latência |
Fonte: intervalos de dimensão do esboço fornecido e informações do modelo (text-embedding-3-small = 1536). O armazenamento é calculado como dimensões × 4 bytes × 1.000.000 vetores.
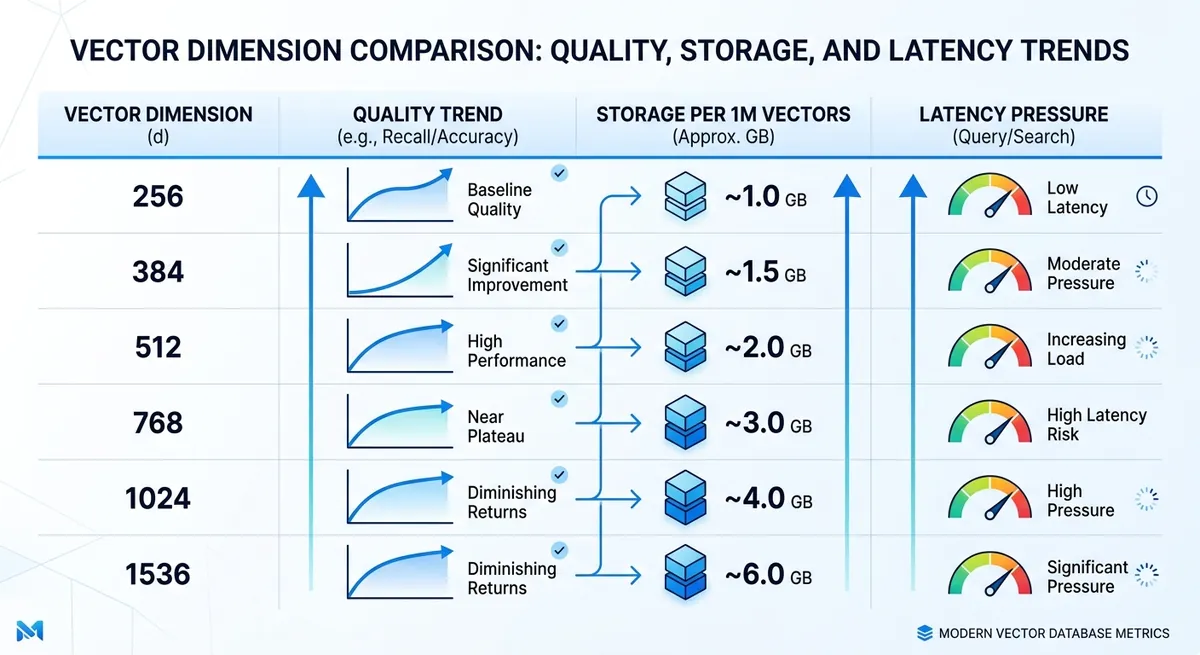
text-embedding-3-small tradeoffs de qualidade: onde a degradação começa#
A perda de qualidade geralmente aparece mais cedo em tarefas com foco em precisão. A recuperação de FAQ pode permanecer utilizável em 384 ou 512, enquanto a busca legal ou médica frequentemente precisa de 1024 ou 1536 para manter diferenças de significado fino.
A mistura de idiomas também muda o piso seguro. Cargas de trabalho monolíngues em inglês podem se manter em tamanhos menores. Tráfego multilíngue, code-switching e scripts mistos tendem a degradar mais cedo quando vetores ficam curtos.
Você pode executar esse teste rapidamente através do Crazyrouter com uma chave de API e comparar qualidade de recuperação em 512, 768 e 1536 no mesmo conjunto de avaliação. Isso fornece um ponto de corte mensurável em vez de adivinhação.
Qualidade, Latência e Custo: O Benchmark Tridimensional Que Você Realmente Precisa#
Você já viu por que uma métrica pode enganar. Para text-embedding-3-small Dimensões Explicadas, o movimento prático é testar um alvo de relevância, um orçamento de latência e um orçamento de armazenamento ao mesmo tempo. Escolha a menor dimensão que ainda atenda sua barra de qualidade sob seu limite de latência p95.
text-embedding-3-small conjunto de teste de dimensão: construir relevância offline em que você confia#
Use logs de busca reais, tickets de suporte e prompts de chat. Construa 200–500 exemplos de consulta se puder. Esse tamanho é suficiente para expor pontos fracos sem desacelerar sua equipe.
Rotule o que "bom" significa para cada consulta. Mantenha rótulos simples: relevante, parcialmente relevante, não relevante. Adicione casos difíceis propositalmente: consultas curtas, consultas com erros de digitação, termos de domínio e consultas multilíngues. Se seu app atende idiomas mistos, inclua consultas em idiomas mistos no mesmo conjunto.
Não deixe apenas uma pessoa rotular resultados. Dois revisores reduzem viés rapidamente.
text-embedding-3-small dimensões métricas de benchmark: qualidade e latência juntas#
Rastreie qualidade de classificação e velocidade em uma execução. Recall@k diz se o item certo aparece nos top-k. MRR e nDCG dizem se aparece perto do topo, onde os usuários clicam.
Para latência, divida o caminho: tempo de embedding e tempo de recuperação. Observe p95 e p99, não apenas latência média. Solicitações de cauda lenta moldam a experiência do usuário.
| Candidato de dimensão | Tamanho conhecido por vetor (float32) | Memória de índice relativa | Métricas de qualidade para rastrear | Métricas de latência para rastrear |
|---|---|---|---|---|
| 1536 (text-embedding-3-small) | 6.144 bytes | 1x baseline | Recall@k, MRR, nDCG | Latência de embedding, recuperação p95/p99 |
| 3072 (text-embedding-3-large) | 12.288 bytes | ~2x vs 1536 | Recall@k, MRR, nDCG | Latência de embedding, recuperação p95/p99 |
| Candidato de dimensão menor em sua stack | dims × 4 bytes | dims / 1536 | Recall@k, MRR, nDCG | Latência de embedding, recuperação p95/p99 |
Fonte: dimensões do modelo da lista de modelos Crazyrouter (text-embedding-3-small: 1536, text-embedding-3-large: 3072). Matemática de bytes usa vetores float32.
text-embedding-3-small modelo de custo de dimensão: armazenamento para impacto nos negócios#
Converta dimensões em dinheiro antes do rollout.
Armazenamento por milhão de vetores = dimensão × 4 bytes × 1.000.000, depois multiplique pela contagem de réplicas. Adicione sobrecarga de índice do seu banco de dados vetorial.
<.-- IMAGE: Infográfico estilo fórmula para estimar armazenamento de vetores e custo anual por dimensão e tamanho de corpus. -->
Agora vincule o aumento de qualidade aos sinais de negócio que você já rastreia, como CTR, deflexão de ticket ou conversão. Se uma dimensão maior aumenta nDCG um pouco mas dobra a memória e perde p95, mantenha a configuração menor. Se aumentar relevância classificada o suficiente para mover conversão, você tem um caso de negócio limpo.
Como Escolher a Dimensão Certa por Caso de Uso#
Se você ainda está adivinhando o tamanho da dimensão, essa parte de text-embedding-3-small Dimensões Explicadas é o atalho: mapeie dimensão para carga de trabalho, depois verifique com um pequeno conjunto de avaliação antes do rollout.
text-embedding-3-small Dimensões Explicadas para RAG e busca corporativa#
RAG e busca interna falham rapidamente quando recall cai. Os usuários fazem uma pergunta, depois saem se os principais resultados perdem fatos-chave. Então seu ponto de partida deve ser qualidade, não armazenamento.
Use 1536 como baseline para text-embedding-3-small, depois teste apenas um tamanho menor após confirmar recall em consultas difíceis. Consultas difíceis significam perguntas longas, termos raros e intenção mista.
Chunking muda o resultado mais do que as pessoas esperam. Chunks pequenos mais dimensões baixas podem perder contexto duas vezes: uma vez na divisão, uma vez no embedding. Se seus chunks são curtos, mantenha dimensões maiores. Se seus chunks são longos e limpos, você pode testar um tamanho menor sem risco cego.
text-embedding-3-small dimensões para recomendações, clustering e roteamento semântico#
Esses sistemas geralmente se importam com velocidade e agrupamento estável, não recall perfeito de top-1. Uma configuração média frequentemente oferece o melhor tradeoff.
Para roteamento, similaridade aproximada é frequentemente suficiente porque um modelo de segundo estágio pode re-classificar ou verificar. Isso significa que você pode testar dimensões menores mais cedo do que faria em RAG. Para clustering, julgue pureza de cluster e drift em dados semanais, não apenas uma execução offline.
Escolha a menor dimensão que ainda mantém sua métrica downstream estável por dois ciclos de tráfego completos.
text-embedding-3-small Dimensões Explicadas para cargas de trabalho multilíngues e específicas de domínio#
Linguagem de domínio muda o jogo. Termos legais, médicos ou de hardware podem ficar próximos em linguagem simples mas longe em significado. Dimensões menores podem borrar essas fronteiras.
Tráfego multilíngue precisa de verificações por idioma. Não calcule média de tudo em um score. Execute o mesmo conjunto de intenção em cada segmento de idioma principal, depois compare padrões de falha. Um tamanho que funciona em inglês pode falhar em consultas multilíngues ou termos transliterados.
| Caso de uso | Dimensão inicial recomendada | O que medir antes de reduzir | Sinal de falha comum |
|---|---|---|---|
| RAG / busca corporativa | 1536 | Recall em consultas difíceis, fundamentação de resposta | Doc correto não nos principais resultados |
| Recomendações | Médio (teste abaixo de 1536) | Estabilidade de CTR ou conversão | Itens similares mas irrelevantes sobem |
| Roteamento semântico | Médio para menor | Precisão de rota + taxa de fallback | Rota errada, fallback mais alto |
| Multilíngue / pesado em domínio | 1536 | Recall por idioma, erros em nível de termo | Termos raros mapeados para significado genérico |
Fonte: informações de dimensão do modelo da lista de modelos Crazyrouter (text-embedding-3-small: 1536, text-embedding-3-large: 3072). <.-- IMAGE: Matriz de decisão por caso de uso (RAG, recsys, roteamento, multilíngue) com dimensões iniciais recomendadas. -->
Guia de Implementação: API, Schema de Vetor e Etapas de Migração#
text-embedding-3-small dimensões explicadas em requisições de API#
O baseline seguro para text-embedding-3-small é 1536 dimensões. Você pode solicitar um tamanho menor com o campo dimensions, mas mantenha esse tamanho fixo por índice. Se vetores de documento usam 1024 e vetores de consulta usam 1536, a qualidade de recuperação vai derivar mesmo se ambas as chamadas forem bem-sucedidas.
Use um valor de config para caminhos de escrita e leitura, depois valide em cada requisição: texto de entrada não está vazio, comprimento do vetor é igual à dimensão configurada e cada valor é um número real (sem NaN, sem Inf). Se a validação falhar, rotule o item para uma fila de retry e re-embed com seu tamanho padrão.
Você pode usar o SDK OpenAI com um endpoint compatível como https://crazyrouter.com/v1, depois fixe modelo e dimensões em um arquivo de config compartilhado usado por todos os serviços.
text-embedding-3-small controle de dimensão em schema de vetor e design de índice#
Mantenha uma dimensão por índice, e mantenha vetores de consulta e documento nesse mesmo tamanho.
Use nomes de coleção bloqueados por dimensão como kb_d1536_v1 e kb_d1024_v1. Essa nomenclatura mantém migrações legíveis e previne mistura silenciosa.
<.-- IMAGE: Diagrama de arquitetura mostrando ingestão, serviço de embedding, índices de vetor duplo e roteador de consulta. -->
Quando a dimensionalidade muda, reconstrua configurações de índice com os novos vetores. Para HNSW, reajuste gráfico e configurações de busca após a reconstrução. Para IVF, retreine centroides em vetores da novo tamanho de dimensão. Reusar dados de treinamento de índice antigo pode prejudicar recall.
text-embedding-3-small dimensões explicadas para migração de modelos mais antigos#
Execute migração em fases:
| Fase | Caminho de escrita | Caminho de leitura | O que verificar |
|---|---|---|---|
| Dual-write | Embeddings antigos + novos | Índice antigo | Taxa de sucesso de escrita e erros de validação de vetor |
| Shadow-read | Embeddings antigos + novos | Usuário vê antigo, registra novo | Sobreposição de top-k, latência, casos de consulta ruim |
| Cutover | Embeddings antigos + novos | Novo índice | Taxa de aprovação de relevância e alvo de latência p95 |
| Rollback | Manter dual-write ativo | Voltar para antigo | Disparar em spike de erro ou queda de relevância |
Fonte: base de conhecimento Crazyrouter (text-embedding-3-small em 1536 dimensões; API compatível com OpenAI; 300+ modelos suportados).
Esse é o cerne prático de text-embedding-3-small Dimensões Explicadas: bloqueie dimensões, teste com tráfego shadow e corte apenas após paridade medida.
Operações em Produção: Monitorando Drift, Regressões de Qualidade e Fluxo de Trabalho da Equipe#
Você escolheu um tamanho de dimensão com testes offline. Bom começo. O risco real aparece depois, após novo conteúdo, nova mistura de consulta e mudanças de classificação atingirem produção. Em text-embedding-3-small Dimensões Explicadas, qualidade de longo prazo vem de um loop apertado: dados de avaliação fixos, verificações de comportamento ao vivo e etapas de rollout controladas.
Configure monitoramento de drift de dimensão text-embedding-3-small#
Bloqueie seu conjunto de avaliação e métricas antes de cada mudança de dimensão. Mantenha um conjunto de consulta dourada que corresponda à intenção real do usuário, depois pontue-o toda semana com a mesma rubrica. Combine isso com sinais ao vivo para pegar drift cedo, não após tickets de suporte se acumularem.
| Sinal | Como drift parece | Cadência de revisão | Gatilho de ação |
|---|---|---|---|
| Pontuação de relevância do conjunto dourado | Principais resultados param de corresponder a respostas conhecidas como boas | Scorecard semanal | Queda vs última execução estável |
| CTR em blocos de recuperação | Usuários clicam menos em docs sugeridos | Diário | Declínio sustentado |
| Taxa de sucesso de tarefa | Mais sessões falham em terminar tarefa alvo | Diário | Tendência de queda por segmento |
| Taxa de sem resultado | Respostas de recuperação vazia aumentam | Diário | Spike após deploy |
Fonte da tabela: padrão de runbook operacional usado nessa seção (conjunto dourado + métricas online do esboço fornecido).
<.-- IMAGE: mock de dashboard mostrando pontuação de conjunto dourado semanal, tendência de CTR, taxa de sem resultado e limites de alerta -->
Execute experimentos de dimensão text-embedding-3-small com segurança em staging e produção#
Comece em staging com consultas repetidas dos últimos 7 a 14 dias. Mude para produção com uma fatia canária, depois expanda por segmento de usuário e região. Mantenha rollback pronto. Se qualidade cair, pause crescimento de tráfego, mude para a última dimensão estável e registre quais tipos de consulta falharam. Isso mantém incidentes curtos e fornece dados limpos para o próximo teste.
Fluxo de trabalho da equipe para experimentos text-embedding-3-small Dimensões Explicadas#
A avaliação entre equipes frequentemente quebra porque as pessoas testam em sessões de navegador misturadas. SEO, produto e ML podem sobrescrever o estado um do outro, depois ninguém confia no resultado. Você pode usar perfis isolados DICloak para que cada função teste a mesma build sem conflitos de sessão ou crossover de conta.
Ferramentas como DICloak deixam você definir regras de proxy e sessão fixas por perfil. Isso significa que seus testes de "conta US-English" e "conta EU" rodam em condições de rede estáveis cada vez. Setup reproduzível torna verificações de classificação baseadas em dimensão mais fáceis de comparar entre colegas de equipe, e fornece um caminho repetível e seguro para trabalho contínuo de text-embedding-3-small Dimensões Explicadas.
Erros Comuns e Checklist Final de Seleção de Dimensão#
Se você leu até aqui, text-embedding-3-small Dimensões Explicadas deve terminar em uma decisão de lançamento, não em uma adivinhação.
Erros de dimensão text-embedding-3-small que quebram produção#
| Erro | O que dá errado | O que fazer |
|---|---|---|
| Você confia apenas em pontuações de benchmark de fornecedor | Busca parece boa em testes, mas suas consultas reais perdem intenção | Construa um conjunto de avaliação interno de consultas reais do usuário, depois pontue cada configuração de dimensão nesse conjunto |
| Você corta custo de armazenamento e pula verificações de qualidade | Tamanho de vetor menor economiza dinheiro, mas qualidade de clique cai e tickets de suporte aumentam | Rastreie qualidade de recuperação e comportamento do usuário juntos antes do rollout |
| Você testa apenas relevância | Configurações de índice rápido ainda podem falhar seu alvo p95 | Meça latência de ponta a ponta: embed + busca de índice + rerank |
Checklist final de 10 pontos para go-live de text-embedding-3-small Dimensões Explicadas#
- Limpe duplicatas e texto quebrado em dados de origem.
- Cubra consultas head, mid e tail em seu benchmark.
- Compare pelo menos dois tamanhos: 1536 (text-embedding-3-small) e 3072 (text-embedding-3-large).
- Registre relevância de top-k para cada tamanho no mesmo conjunto de consulta.
- Registre latência p95 de chamada de API para resultado final classificado.
- Converta contagem de dimensão em custo de armazenamento por milhão de vetores.
- Execute uma canária com tráfego real e métricas de sucesso.
- Prepare etapas de rollback antes do rollout completo.
- Atribua um proprietário para monitoramento e resposta de alerta.
- Defina uma cadência de retreinamento ou re-embedding para revisão.
Implante apenas quando relevância, latência p95 e custo de armazenamento passarem juntos.
<.-- IMAGE: Gráfico de checklist de lançamento de uma página para decisões de dimensão de embedding. -->
Perguntas Frequentes#
Em text-embedding-3-small Dimensões Explicadas, qual é a melhor dimensão padrão para começar?#
Um ponto de partida prático é 512 para a maioria das equipes, ou 1024 se seu conteúdo é complexo (legal, técnico, docs de forma longa). Em text-embedding-3-small Dimensões Explicadas, isso oferece um equilíbrio forte de qualidade, velocidade e custo sem se comprometer cedo. Depois execute um pequeno benchmark usando suas consultas reais do usuário e filtros esperados. Escolha a menor dimensão que ainda atenda seu alvo de relevância, não apenas a que parece melhor em um teste de brinquedo.
Reduzir dimensões em text-embedding-3-small Dimensões Explicadas sempre reduz qualidade de recuperação?#
Dimensões menores não sempre prejudicam resultados de forma significativa. Para busca de FAQ curta ou domínios estreitos, a queda pode ser pequena. Para catálogos amplos, conteúdo multilíngue ou correspondência semântica nuançada, qualidade pode cair mais rápido. Em text-embedding-3-small Dimensões Explicadas, trate dimensão como um botão de ajuste: compare 256, 512 e 1024 no mesmo conjunto de consulta. Mantenha o menor tamanho que preserva Recall@k aceitável e qualidade de classificação para seus usuários reais.
Como dimensões text-embedding-3-small afetam custo de banco de dados vetorial?#
O custo escala aproximadamente linearmente com contagem de dimensão. Se você cortar vetores de 1024 para 512, armazenamento de vetor bruto é cerca de metade. A mesma tendência se aplica a uso de RAM e frequentemente computação de consulta. Mas inclua sobrecarga de índice: estruturas ANN adicionam memória para links de gráfico, metadados e bookkeeping interno. Então economias totais são fortes, mas não apenas bytes de vetor. Na prática, estime tamanho de índice completo, não apenas tamanho de embedding, antes de definir uma dimensão final.
Preciso re-embeddar todos os documentos ao mudar dimensões?#
Sim. Um vetor construído em uma dimensão não pode ser misturado com vetores de outra dimensão em um índice consistente. Quando você muda dimensões, re-embedda todos os documentos e reconstrói o índice. Para sistemas em produção, use uma migração mais segura: execute um rollout de índice duplo. Construa o novo índice em paralelo, envie uma fatia de tráfego para ele, compare qualidade e latência, depois mude completamente. Isso evita downtime e mantém comportamento de busca estável durante transição.
Quais métricas devo rastrear ao comparar dimensões?#
Rastreie três grupos: relevância, velocidade e custo. Para relevância, use Recall@k, nDCG e MRR em um conjunto de consulta rotulado. Para velocidade, observe latência p50/p95/p99, já que latência de cauda afeta experiência do usuário. Para custo, meça armazenamento por milhão de docs, footprint de RAM e custo por 1.000 consultas. Em text-embedding-3-small Dimensões Explicadas, esse scorecard ajuda você a evitar escolhas unilaterais onde você economiza armazenamento mas prejudica qualidade de classificação demais.
text-embedding-3-small é adequado para busca multilíngue em dimensões menores?#
Pode funcionar, mas busca multilíngue precisa de testes mais rigorosos que busca de idioma único. Dimensões menores podem mesclar significado sutil entre idiomas, especialmente para consultas curtas e scripts mistos. Comece em 512 ou 1024, depois teste por par de idioma, comprimento de consulta e termos de domínio. Em text-embedding-3-small Dimensões Explicadas, setups multilíngues frequentemente se beneficiam de dimensões maiores quando precisão importa. Escolha a menor configuração que ainda atenda alvos de relevância para cada segmento de idioma-chave.
O takeaway central é que dimensões text-embedding-3-small são uma alavanca de ajuste prática: dimensões maiores podem melhorar fidelidade semântica, enquanto dimensões menores reduzem armazenamento, latência e custo, então a escolha certa depende de seus alvos de qualidade de recuperação e restrições de sistema. Trate tamanho de dimensão como uma decisão empírica fazendo benchmark de recall, qualidade de classificação e desempenho de ponta a ponta em seus próprios dados em vez de confiar em padrões. Teste múltiplas dimensões em seu próprio pipeline essa semana, depois bloqueie sua configuração de produção com evidência—não adivinhação.
Implementation Guides
Available in other languages:





